













PyTorch經(jīng)驗指南:技巧與陷阱
PyTorch 的構(gòu)建者表明,PyTorch 的哲學(xué)是解決當(dāng)務(wù)之急,也就是說即時構(gòu)建和運行計算圖。目前,PyTorch 也已經(jīng)借助這種即時運行的概念成為最受歡迎的框架之一,開發(fā)者能快速構(gòu)建模型與驗證想法,并通過神經(jīng)網(wǎng)絡(luò)交換格式 ONNX 在多個框架之間快速遷移。本文從基本概念開始介紹了 PyTorch 的使用方法、訓(xùn)練經(jīng)驗與技巧,并展示了可能出現(xiàn)的問題與解決方案。
項目地址:https://github.com/Kaixhin/grokking-pytorch
PyTorch 是一種靈活的深度學(xué)習(xí)框架,它允許通過動態(tài)神經(jīng)網(wǎng)絡(luò)(例如利用動態(tài)控流——如 if 語句或 while 循環(huán)的網(wǎng)絡(luò))進(jìn)行自動微分。它還支持 GPU 加速、分布式訓(xùn)練以及各類優(yōu)化任務(wù),同時還擁有許多更簡潔的特性。以下是作者關(guān)于如何利用 PyTorch 的一些說明,里面雖然沒有包含該庫的所有細(xì)節(jié)或最優(yōu)方法,但可能會對大家有所幫助。
神經(jīng)網(wǎng)絡(luò)是計算圖的一個子類。計算圖接收輸入數(shù)據(jù),數(shù)據(jù)被路由到對數(shù)據(jù)執(zhí)行處理的節(jié)點,并可能被這些節(jié)點轉(zhuǎn)換。在深度學(xué)習(xí)中,神經(jīng)網(wǎng)絡(luò)中的神經(jīng)元(節(jié)點)通常利用參數(shù)或可微函數(shù)轉(zhuǎn)換數(shù)據(jù),這樣可以優(yōu)化參數(shù)以通過梯度下降將損失最小化。更廣泛地說,函數(shù)是隨機(jī)的,圖結(jié)構(gòu)可以是動態(tài)的。所以說,雖然神經(jīng)網(wǎng)絡(luò)可能非常適合數(shù)據(jù)流式編程,但 PyTorch 的 API 卻更關(guān)注命令式編程——一種編程更常考慮的形式。這令讀取代碼和推斷復(fù)雜程序變得簡單,而無需損耗不必要的性能;PyTorch 速度很快,且擁有大量優(yōu)化,作為終端用戶你毫無后顧之憂。
本文其余部分寫的是關(guān)于 grokking PyTorch 的內(nèi)容,都是基于 MINIST 官網(wǎng)實例,應(yīng)該要在學(xué)習(xí)完官網(wǎng)初學(xué)者教程后再查看。為便于閱讀,代碼以塊狀形式呈現(xiàn),并帶有注釋,因此不會像純模塊化代碼一樣被分割成不同的函數(shù)或文件。
Pytorch 基礎(chǔ)
PyTorch 使用一種稱之為 imperative / eager 的范式,即每一行代碼都要求構(gòu)建一個圖,以定義完整計算圖的一個部分。即使完整的計算圖還沒有構(gòu)建好,我們也可以獨立地執(zhí)行這些作為組件的小計算圖,這種動態(tài)計算圖被稱為「define-by-run」方法。
PyTorch 張量
正如 PyTorch 文檔所說,如果我們熟悉 NumPy 的多維數(shù)組,那么 Torch 張量的很多操作我們能輕易地掌握。PyTorch 提供了 CPU 張量和 GPU 張量,并且極大地加速了計算的速度。
從張量的構(gòu)建與運行就能體會,相比 TensorFLow,在 PyTorch 中聲明張量、初始化張量要簡潔地多。例如,使用 torch.Tensor(5, 3) 語句就能隨機(jī)初始化一個 5×3 的二維張量,因為 PyTorch 是一種動態(tài)圖,所以它聲明和真實賦值是同時進(jìn)行的。
在 PyTorch 中,torch.Tensor 是一種多維矩陣,其中每個元素都是單一的數(shù)據(jù)類型,且該構(gòu)造函數(shù)默認(rèn)為 torch.FloatTensor。以下是具體的張量類型:

除了直接定義維度,一般我們還可以從 Python 列表或 NumPy 數(shù)組中創(chuàng)建張量。而且根據(jù)使用 Python 列表和元組等數(shù)據(jù)結(jié)構(gòu)的習(xí)慣,我們可以使用相似的索引方式進(jìn)行取值或賦值。PyTorch 同樣支持廣播(Broadcasting)操作,一般它會隱式地把一個數(shù)組的異常維度調(diào)整到與另一個算子相匹配的維度,以實現(xiàn)維度兼容。
自動微分模塊
TensorFlow、Caffe 和 CNTK 等大多數(shù)框架都使用靜態(tài)計算圖,開發(fā)者必須建立或定義一個神經(jīng)網(wǎng)絡(luò),并重復(fù)使用相同的結(jié)構(gòu)來執(zhí)行模型訓(xùn)練。改變網(wǎng)絡(luò)的模式就意味著我們必須從頭開始設(shè)計并定義相關(guān)的模塊。
