













BlackHat 2018 | iOS越獄細節揭秘:危險的用戶態只讀內存
議題概要
現代操作系統基本都已經在硬件級別(MMU)支持了用戶態只讀內存,只讀內存映射在保證了跨進程間通信、用戶態與內核間通信高效性的同時,也保證了其安全性。直到DirtyCOW漏洞的出現,這種信任邊界被徹底打破。
在iOS中,這樣的可信邊界似乎是安全的,然而隨著蘋果設備的快速更新和發展,引入了越來越多的酷炫功能。許多酷炫功能依賴iOS與一些獨立芯片的共同協作。其中,DMA(直接內存訪問)技術讓iOS與這些獨立芯片之間的數據通信變得更加高效。
然而,很少有人意識到,這些新功能的引入,悄然使得建立已久的可信邊界被打破。科恩實驗室經過長時間的研究,發現了一些間接暴露給用戶應用的DMA接口。雖然DMA的通信機制設計的比較完美,但是在軟件實現層出現了問題。將一系列的問題串聯起來后,將會形成了一個危害巨大的攻擊鏈,甚至可導致iOS手機被遠程越獄。部分技術曾在去年的MOSEC大會上進行演示,但核心細節與技術從未被公開。該議題將首次對這些技術細節、漏洞及利用過程進行分享,揭示如何串聯多個模塊中暴露的“不相關”問題,最終獲取iOS內核最高權限的新型攻擊模式。
作者簡介
陳良,騰訊安全科恩實驗室安全研究專家,專注于瀏覽器高級利用技術、Apple系操作系統(macOS/iOS)的漏洞挖掘與利用技術研究。他曾多次帶領團隊獲得Pwn2Own 、Mobile Pwn2Own的冠軍,并多次實現針對iOS系統的越獄。
議題解析
現代操作系統都會實現內存保護機制,讓攻擊變得更困難。iOS在不同級別實現了這樣的內存保護,例如,MMU的TBE屬性實現NX、PXN、AP等,以及更底層的KPP、AMCC等:

其中,用戶態只讀內存機制,在iOS上有很多應用,比如可執行頁只讀、進程間只讀以及內核到用戶態內存的只讀:

如果一旦這些只讀內存的保護被破壞,那么最初的可信邊界就會被徹底破壞,在多進程通信的模式下,這可以導致沙盒繞過。而對于內核和用戶態內存共享模式下,這可能可以導致內核代碼執行:

然而突破這樣的限制并不容易,在iOS中,內核代碼會阻止這樣的情況發生:每個內存頁都有一個max_prot屬性,如果這個屬性設置為不能大于只讀,那么所有設置成writable的重映射請求都會被阻止:

隨著手機新技術的發展,DMA技術也被應用于手機上,DMA是一種讓內存可以不通過CPU進行處理的技術,也就是說,所有CPU級別的內存保護,對于DMA全部無效。
那么,是不是說,DMA沒有內存保護呢?事實并非如此,這是因為兩個原因:第一,對于64位手機設備,許多手機的周邊設備(例如WIFI設備)還是32位的,這使得有必要進行64位和32位地址間轉換;第二是因為DMA技術本身需要必要的內存保護。

正因為如此,IOMMU的概念被提出了。在iOS設備中,DART模塊用來實現這樣的地址轉換。
事實上DMA有兩種:Host-to-device DMA以及device-to-host DMA,前者用于將系統內存映射到設備,而后者用戶將設備內存映射于系統虛擬內存。在2017年中,Google Project Zero的研究員Gal Beniamini先將WIFI芯片攻破,然后通過修改Host-to-device DMA的一塊內存,由于內核充分信任這塊內存,忽略了一些必要的邊界檢查,導致成功通過WIFI來攻破整個iOS系統:

