













Pytorch教程:新手的快速指南
Python被確定為數據科學和機器學習的進入語言,部分感謝開源ML庫Pytorch。
Pytorch的功能強大的深度神經網絡建筑工具和易用性使其成為數據科學家的熱門選擇。隨著其人氣的發展,越來越多的公司正在從Tensorflow轉移到Pytorch,現在開始使用Pytorch的最佳時間。
今天,我們將幫助了解Pytorch如此流行的是什么,使用Pytorch的一些基礎,并幫助您制作第一個計算模型。
什么是pytorch?
PyTorch是一個開源機器學習Python庫,用于深度學習實現,如計算機視覺(使用武器)和自然語言處理。它是由Facebook的AI Research Lab(Fair)于2016年開發的,自數據科學和ML領域以來已采用。
Pytorch為已經熟悉Python的人提供了直觀的機器,并且具有oop支持和動態計算圖等具有很大的功能。
除了構建深度神經網絡之外,由于其GPU加速,Pytorch也非常適合復雜的數學計算。此功能允許Pytorch使用計算機的GPU來大量加速計算。
這種獨特的功能和Pytorch的無與倫比的簡單的組合使其成為最受歡迎的深度學習庫之一,只有頂點的Tensorflow競爭。
為什么要使用pytorch?
在Pytorch之前,開發人員使用高級微積分來查找反向傳播錯誤和節點加權之間的關系。更深的神經網絡呼吁越來越復雜的操作,限制機器學習的規模和易在性。
現在,我們可以使用ML圖書館自動完成所有的微積分!ML庫可以在幾秒鐘內計算任何大小或形狀網絡,允許更多開發人員構建更大和更好的網絡。
Pytorch通過表現類似于標準Python來進一步逐步邁出此訪問。您可以使用現有的Python知識來快速開始啟動現有的Python知識而不是學習新的語法。此外,您可以使用Pytorch使用額外的Python庫,例如Pycharm調試器等流行調試器。
pytorch與tensorflow.
Pytorch和Tensorflow之間的主要區別是簡單和性能之間的權衡:Pytorch更容易學習(特別是對于Python程序員),而Tensorflow具有學習曲線,但執行更好并且更廣泛地使用。
- 人氣:Tensorflow是行業專業人士和研究人員的當前轉向工具,因為它比Pytorch較早發布了1年。然而,Pytorch用戶的速度比Tensorflow更快,表明Pytorch可能很快是最受歡迎的。
- 數據并行性:Pytorch包括聲明性數據并行性,換句話說,它會自動將數據處理的工作量分布在不同的GPU上以加速性能。Tensorflow有并行性,但它要求您手動分配工作,這通常是耗時和更少的效率。
- 動態與靜態圖表:Pytorch默認情況下具有動態圖形,可立即響應新數據。Tensorflow使用TensoRFlow Fold對動態圖形的支持有限,但主要使用靜態圖形。