但 PyTorch 使用的技術(shù)為自動微分(automatic differentiation)。在這種機(jī)制下,系統(tǒng)會有一個 Recorder 來記錄我們執(zhí)行的運算,然后再反向計算對應(yīng)的梯度。這種技術(shù)在構(gòu)建神經(jīng)網(wǎng)絡(luò)的過程中十分強(qiáng)大,因為我們可以通過計算前向傳播過程中參數(shù)的微分來節(jié)省時間。
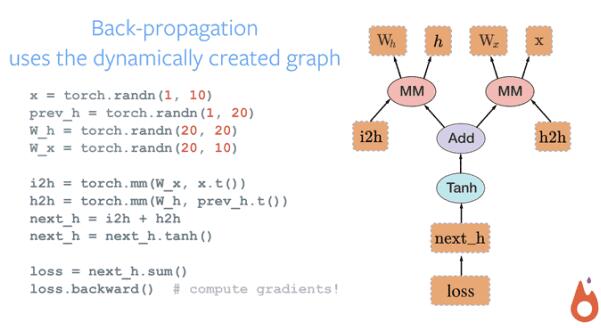
從概念上來說,Autograd 會維護(hù)一個圖并記錄對變量執(zhí)行的所有運算。這會產(chǎn)生一個有向無環(huán)圖,其中葉結(jié)點為輸入向量,根結(jié)點為輸出向量。通過從根結(jié)點到葉結(jié)點追蹤圖的路徑,我們可以輕易地使用鏈?zhǔn)椒▌t自動計算梯度。
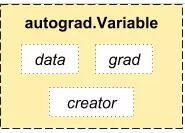
在內(nèi)部,Autograd 將這個圖表征為 Function 對象的圖,并且可以應(yīng)用 apply() 計算評估圖的結(jié)果。在計算前向傳播中,當(dāng) Autograd 在執(zhí)行請求的計算時,它還會同時構(gòu)建一個表征梯度計算的圖,且每個 Variable 的 .grad_fn 屬性就是這個圖的輸入單元。在前向傳播完成后,我們可以在后向傳播中根據(jù)這個動態(tài)圖來計算梯度。
PyTorch 還有很多基礎(chǔ)的模塊,例如控制學(xué)習(xí)過程的最優(yōu)化器、搭建深度模型的神經(jīng)網(wǎng)絡(luò)模塊和數(shù)據(jù)加載與處理等。這一節(jié)展示的張量與自動微分模塊是 PyTorch 最為核心的概念之一,讀者可查閱 PyTorch 文檔了解更詳細(xì)的內(nèi)容。
下面作者以 MNIST 為例從數(shù)據(jù)加載到模型測試具體討論了 PyTorch 的使用、思考技巧與陷阱。
PyTorch 實用指南
1. 導(dǎo)入
- import argparse
- import torch
- from torch import nn, optim
- from torch.nn import functional as F
- from torch.utils.data import DataLoader
- from torchvision import datasets, transforms
除了用于計算機(jī)視覺問題的 torchvision 模塊外,這些都是標(biāo)準(zhǔn)化導(dǎo)入。
2. 設(shè)置
- parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
- parser.add_argument('--batch-size', type=int, default=64, metavar='N',
- help='input batch size for training (default: 64)')
- parser.add_argument('--epochs', type=int, default=10, metavar='N',
- help='number of epochs to train (default: 10)')
- parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
- help='learning rate (default: 0.01)')
- parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
- help='SGD momentum (default: 0.5)')
- parser.add_argument('--no-cuda', action='store_true', default=False,
- help='disables CUDA training')
- parser.add_argument('--seed', type=int, default=1, metavar='S',
- help='random seed (default: 1)')
- parser.add_argument('--save-interval', type=int, default=10, metavar='N',
- help='how many batches to wait before checkpointing')
- parser.add_argument('--resume', action='store_true', default=False,
