重磅!GitHub 開源負載均衡組件 GLB Director
8 月 8 日,GitHub 發布了開源負載均衡組件 GitHub Load Balancer Director(GLB) Director,GLB 是 GitHub 針對裸機數據中心的可擴展負載均衡解決方案,它支持大多數 GitHub 的對外服務,并且還為諸如高可用 MySQL 集群這樣最為關鍵的內部系統提供負載均衡服務。
項目地址:https://github.com/github/glb-director

GLB Director 有如下諸多優勢:
使用ECMP擴展IP
4層負載均衡器的基本屬性是能夠使用單個IP地址在多個服務器之間實現均衡連接。 為了擴展單個IP以處理更多的流量,我們不僅需要在后端服務器之間進行流量拆分,還需要能夠擴展負載均衡器本身。 這實際上是另一層負載均衡。
通常,我們將IP地址視為單個物理機器,將路由器視為將數據包移動到下一個最近路由器的機器。 在最簡單的情況下,總是有一個最佳的下一跳,路由器選擇該跳并轉發所有數據包直到達到目的地。
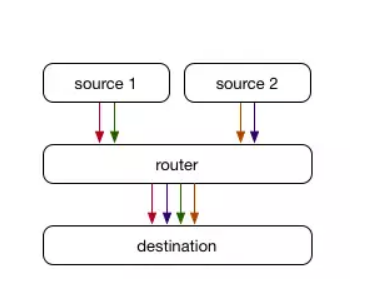
實際上,大多數網絡都要復雜得多。 兩臺計算機之間通常有多條路徑可用,例如,使用多個ISP或者兩臺路由器通過多條物理電纜連接在一起以增加容量并提供冗余。 這是等價多路徑(ECMP)路由發揮作用的地方 - 而不是由路由器選擇單個最佳下一跳,ECMP中很多路徑具有相同成本(通常定義為到目的地的AS的數量), 路由器分散流量以便在所有可用的相同成本路徑之間均衡連接。
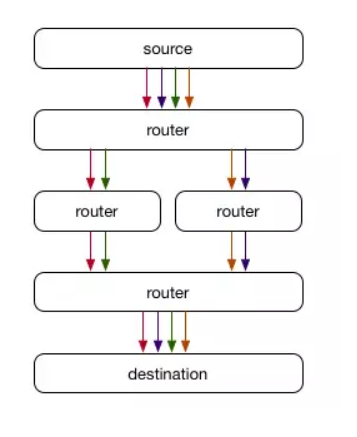
ECMP通過對每個數據包進行hash以確定其中一個可用路徑。此處使用的hash函數因設備而異,但通常是基于源和目標IP地址以及TCP流量的源和目標端口的一致性hash。這意味著同一個TCP連接的多個數據包通常會遍歷相同的路徑,這意味著即使路徑具有不同的延遲,數據包也會以相同的順序到達。值得注意的是,在這種情況下,路徑可以在不中斷連接的情況下進行更改,因為它們總是最終位于同一個目標服務器上,此時它所采用的路徑大多無關緊要。