- 集成:由于其通過武器密切連接,Pytorch適用于AWS上的項目。Tensorflow與Google Cloud相結合,并且由于其使用SWIFT API而非常適合移動應用程序。
- 可視化:Tensorflow擁有更強大的可視化工具,并提供更精細的圖形設置控制。Pytorch的愿望可視化工具或類似Matplotlib的其他標準繪圖庫并不像Tensorflow那樣完全齊全,但它們更容易學習。
pytorch基礎知識
1. 張量
Pytorch Tensors是作為所有高級操作的基礎的多維陣列變量。與標準數字類型不同,可以分配張量以使用CPU或GPU加速操作。
它們與N維數量數量類似,甚至可以僅在單行中轉換為Numpy數組。
張量有5種類型:
- Floattensor:32位 Float
- Doubletensor:64位 Float
- HalfTensor:16位 Float
- Intstensor:32位int
- longtensor:64位int
與所有數字類型一樣,您希望使用適合您需要保存內存的最小類型。pytorch使用floattensor作為所有張量的默認類型,但您可以使用此使用
- torch.set_default_tensor_type(t)
初始化兩個FloatTensors:
- import torch
- # initializing tensors
- a = torch.tensor(2)
- b = torch.tensor(1)
在簡單的數學運算中可以像其他數字類型一樣使用張量。
- # addition
- print(a+b)
- # subtraction
- print(b-a)
- # multiplication
- print(a*b)
- # division
- print(a/b)
您還可以使用移動GPU的CUDA處理張量。
- if torch.cuda.is_available():
- xx = x.cuda()
- yy = y.cuda()
- x + y
隨著張量在Pytorch中的矩陣,您可以設置Tensors以表示數字表:
- ones_tensor = torch.ones((2, 2)) # tensor containing all ones
- rand_tensor = torch.rand((2, 2)) # tensor containing random values
在這里,我們指定了我們的張量應該是2x2平方。在使用rand()函數時使用vone()函數或隨機數時,填充了廣場。
2. 神經網絡
由于其卓越的分類模型(如圖像分類或卷積神經網絡(CNN)),Pytorch通常用于構建神經網絡。
神經網絡是連接和加權數據節點的層。每個圖層允許模型在其中分類輸入數據最匹配的分類。
神經網絡僅與他們的培訓一樣好,因此需要大數據集和GAN框架,這基于已經由模型掌握的那些產生更具挑戰性的培訓數據。
Pytorch使用Torch.NN包定義神經網絡,其中包含一組模塊來表示網絡的每層。