- help='resume training from checkpoint')
- args = parser.parse_args()
- use_cuda = torch.cuda.is_available() and not args.no_cuda
- device = torch.device('cuda' if use_cuda else 'cpu')
- torch.manual_seed(args.seed)
- if use_cuda:
- torch.cuda.manual_seed(args.seed)
argparse 是在 Python 中處理命令行參數(shù)的一種標(biāo)準(zhǔn)方式。
編寫與設(shè)備無關(guān)的代碼(可用時受益于 GPU 加速,不可用時會倒退回 CPU)時,選擇并保存適當(dāng)?shù)?torch.device, 不失為一種好方法,它可用于確定存儲張量的位置。關(guān)于與設(shè)備無關(guān)代碼的更多內(nèi)容請參閱官網(wǎng)文件。PyTorch 的方法是使用戶能控制設(shè)備,這對簡單示例來說有些麻煩,但是可以更容易地找出張量所在的位置——這對于 a)調(diào)試很有用,并且 b)可有效地使用手動化設(shè)備。
對于可重復(fù)實驗,有必要為使用隨機(jī)數(shù)生成的任何數(shù)據(jù)設(shè)置隨機(jī)種子(如果也使用隨機(jī)數(shù),則包括隨機(jī)或 numpy)。要注意,cuDNN 用的是非確定算法,可以通過語句 torch.backends.cudnn.enabled = False 將其禁用。
3. 數(shù)據(jù)
- train_data = datasets.MNIST('data', train=True, download=True,
- transform=transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize((0.1307,), (0.3081,))]))
- test_data = datasets.MNIST('data', train=False, transform=transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize((0.1307,), (0.3081,))]))
- train_loader = DataLoader(train_data, batch_size=args.batch_size,
- shuffle=True, num_workers=4, pin_memory=True)
- test_loader = DataLoader(test_data, batch_size=args.batch_size,
- num_workers=4, pin_memory=True)
torchvision.transforms 對于單張圖像有非常多便利的轉(zhuǎn)換工具,例如裁剪和歸一化等。
DataLoader 包含非常多的參數(shù),除了 batch_size 和 shuffle,num_workers 和 pin_memory 對于高效加載數(shù)據(jù)同樣非常重要。例如配置 num_workers > 0 將使用子進(jìn)程異步加載數(shù)據(jù),而不是使用一個主進(jìn)程塊加載數(shù)據(jù)。參數(shù) pin_memory 使用固定 RAM 以加速 RAM 到 GPU 的轉(zhuǎn)換,且在僅使用 CPU 時不會做任何運算。
4. 模型
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
- self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
- self.conv2_drop = nn.Dropout2d()
- self.fc1 = nn.Linear(320, 50)
- self.fc2 = nn.Linear(50, 10)
- def forward(self, x):
- x = F.relu(F.max_pool2d(self.conv1(x), 2))
- x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
- xx = x.view(-1, 320)
- x = F.relu(self.fc1(x))
- x = self.fc2(x)
- return F.log_softmax(x, dim=1)
- model = Net().to(device)
- optimoptimiser = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