ECMP的另一種用法是當我們想要跨多個服務器而不是跨多個路徑上的同一服務器時。每個服務器都可以使用BGP或其他類似的網絡協議使用相同的IP地址,從而使連接在這些服務器之間進行分片,路由器不知道連接是在不同的地方處理的,而非傳統做法那樣所有的連接都同一臺機器上處理。
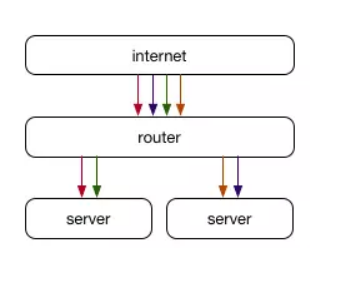
雖然ECMP會像對流量進行分片,但它有一個巨大的缺點:當相同IP的服務器更改(或沿途的任何路徑或路由器發生變化)時,連接必須重新均衡,才能保證每個服務器上的連接比較均衡。 路由器通常是無狀態設備,只是為每個數據包做出最佳決策而不考慮它所屬的連接,這意味著在這種情況下某些連接會中斷。
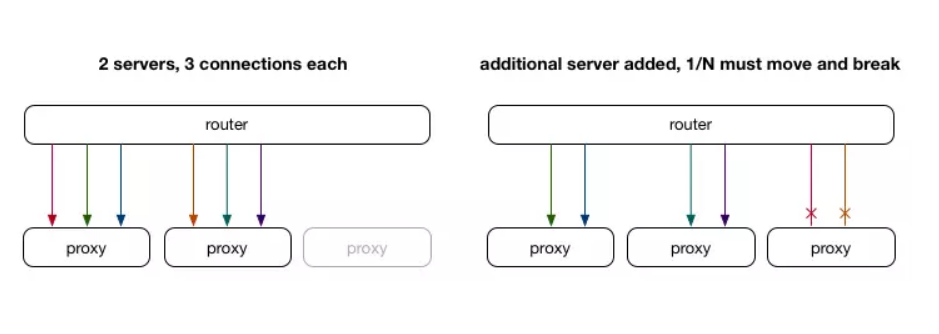
在上面的例子中,我們可以想象每種顏色代表一個活動的連接。 添加新的代理服務器使用相同的IP。 路由器保證一致性哈希,將1/3連接移動到新服務器,同時保持2/3連接在老服務器上。 不幸的是,對于進行中的1/3連接,數據包現在到達了無連接狀態的服務器,因此連接會失敗。
將director/proxy分離
以前僅使用ECMP的解決方案的問題在于它不知道給定數據包的完整上下文,也不能為每個數據包/連接存儲數據。事實證明,通常使用Linux Virtual Server(LVS)等工具。我們創建了一個新的“director”服務器層,它通過ECMP從路由器獲取數據包,但不是依靠路由器的ECMP hash來選擇后端代理服務器,而是對所有鏈接控制hash和存儲狀態(選擇后端)。當我們更改代理層服務器時,director層有望不變,我們的連接也不會斷掉。
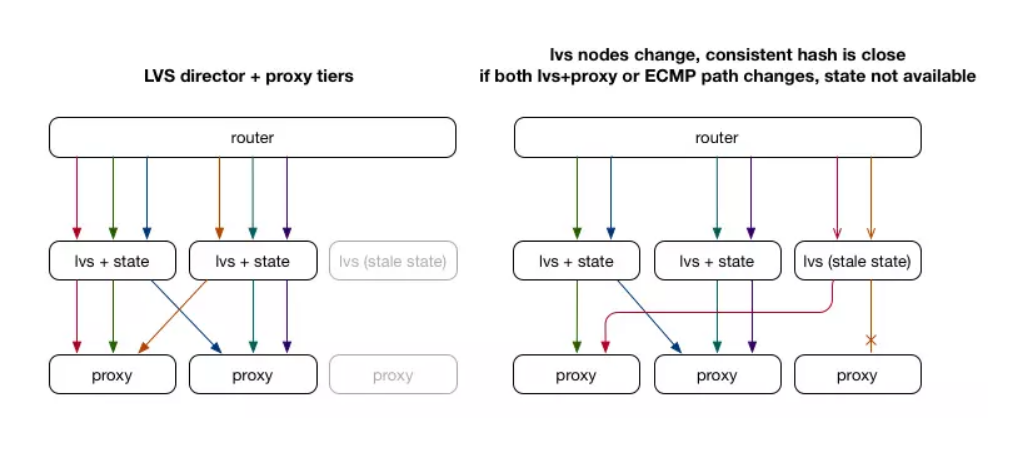