每個模塊接收輸入張量并計算輸出張力,該輸出張量在一起以創建網絡。Torch.nn封裝還定義了我們用于訓練神經網絡的損耗函數。建立神經網絡的步驟是:
- 架構:創建神經網絡層,設置參數,建立權重和偏見。
- 正向傳播:使用參數計算預測的輸出。通過比較預測和實際輸出來測量誤差。
- 反向傳播:在找到錯誤后,在神經網絡的參數方面采用錯誤功能的導數。向后傳播允許我們更新我們的權重參數。
- 迭代優化:使用優化器通過使用梯度下降來使用迭代更新參數的優化器來最小化錯誤。
這是Pytorch中神經網絡的示例:
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- # 1 input image channel, 6 output channels, 3x3 square convolution
- # kernel
- self.conv1 = nn.Conv2d(1, 6, 3)
- self.conv2 = nn.Conv2d(6, 16, 3)
- # an affine operation: y = Wx + b
- self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
- def forward(self, x):
- # Max pooling over a (2, 2) window
- x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
- # If the size is a square you can only specify a single number
- x = F.max_pool2d(F.relu(self.conv2(x)), 2)
- xx = x.view(-1, self.num_flat_features(x))
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
- def num_flat_features(self, x):
- size = x.size()[1:] # all dimensions except the batch dimension
- num_features = 1
- for s in size:
- num_features *= s
- return num_features
- net = Net()
- print(net)
NN.Module指定這將是一個神經網絡,然后我們用2個Conv2D層定義它,該層執行2D卷積,以及執行線性變換的3個線性層。
接下來,我們定義了向前概述轉發傳播的前向方法。我們不需要定義向后傳播方法,因為Pytorch默認包括向后()功能。
別擔心現在似乎令人困惑,我們將在本教程后面介紹更簡單的Pytorch實現。
3. Autograd