- if args.resume:
- model.load_state_dict(torch.load('model.pth'))
- optimiser.load_state_dict(torch.load('optimiser.pth'))
神經(jīng)網(wǎng)絡(luò)初始化一般包括變量、包含可訓(xùn)練參數(shù)的層級、可能獨立的可訓(xùn)練參數(shù)和不可訓(xùn)練的緩存器。隨后前向傳播將這些初始化參數(shù)與 F 中的函數(shù)結(jié)合,其中該函數(shù)為不包含參數(shù)的純函數(shù)。有些開發(fā)者喜歡使用完全函數(shù)化的網(wǎng)絡(luò)(如保持所有參數(shù)獨立,使用 F.conv2d 而不是 nn.Conv2d),或者完全由 layers 函數(shù)構(gòu)成的網(wǎng)絡(luò)(如使用 nn.ReLU 而不是 F.relu)。
在將 device 設(shè)置為 GPU 時,.to(device) 是一種將設(shè)備參數(shù)(和緩存器)發(fā)送到 GPU 的便捷方式,且在將 device 設(shè)置為 CPU 時不會做任何處理。在將網(wǎng)絡(luò)參數(shù)傳遞給優(yōu)化器之前,把它們傳遞給適當(dāng)?shù)脑O(shè)備非常重要,不然的話優(yōu)化器不能正確地追蹤參數(shù)。
神經(jīng)網(wǎng)絡(luò)(nn.Module)和優(yōu)化器(optim.Optimizer)都能保存和加載它們的內(nèi)部狀態(tài),而.load_state_dict(state_dict) 是完成這一操作的推薦方法,我們可以從以前保存的狀態(tài)字典中加載兩者的狀態(tài)并恢復(fù)訓(xùn)練。此外,保存整個對象可能會出錯。
這里沒討論的一些注意事項即前向傳播可以使用控制流,例如一個成員變量或數(shù)據(jù)本身能決定 if 語句的執(zhí)行。此外,在前向傳播的過程中打印張量也是可行的,這令 debug 更加簡單。最后,前向傳播可以使用多個參數(shù)。以下使用間斷的代碼塊展示這一點:
- def forward(self, x, hx, drop=False):
- hx2 = self.rnn(x, hx)
- print(hx.mean().item(), hx.var().item())
- if hx.max.item() > 10 or self.can_drop and drop:
- return hx
- else:
- return hx2
5. 訓(xùn)練
- model.train()
- train_losses = []
- for i, (data, target) in enumerate(train_loader):
- data, target = data.to(device), target.to(device)
- optimiser.zero_grad()
- output = model(data)
- loss = F.nll_loss(output, target)
- loss.backward()
- train_losses.append(loss.item())
- optimiser.step()
- if i % 10 == 0:
- print(i, loss.item())
- torch.save(model.state_dict(), 'model.pth')
- torch.save(optimiser.state_dict(), 'optimiser.pth')
- torch.save(train_losses, 'train_losses.pth')
網(wǎng)絡(luò)模塊默認(rèn)設(shè)置為訓(xùn)練模式,這影響了某些模塊的工作方式,最明顯的是 dropout 和批歸一化。最好用.train() 對其進(jìn)行手動設(shè)置,這樣可以把訓(xùn)練標(biāo)記向下傳播到所有子模塊。
在使用 loss.backward() 收集一系列新的梯度以及用 optimiser.step() 做反向傳播之前,有必要手動地將由 optimiser.zero_grad() 優(yōu)化的參數(shù)梯度歸零。默認(rèn)情況下,PyTorch 會累加梯度,在單次迭代中沒有足夠資源來計算所有需要的梯度時,這種做法非常便利。