雖然這在許多情況下效果很好,但它確實有一些缺點。在上面的示例中,我們同時添加了LVS director和后端代理服務器。新的director接收到一些數據包,但是還沒有任何狀態(或者具有延遲狀態),因此將其作為新連接進行hash處理并可能使其出錯(并導致連接失敗)。 LVS的典型解決方法是使用多播連接同步來保持所有LVS director服務器之間共享的連接狀態。這仍然需要傳播連接狀態,并且仍然需要重復狀態 - 不僅每個代理都需要Linux內核網絡堆棧中每個連接的狀態,而且每個LVS director還需要存儲連接到后端代理服務器的映射。
將所有狀態從director層移除
當我們設計GLB時,我們決定要改善這種情況而不是重復狀態。 通過使用已存儲在代理服務器中的流狀態作為維護來自客戶端的已建立Linux TCP連接的一部分,GLB采用與上述方法不同的方法。
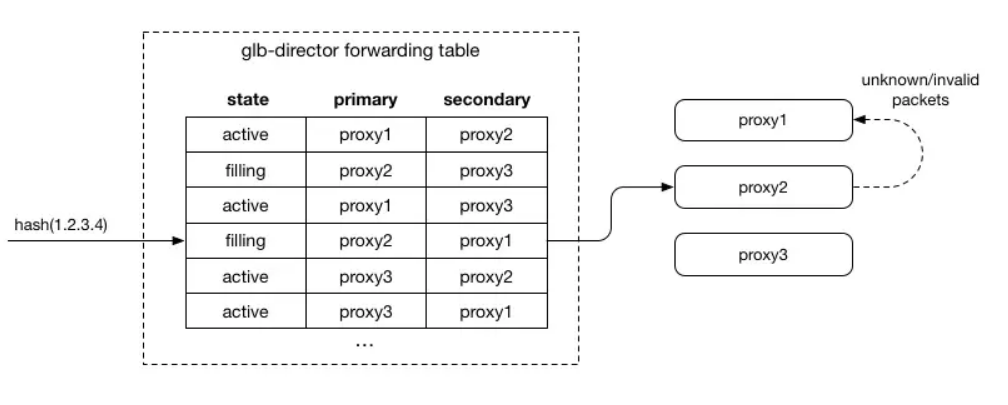
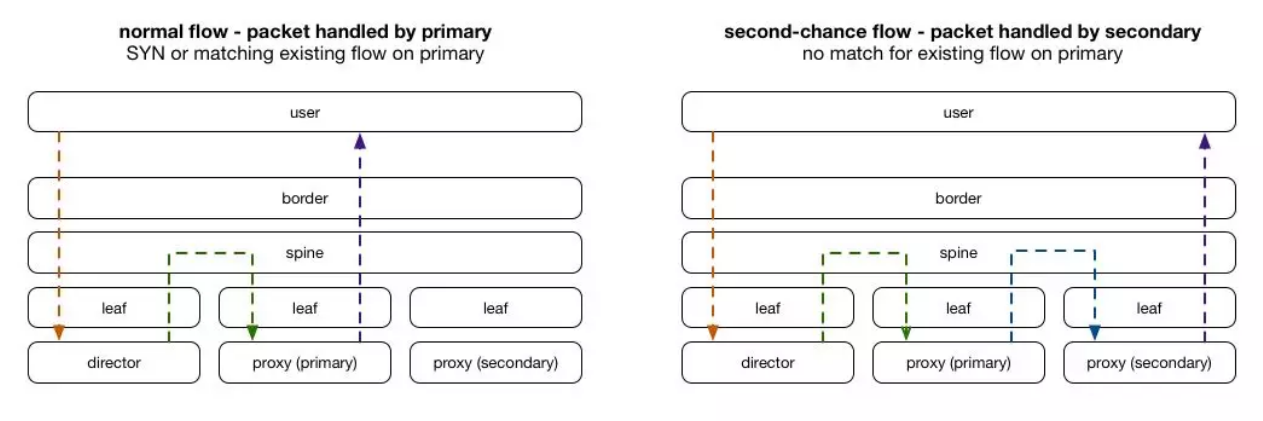
對于每個進入的連接,我們選擇可以處理該連接的主服務器和輔助服務器。 當數據包到達主服務器且無效時,會將數據包轉發到輔助服務器。 選擇主/輔助服務器的散列是預先完成一次,并存儲在查找表中,因此不需要在每個流或每個數據包的基礎上重新計算。 添加新的代理服務器時,對于1/N連接,它將成為新的主服務器,舊的主服務器將成為輔助服務器。 這允許現有流程完成,因為代理服務器可以使用其本地狀態(單一事實來源)做出決策。 從本質上講,這使得數據包在到達保持其狀態的預期服務器時具有“第二次機會”。
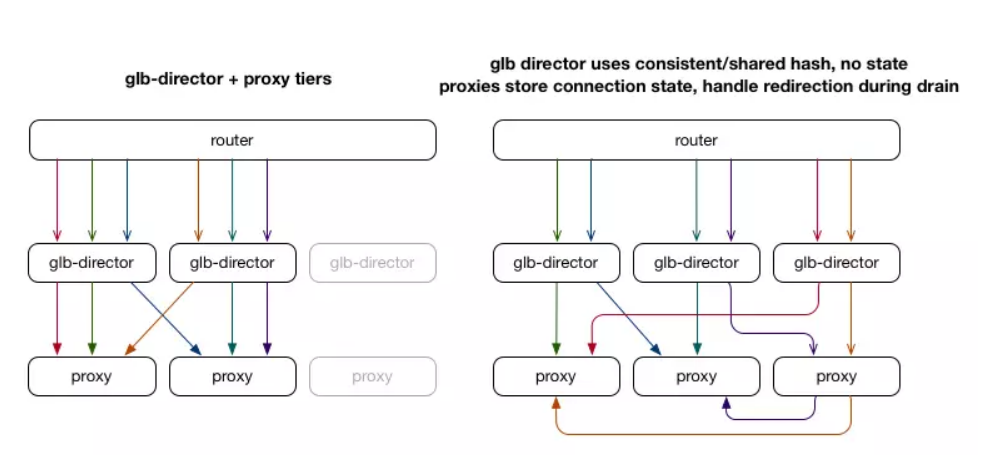
即使director仍然會將連接發送到錯誤的服務器,該服務器也會知道如何將數據包轉發到正確的服務器。 就TCP流而言,GLB director層是完全無狀態的:director服務器可以隨時進出,并且總是選擇相同的主/輔服務器,只要它們的轉發表匹配(但它們很少改變)。 在變更代理時有些細節需要注意,我們將在下面介紹。