Autograd是一個用于計算神經網絡操作所必需的衍生產品的Pytorch包。這些衍生物稱為梯度。在轉發通行證期間,Autograd在梯度的張量上記錄所有操作,并創建一個非循環圖,以找到張量和所有操作之間的關系。此操作集合稱為自動差異化。
該圖的葉子是輸入張量,根部是輸出張量。Autograd通過將圖形從根到葉子跟蹤并將每個梯度乘以使用鏈規則來計算漸變來計算梯度。
在計算梯度之后,衍生物的值被自動填充為張量的grad屬性。
- import torch
- # pytorch tensor
- x = torch.tensor(3.5, requires_grad=True)
- # y is defined as a function of x
- y = (x-1) * (x-2) * (x-3)
- # work out gradients
- y.backward()
默認情況下,RESCEL_GRAD設置為FALSE,PyTorch不會跟蹤漸變。在初始化期間指定RESECT_GRAD為TRUE將使您在執行某些操作的情況下對該特定張量進行PYTORCH跟蹤梯度。
此代碼查看Y并看到它來自(x-1)(x-2)(x-3),并自動制造梯度dy / dx,3x ^ 2 - 12x + 11
該指令還解決了該梯度的數值,并將其放置在張量x內,同時x,3.5的實際值。
漸變為3 (3.5 3.5) - 12 *(3.5)+ 11 = 5.75。
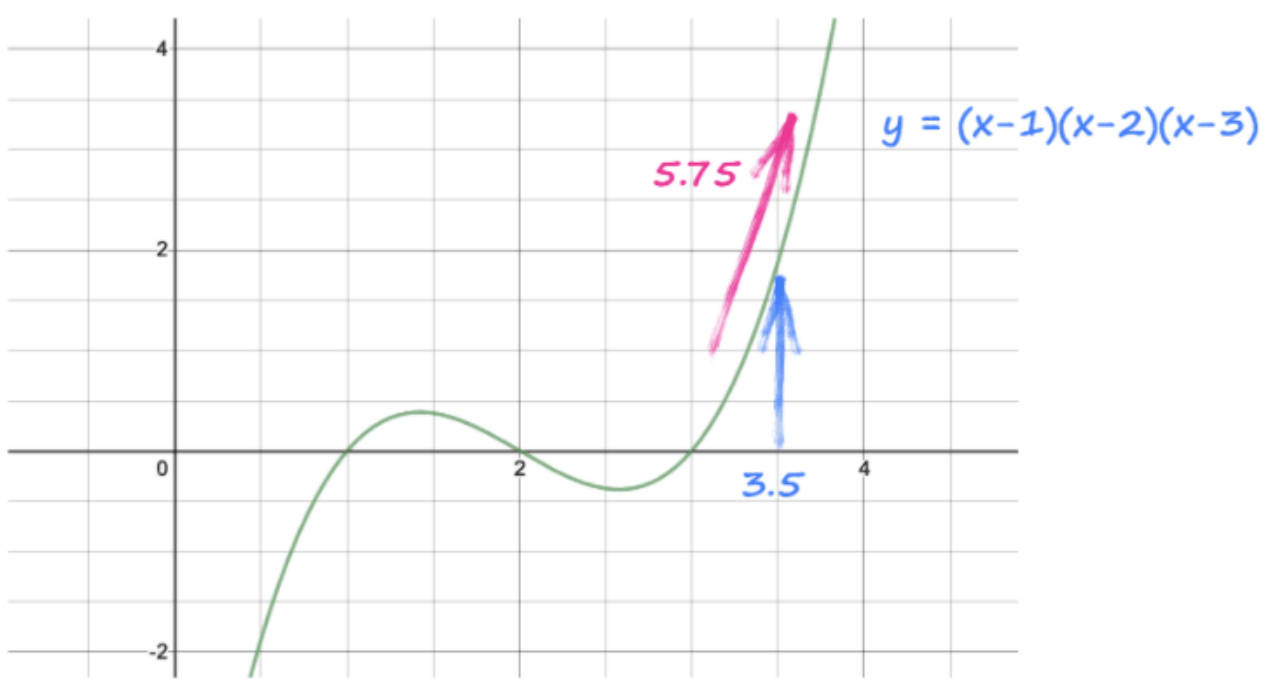
> Image Source: Author
漸變默認累計,如果未重置,則可能會影響結果。使用Model.zero_grad()在每個漸變后重新歸零您的圖形。
4. 優化器
優化器允許您在模型中更新權重和偏置以減少錯誤。這允許您編輯模型的工作原理,而無需重新制止整個事物。
所有Pytorch優化器都包含在Torch.optim包中,每個優化方案都設計用于特定情況。Torch.optim模塊允許您通過剛剛傳遞參數列表來構建抽象優化方案。Pytorch有許多優化器可以選擇,這意味著幾乎總是一個最適合您的需求。
例如,我們可以實現公共優化算法,SGD(隨機梯度下降),以平滑我們的數據。
- import torch.optim as optim
- params = torch.tensor([1.0, 0.0], requires_grad=True)
- learning_rate = 1e-3
- ## SGD
- optimoptimizer = optim.SGD([params], lr=learning_rate)
更新模型后,使用優化器.step()告訴Pytorch來重新計算模型。使用優化器,我們需要使用循環手動更新模型參數:
- for params in model.parameters():
- params -= params.grad * learning_rate
總的來說,優化器通過允許您優化數據加權并改變模型而無需重新制定若需時間來節省大量時間。