然而Gal的攻擊方式存在一定局限,因為必須在短距離模式下才能完成:攻擊WIFI芯片需要攻擊者和受害者在同一個WIFI環境中。
我們有沒有辦法通過DMA的問題實現遠距離攻破,這聽上去并不可行,因為DMA接口本身并不會暴露于iOS用戶態。
然而通過科恩實驗室的研究發現,可能存在一些間接接口,可以用來做DMA相關的操作,例如iOS中的JPEG引擎以及IOSurface transform等模塊。我們選擇研究IOSurface transform模塊的工作機制。以下是IOSurface transform模塊的工作機制:
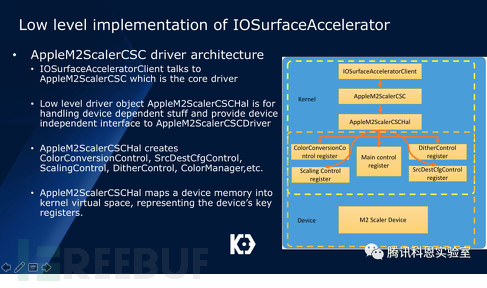
IOSurfaceAccelerator接口通過用戶態提供的兩個IOSurface地址作為用戶參數,通過操作Scaler設備,將IOSurface對應的地址轉換成Scaler設備可見的設備地址,然后啟動scaler設備進行transform,整個過程如下:
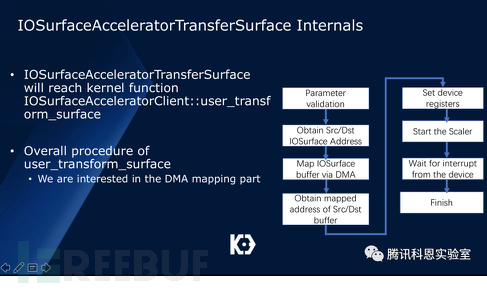
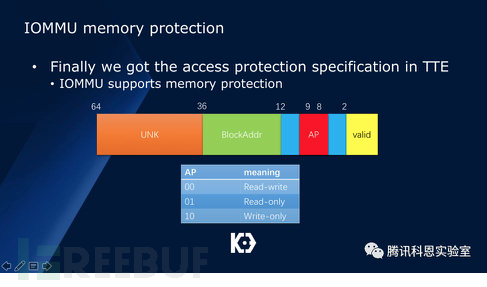
另一方面,在這個Host-to-device DMA過程中,用戶態內存的只讀屬性是否被考慮在內,是一個比較疑惑的問題。我們經過研究,發現在IOMMU中是支持內存屬性的:

在TTE的第8和第9位,是用于執行內存頁的讀寫屬性的:

因此我們得到這樣的頁表屬性定義:
我們之后介紹了蘋果圖形組件的工作模式:

在iPhone7設備中,一共有128個Channel,這些Channel被分成三類:CL、GL和TA,內核將來自用戶態的繪圖指令包裝并塞入這128個channel,然后等待GPU的處理。由于GPU處理是高并發的,因此需要很健全的通知機制。
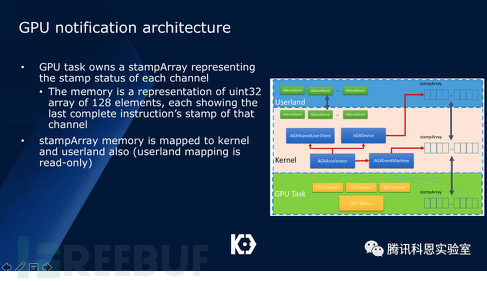
首先GPU會映射一個128個元素的stampArray給kernel,kernel也會把這塊內存映射到用戶態。與此同時,內核也維護了一個stamp address array,用于保存每個channel的stamp地址:

值得注意的是,GPU每處理完一個繪圖指令后,都會將對應channel的stamp值加1。另一方面,對于每個繪圖指令,都會有一個期望stamp值,這個值被封裝于IOAccelEvent對象中:

系統通過簡單的比較expectStamp于當前channel的stamp值就可以確定這個繪圖指令是否已經完成。為了提高處理效率,部分IOAccelEvent對象會被映射到用戶態,屬性只讀。
在介紹完了所有這些機制性的問題后,我們來介紹兩個用于Jailbreak的關鍵漏洞。漏洞1存在于DMA映射模塊,先前提到,系統的內存屬性mapOption會被傳入底層DART的代碼中,然而在iOS 10以及早期的iOS 11版本中,這個mapOption參數被下層的DART轉換所忽略:

所有操作系統中的虛擬地址,都會被映射成IOSpace中允許讀寫的內存:

之后我們介紹第二個漏洞,這個漏洞存在于蘋果圖形模塊中。在IOAccelResource對象創建過程中,一個IOAccelClientShareRO對象會被映射到用戶態作為只讀內存,這個對象包含4個IOAccelEvent對象:
在IOAccelResource對象銷毀過程中,testEvent函數會被執行,用于測試IOAccelResource對應的繪圖指令是否已經被GPU處理完成:

在這個代碼邏輯中,由于內核充分信任這塊IOAccelEvent內存不會被用戶態程序篡改(因為是只讀映射),因此并沒有對channelIndex做邊界檢查。這雖然在絕大多數情況下是安全的,但如果我們配合漏洞1,在用戶態直接修改這塊只讀內存,就會導致可信邊界被徹底破壞,從而造成m_stampAddressArray的越界讀以及m_inlineArray的越界寫:

最后,我們討論兩個漏洞的利用。要利用這兩個漏洞并不容易,因為我們需要找到一種內存布局方法,讓m_stampAddressArray以及m_inlineArray這兩個數組的越界值都可控。但因為這兩個數組在系統啟動初期就已經分配,而且這兩個數組的元素大小并不相同,因此布局并不容易。

經過研究,我們發現,只有通過指定大index以及合理的內核對噴,才能實現這樣的布局。因為在iPhone7設備中,用戶態應用可以噴射大概350MB的內存,并且在m_stampAddressArray以及m_inlineArray初始化后,會有額外50MB的內存消耗,因此我們需要使得index滿足以下兩個條件:
- index ∗ 24 < 350MB + 50MB
- index ∗ 8 > 50MB
也就是說index的值需要在[0x640000, 0x10AAAAA]這個范圍內,可以使得兩個數組的越界值極大概率在我們可控的噴射內存內:
然后,下一個問題就是,我們是否能夠任意地址讀以及任意地址寫。對于任意地址讀似乎不是什么問題,因為m_stampAddressArray的元素大小是8字節,可以通過指定任意index到達任意內存地址。但任意地址寫需要研究,因為m_inlineArray的元素大小是24字節,只有一個field可以用于越界寫,所以不是每個內存地址都可以被寫到:

在這種情況下,我們退求其次,如果能實現對于一個頁中的任意偏移值進行寫操作,那么也可以基本達到我們的要求。在這里,我們需要通過同余定理來實現:

因為:
- 0xc000 ≡ 0(mod0x4000)
因此對于任意整數n,滿足:
- n ∗ 0×800 ∗ 24 ≡ 0(mod0x4000)
由于0×4000 / 24 * 0xF0 / 16 = 0x27f6,我們得到:
- 0xF0 + 0x27f6 ∗ 24 + n ∗ 0×800 ∗ 24 ≡ 0(mod0x4000)
最后我們得出結論,如果需要通過越界m_inlineArray寫到一個頁的前8字節,需要滿足:
- index = 0x27f6 + n ∗ 0×800
而如果需要到達任意頁內偏移,假設要到達偏移m,則index需要滿足條件:
- index = 0x27f6 + 0x2ab ∗ m/8 + n ∗ 0×800

與之前得出的index范圍結論相結合,我們最終選擇了index值0x9e6185:

然后我們通過以下幾個步驟進行漏洞利用,在第一個布局中,我們得出Slot B與Slot C的index值:
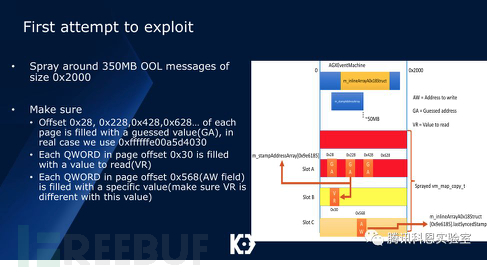
隨之我們將slot B填入相同大小的AGXGLContext對象,然后再次利用漏洞泄露出其vtable的第四位:
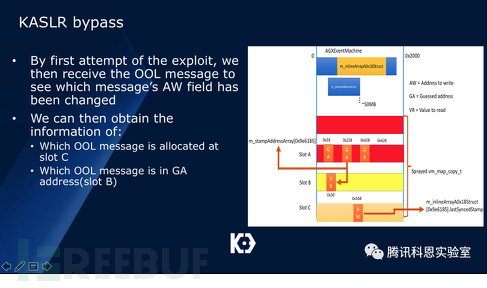
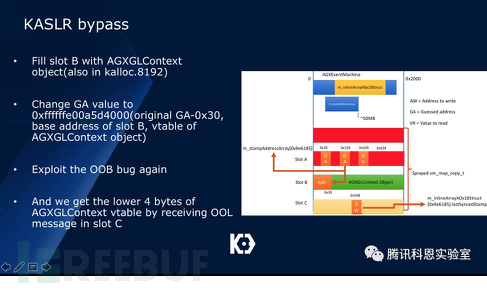
最后我們通過將Slot C釋放并填入AGXGLContext對象,將其原本0×568偏移的AGXAccelerator對象改為我們可控的內存值,實現代碼執行:

最后,整個利用流程總結如下:
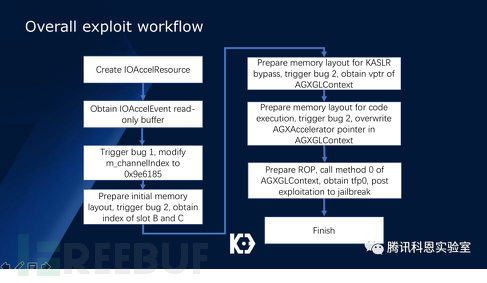
在通過一系列ROP后,我們最終拿到了TFP0,但這離越獄還有一段距離:繞過AMFI,rootfs的讀寫掛載、AMCC/KPP繞過工作都需要做,由于這些繞過技術都有公開資料可以查詢,我們這里不作詳細討論:

最后,我們對整條攻擊鏈作了總結:
- 在iOS 11的第一個版本發布后,我們的DMA映射漏洞被修復;
- 但是蘋果圖形組件中的越界寫漏洞并沒有被修復;
- 這是一個”設計安全,但實現并不安全”的典型案例,通過這一系列問題,我們將這些問題串聯起來實現了復雜的攻擊;
- 也許目前即便越界寫漏洞不修復,我們也無法破壞重新建立起來的只讀內存可信邊界;
- 但是至少,我們通過這篇文章,證明了可信邊界是可以被打破的,因為用戶態只讀映射是”危險”的;
- 也許在未來的某一天,另一個漏洞的發現又徹底破壞了這樣的可信邊界,配合這個越界寫漏洞將整個攻擊鏈再次復活。這是完全有可能的。