維護Hash集合不變
GLB Director設計的核心歸結為始終如一地選擇主服務器和輔助服務器,并允許代理層服務器根據需要排空和填充。 我們認為每個代理服務器都有一個狀態,當有服務器加入或者退出時調整狀態。
我們創建一個靜態二進制轉發表,它以相同方式在每個控制器服務器上生成,以將進入的連接映射到給定的主服務器和輔助服務器。 我們并沒有采用在數據包處理時從所有可用服務器中選擇服務器的這種復雜邏輯,而是通過創建表(65k行)這種間接的方式,每行包含主服務器和輔助服務器IP地址。 該表以二維數組的方式將數據存儲在內存中,每個表大約512kb。 當數據包到達時,我們始終將其(僅基于數據包數據)hash到該表中的同一行(使用hash作為數組的索引),這提供了一致的主服務器和輔助服務器對。
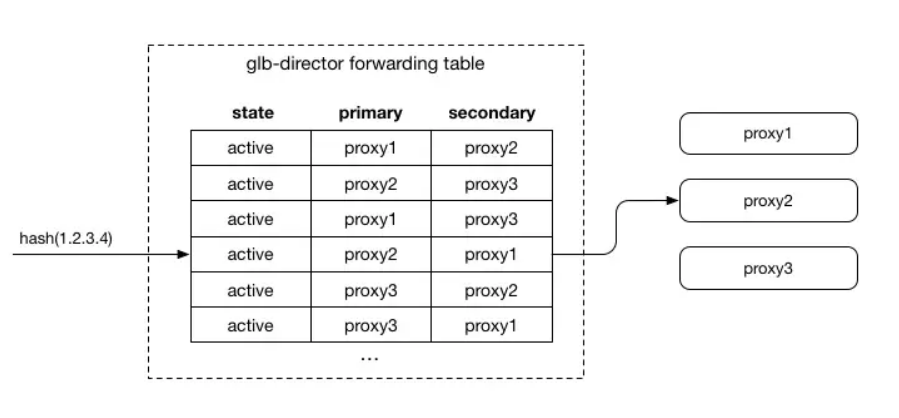
我們希望每個服務器在主要和輔助字段中大致相同,并且永遠不會出現在同一行中。 當我們添加新服務器時,我們希望某些行使其主服務器成為輔助服務器,并且新服務器將成為主服務器。 同樣,我們希望新服務器在某些行中成為輔助服務器。 當我們刪除服務器時,在它是主服務器的任何行中,我們希望輔助服務器成為主服務器,而另一個服務器則成為輔助服務器。
這聽起來很復雜,但可以用幾個不變量簡潔地概括:
-
當我們更改服務器集時,應保持現有服務器的相對順序。
-
服務器的順序應該是可計算的,除了服務器列表之外沒有任何其他狀態(可能還有一些預定義的種子)。
-
每個服務器在每行中最多應出現一次。
-
每個服務器在每列中的出現次數應大致相同。
針對上述的一些問題,集合hash是一個理想的選擇,因為它可以很好地滿足這些不變量。 每個服務器(在我們的例子中,IP)都與行號一起進行hash,服務器按該hash(只是一個數字)進行排序,并且我們獲得該給定行的服務器的唯一順序。 我們分別將前兩個作為主要和次要。