5. 使用pytorch計算圖
為了更好地了解Pytorch和神經網絡,可以使用計算圖來練習。這些圖形本質上是一種簡化版本的神經網絡,用于有一系列操作,用于了解系統的輸出如何受輸入的影響。
換句話說,輸入x用于找到y,然后用于找到輸出z。
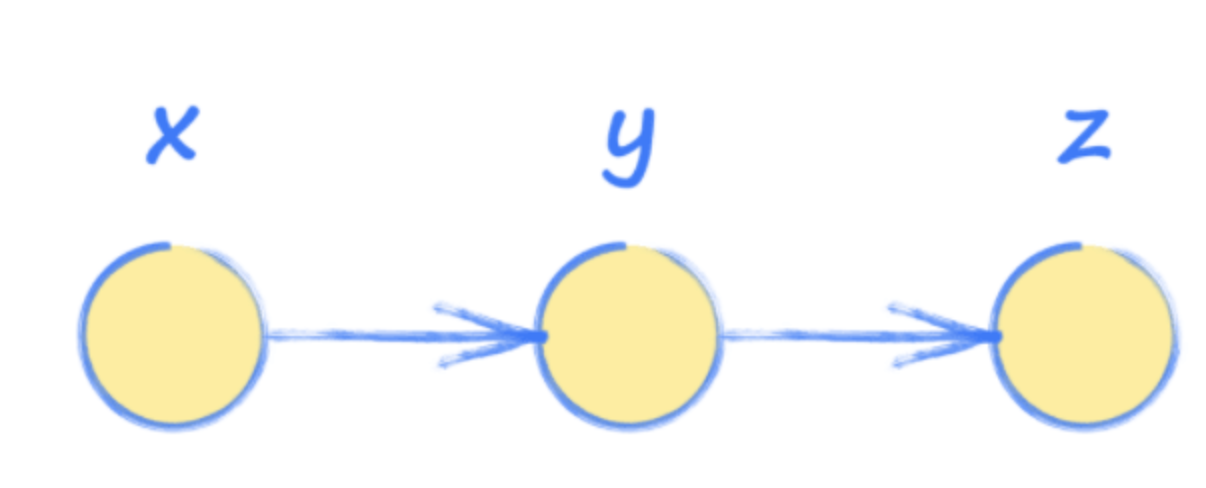
> Image Source: Author
想象一下,Y和Z計算如下:
- y = x ^ 2
- z = 2Y + 3
但是,我們對輸出Z如何使用Input X進行更改感興趣,因此我們需要執行一些微積分:
- dz / dx =(dz / dy)*(dy / dx)
- dz / dx = 2.2x
- dz / dx = 4x
使用此,我們可以看到輸入x = 3.5將使z = 14。
知道如何在其他情況下定義每個張量(根據x,z的y和z,y等方面等)允許pytorch構建這些張量如何連接的圖像。
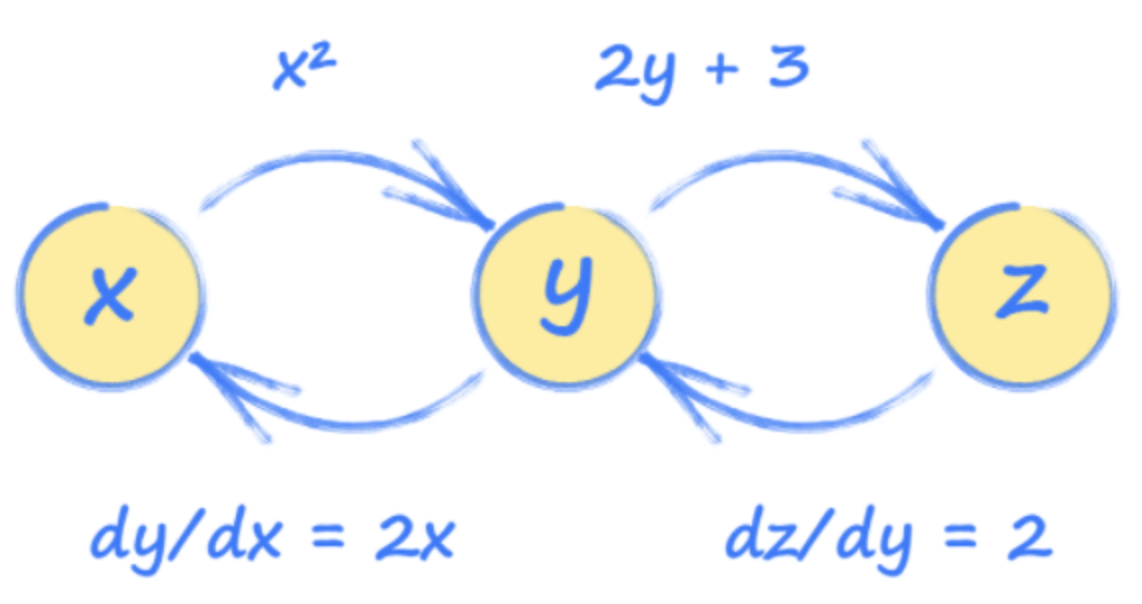
> Image Source: Author
這張照片稱為計算圖,可以幫助我們了解Pytorch如何在幕后工作。
使用此圖形,我們可以看到每個張量如何受到任何其他張量的變化的影響。這些關系是梯度,用于在訓練期間更新神經網絡。
這些圖更容易使用Pytorch比手工操作更容易,所以我們現在試試吧,我們了解幕后發生的事情。
- import torch
- # set up simple graph relating x, y and z
- x = torch.tensor(3.5, requires_grad=True)
- y = x*x
- z = 2*y + 3
- print("x: ", x)
- print("y = x*x: ", y)
- print("z= 2*y + 3: ", z)
- # work out gradients
- z.backward()
- print("Working out gradients dz/dx")
- # what is gradient at x = 3.5
- print("Gradient at x = 3.5: ", x.grad)
這發現Z = 14就像我們用手發現的那樣!
6. 與Pytorch的實踐:多路徑計算圖
既然你已經看到了一個具有單一關系的計算圖,讓我們嘗試一個更復雜的例子。
首先,定義兩個張量,a和b,以用作我們的輸入。確保設置RESECT_GRAD = TRUE,以便我們可以將漸變縮小到下線。
- import torch
- # set up simple graph relating x, y and z
- a = torch.tensor(3.0, requires_grad=True)
- b = torch.tensor(2.0, requires_grad=True)