PyTorch 使用一種基于 tape 的自動化梯度(autograd)系統(tǒng),它收集按順序在張量上執(zhí)行的運算,然后反向重放它們來執(zhí)行反向模式微分。這正是為什么 PyTorch 如此靈活并允許執(zhí)行任意計算圖的原因。如果沒有張量需要做梯度更新(當(dāng)你需要為該過程構(gòu)建一個張量時,你必須設(shè)置 requires_grad=True),則不需要保存任何圖。然而,網(wǎng)絡(luò)傾向于包含需要梯度更新的參數(shù),因此任何網(wǎng)絡(luò)輸出過程中執(zhí)行的計算都將保存在圖中。因此如果想保存在該過程中得到的數(shù)據(jù),你將需要手動禁止梯度更新,或者,更常見的做法是將其保存為一個 Python 數(shù)(通過一個 Python 標(biāo)量上的.item())或者 NumPy 數(shù)組。更多關(guān)于 autograd 的細(xì)節(jié)詳見官網(wǎng)文件。
截取計算圖的一種方式是使用.detach(),當(dāng)通過沿時間的截斷反向傳播訓(xùn)練 RNN 時,數(shù)據(jù)流傳遞到一個隱藏狀態(tài)可能會應(yīng)用這個函數(shù)。當(dāng)對損失函數(shù)求微分(其中一個成分是另一個網(wǎng)絡(luò)的輸出)時,也會很方便。但另一個網(wǎng)絡(luò)不應(yīng)該用「loss - examples」的模式進(jìn)行優(yōu)化,包括在 GAN 訓(xùn)練中從生成器的輸出訓(xùn)練判別器,或使用價值函數(shù)作為基線(例如 A2C)訓(xùn)練 actor-critic 算法的策略。另一種在 GAN 訓(xùn)練(從判別器訓(xùn)練生成器)中能高效阻止梯度計算的方法是在整個網(wǎng)絡(luò)參數(shù)上建立循環(huán),并設(shè)置 param.requires_grad=False,這在微調(diào)中也很常用。
除了在控制臺/日志文件里記錄結(jié)果以外,檢查模型參數(shù)(以及優(yōu)化器狀態(tài))也是很重要的。你還可以使用 torch.save() 來保存一般的 Python 對象,但其它標(biāo)準(zhǔn)選擇還包括內(nèi)建的 pickle。
6. 測試
- model.eval()
- test_loss, correct = 0, 0
- with torch.no_grad():
- for data, target in test_loader:
- data, target = data.to(device), target.to(device)
- output = model(data)
- test_loss += F.nll_loss(output, target, size_average=False).item()
- pred = output.argmax(1, keepdim=True)
- correct += pred.eq(target.view_as(pred)).sum().item()
- test_loss /= len(test_data)
- acc = correct / len(test_data)
- print(acc, test_loss)
為了早點響應(yīng).train(),應(yīng)利用.eval() 將網(wǎng)絡(luò)明確地設(shè)置為評估模式。
正如前文所述,計算圖通常會在使用網(wǎng)絡(luò)時生成。通過 with torch.no_grad() 使用 no_grad 上下文管理器,可以防止這種情況發(fā)生。
7. 其它
內(nèi)存有問題?可以查看官網(wǎng)文件獲取幫助。
CUDA 出錯?它們很難調(diào)試,而且通常是一個邏輯問題,會在 CPU 上產(chǎn)生更易理解的錯誤信息。如果你計劃使用 GPU,那最好能夠在 CPU 和 GPU 之間輕松切換。更普遍的開發(fā)技巧是設(shè)置代碼,以便在啟動合適的項目(例如準(zhǔn)備一個較小/合成的數(shù)據(jù)集、運行一個 train + test epoch 等)之前快速運行所有邏輯來檢查它。如果這是一個 CUDA 錯誤,或者你沒法切換到 CPU,設(shè)置 CUDA_LAUNCH_BLOCKING=1 將使 CUDA 內(nèi)核同步啟動,從而提供更詳細(xì)的錯誤信息。
torch.multiprocessing,甚至只是一次運行多個 PyTorch 腳本的注意事項。因為 PyTorch 使用多線程 BLAS 庫來加速 CPU 上的線性代數(shù)計算,所以它通常需要使用多個內(nèi)核。如果你想一次運行多個任務(wù),在具有多進(jìn)程或多個腳本的情況下,通過將環(huán)境變量 OMP_NUM_THREADS 設(shè)置為 1 或另一個較小的數(shù)字來手動減少線程,這樣做減少了 CPU thrashing 的可能性。官網(wǎng)文件還有一些其它注意事項,尤其是關(guān)于多進(jìn)程。
【本文是51CTO專欄機(jī)構(gòu)“機(jī)器之心”的原創(chuàng)譯文,微信公眾號“機(jī)器之心( id: almosthuman2014)”】