將保持相對順序,因為無論包含哪些其他服務器,每個服務器的hash都是相同的。 生成表所需的唯一信息是服務器的IP。由于我們只是對一組服務器進行排序,因此服務器只出現一次。 最后,如果我們使用偽隨機的良好hash函數,那么排序將是偽隨機的,因此分布將如我們所期望的那樣均勻。
代理(Proxy)相關操作
添加或刪除代理服務器,我們需要一些特別的處理方式。這是因為轉發表條目僅定義主要/輔助代理,因此排空/故障轉移僅適用單個代理主機。 我們為代理服務器定義以下有效狀態和狀態轉換:
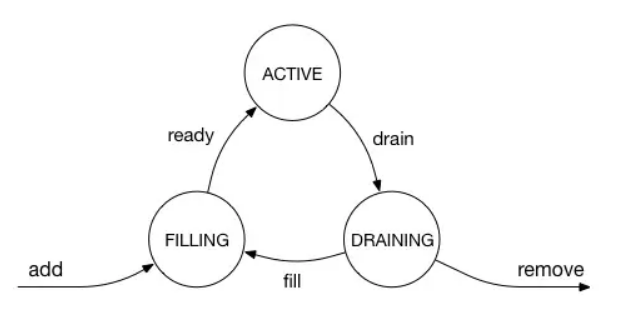
當代理服務器處于活動狀態,耗盡或填充時,它將包含在轉發表條目中。 在穩定狀態下,所有代理服務器都是活動的,并且上面描述的集合點散列將在主列和輔助列中具有大致均勻且隨機的每個代理服務器分布。
當代理服務器轉換為耗盡時,我們通過交換我們原本包含的主要和次要條目來調整轉發表中的條目:
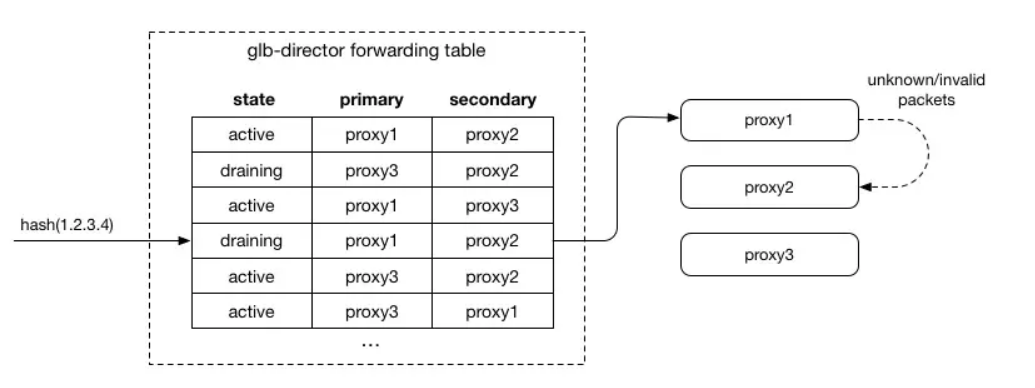
這具有將數據包發送到先前次要的服務器的效果。 由于它首先接收數據包,它將接受SYN數據包,因此接受任何新連接。 對于任何不理解為與本地流有關的數據包,它將其轉發到其他服務器(先前的主服務器),這允許完成現有連接。
這樣可以優雅地耗盡所需的連接服務器,之后可以完全刪除它,并且代理可以隨機填充到第二個空槽:
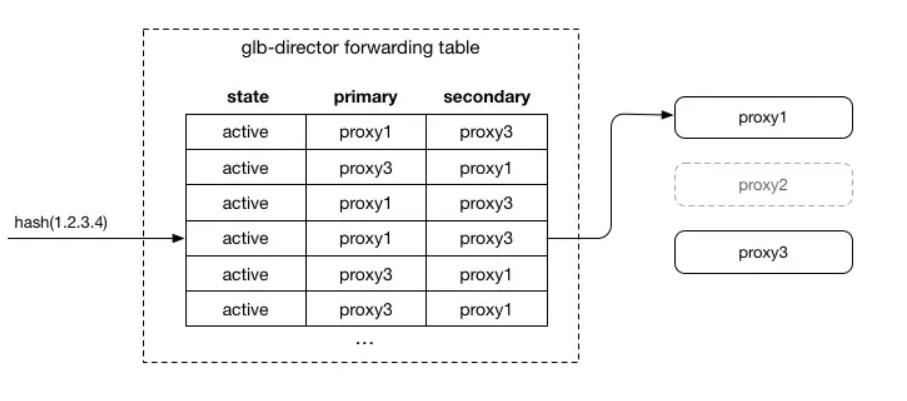
填充中的節點看起來就像活動一樣,因為該表本身允許第二次機會:
此實現要求一次只有一個代理服務器處于活動狀態以外的任何狀態,這實際上在GitHub上運行良好。對代理服務器的狀態更改可以與需要維護的最長連接持續時間一樣快。我們正致力于設計的擴展,不僅支持主要和次要,而且一些組件(如下面列出的標題)已經包含對任意服務器列表的初始支持。
數據中心內封裝
現在有了一個算法來一致地選擇后端代理服務器,但是如何在數據包內把輔助服務器(secondary server )的信息也封裝進去呢?這樣主服務器可以在不理解數據包的情況下轉發數據包。