接下來,設置我們的輸入和我們神經網絡的每層之間的關系,x,y和z。請注意,z在x和y方面定義,而x和y使用我們的輸入值a和b定義。
- import torch
- # set up simple graph relating x, y and z
- a = torch.tensor(3.0, requires_grad=True)
- b = torch.tensor(2.0, requires_grad=True)
- x = 2*a + 3*b
- y = 5*a*a + 3*b*b*b
- z = 2*x + 3*y
這構建了一個關系鏈,Pytorch可以遵循了解數據之間的所有關系。
我們現在可以通過從z向a追隨z到a的路徑來解決梯度Dz / da。
有兩條路徑,一個通過x和另一條通過y。您應該遵循它們并將兩條路徑的表達式添加在一起。這是有道理的,因為來自a到z的兩條路徑有助于z的值。
如果我們使用Chain規則的微積分法定了DZ / DA,我們已經找到了相同的結果。
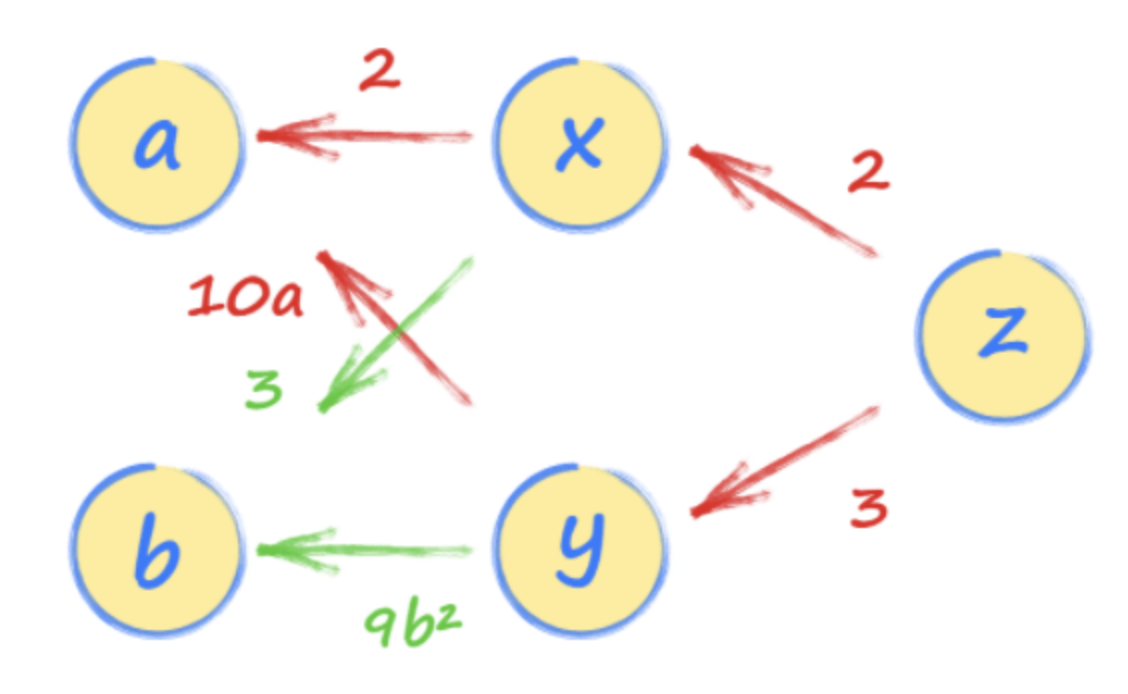
> Image Source: Author
第一路徑X給我們2 * 2,第二條路徑通過Y給我們3 * 10A。因此,Z隨著4 + 30A而變化的速率。
如果A是22,則DZ / DA為4 + 30 * 2 = 64。
我們可以通過從z添加向后傳播然后詢問a的梯度(或衍生)來確認它。
- import torch
- # set up simple graph relating x, y and z
- a = torch.tensor(2.0, requires_grad=True)
- b = torch.tensor(1.0, requires_grad=True)
- x = 2*a + 3*b
- y = 5*a*a + 3*b*b*b
- z = 2*x + 3*y
- print("a: ", a)
- print("b: ", b)
- print("x: ", x)
- print("y: ", y)
- print("z: ", z)
- # work out gradients
- z.backward()
- print("Working out gradient dz/da")
- # what is gradient at a = 2.0
- print("Gradient at a=2.0:", a.grad)
你學習的下一步
恭喜,您現在已完成您的快速入門,并且是Pytorch和神經網絡。完成計算圖形是了解深度學習網絡的重要組成部分。
當您了解高級深度學習技能和應用程序時,您將想要探索:
- 復雜的神經網絡,優化
- 可視化設計
- 用GAN訓練
快樂學習!
原文鏈接:https://ai.plainenglish.io/pytorch-tutorial-a-quick-guide-for-new-learners-180957cb7214
