LVS 的傳統方式是使用IP over IP(IPIP)隧道。客戶端 IP 數據包封裝在內部IP數據包內,并轉發到代理服務器,代理服務器對其進行解封裝。但很難在 IPIP 數據包中編碼其他服務器的元數據,因為唯一可用的空間是 IP 選項,數據中心路由器傳遞未知 IP 的數據包到處理軟件(稱之為“第2層慢速路徑”),速度從每秒數百萬到數千個數據包。
為了避免這種情況,需要將數據隱藏在路由器不同數據包格式中,避免它試圖去理解。我們最初采用原始 Foo-over-UDP(FOU)和自定義 GRE載荷(payload),基本上封裝了 UDP 數據包中的所有內容。我們最近轉換到通用 UDP 封裝(GUE),它提供了封裝內部 IP 協議的標準 UDP 數據包。我們將輔助服務器的 IP 放在GUE標頭的私有數據中。從路由器的角度來看,這些數據包都是兩個普通服務器之間的內部數據中心 UDP 數據包。

使用 UDP 的另一個好處是源端口可以使用每個連接的哈希填充,以便它們通過不同的路徑(在數據中心內使用ECMP)在數據中心內流動,并可在代理服務器的 NIC 的不同 RX 隊列上接收消息(類似使用 TCP/IP 頭字段的哈希)。這對 IPIP 是不可能的,因為大多數數據中心的 NIC 只能理解普通 IP,TCP/IP 和 UDP/IP。值得注意的是,NIC 無法查看 IP/IP 數據包。
當代理服務器想要將數據包發送回客戶端時,它不需要封裝或通過我們的導向器層(director tier)返回,它可以直接發送數據到客戶端(通常稱為“Direct Server Return”)。這是典型的負載均衡器設計,對于內容提供商尤其有用,因為大多數情況都是出站流量遠大于入站流量。
數據包流如下圖所示:
引入DPDK
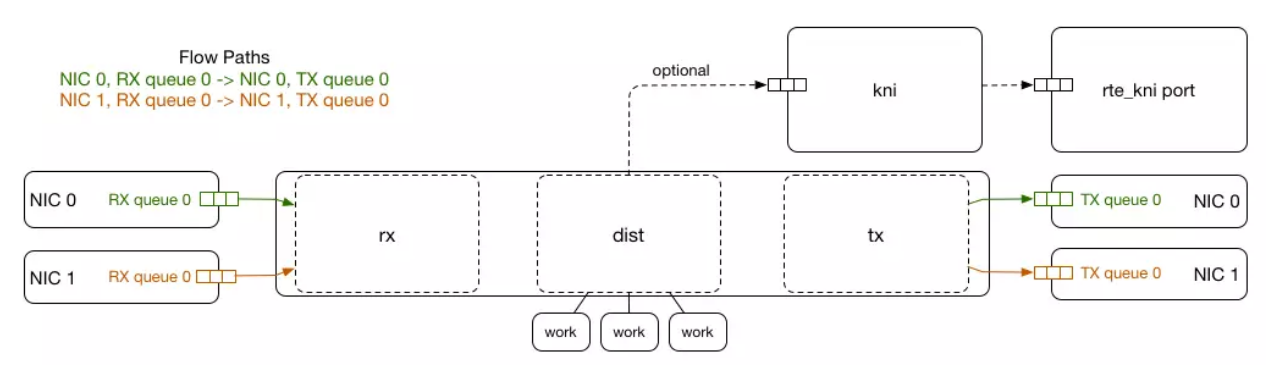
自從首次公開討論了我們的初始設計以來,我們已經完全使用 DPDK重寫了 glb-director 。DPDK 是一個開源的通過繞過Linux內核,允許從用戶空間進行非常快速的數據包處理的項目。這樣就能夠在普通 NIC 上通過 CPU 上實現 NIC 線路速率處理,并可輕松擴展導向器層,以處理與公共連接所需的入站流量一樣多的流量。這在防 DDoS 攻擊中尤為重要,我們不希望負載均衡器成為瓶頸。
GLB 最初的目標之一是可以在通用數據中心的硬件上運行,而無需任何特殊的硬件配置。 GLB 的 Director 和代理服務器都可像數據中心的普通服務器一樣供應。每個服務器都有一對綁定的網絡接口,這些接口在 GLB Director 服務器上的 DPDK 和 Linux 系統之間共享。
現代 NIC 支持SR-IOV,這種技術可以使單個 NIC 從操作系統的角度看起來像多個 NIC。這通常由虛擬機管理程序使用,以要求真實 NIC(“Physical Function”)為每個 VM 創建多個虛擬 NIC(“Virtual Functions”)。為了使 DPDK 和 Linux 內核能夠共享 NIC,我們使用 flow bifurcation,它將特定流量(目標是 GLB IP 地址)發送給我們DPDK 在 Virtual Function 上處理,同時將剩余的數據包與 Linux 內核的網絡堆棧保留在 Physical Function 上。
我們發現 Virtual Function 上 DPDK 的數據包處理速率可以滿足要求。 GLB Director 使用 DPDK Packet Distributor模式來分發封裝數據包的任務到機器上的 CPU,支持任意數量的 CPU 核心,因為它是無狀態的,可以高度并行化。
GLB Director 支持匹配和轉發包含 TCP 有效負載的入站 IPv4 和 IPv6 數據包,以及作為 Path MTU Discovery的一部分的入站 ICMP Fragmentation Required 消息。
使用Scapy為DPDK加入測試用例
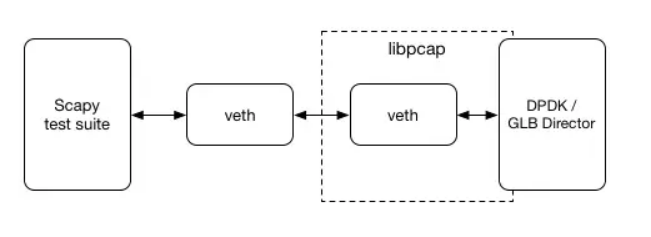
一個典型的問題是,在創建(或使用)那些使用了低級原語(例如直接與NIC通信)但是高速運行的技術時,它們變得非常難以測試。作為創建GLB Director的一部分,我們也創建了一個測試環境,支持對我們的DPDK應用進行簡單的端對端包流測試,通過影響DPDK的方式支持一個環境抽象層(EAL),允許物理NIC和基于libpcap的本地接口,在應用視圖中是相同的。
這允許我們在Scapy中寫測試,使用簡單的Python的lib包查看,操作和寫數據包。通過創建一個Linux的虛擬網卡驅動,一邊用Scapy,另一邊用DPDK,我們能傳輸定制的包并且驗證我們軟件在另一邊支持的功能,這是一個完整GUE封裝的后端代理服務期望的數據包。
該方法允許我們測試更多的復雜行為,例如為了正確路由,遍歷傳輸層的ICMPv4/ICMPv6頭獲取源IP和TCP端口,以便正確轉發來自外部路由器的ICMP消息。
健康檢查
GLB的設計包含了優雅地處理服務器故障的部分。目前設計包含主/備,對于給定的轉發表/客戶端,意味著我們可以通過健康檢查通過觀察每個Director來解決單服務器故障。我們運行一個名為glb-healthcheck的服務,它不斷驗證每個后端服務器的GUE隧道和任意HTTP端口。
當服務器出現故障時,我們將切換主/備,將備換成主。這是服務器的“軟切換”,支持故障轉移的好辦法。如果健康檢查失敗是誤報,則連接不會中斷,它們只會換一條不同的路徑遍歷。
proxy使用iptables提供第二次機會
構成GLB的最后一個組件是Netfilter模塊和iptables的目標,它在每個代理服務器上運行,并提供“第二次機會”進行設計。
此模塊提供了一個簡單的任務,根據Linux內核TCP堆棧,確定每個GUE數據包的內部TCP / IP數據包是否在本地有效,如果不是,則將其轉發到下一個代理服務器(備服務器),而不是在當前服務器解封裝。
在數據包是SYN(新連接)或在本地對已建立的連接有效的情況下,當前服務器會接收它。然后,我們接收GUE包,使用包含fou模塊的Linux 內核4.x GUE在本地處理它。