Ceph存儲后端ObjectStore架構和技術演進
Ceph是分布式和強一致性的軟件定義存儲產品,隨著越來越多的企業和組織不斷加入,Ceph存儲系統穩定性、可靠性和易管理性得到了很大的提升,在版本演進和迭代中,Ceph存儲的企業特性也得到了完善。如CephFS、iSCSI協議、InfiniBand網絡等特性,但今天筆者將帶領大家深入分析下Ceph***后端存儲BlueStore的架構和ObjectStore歷史技術演進,因為存儲后端的架構在一定程度上決定Ceph存儲系統的性能。SUSE也是在***Enterprise Storage 5版本中率先支持***的BlueStore后端存儲技術。
BlueStore是Ceph存儲后端ObjectStore的***實現。在Ceph系統中,數據首先通過Hash算法分布到每個節點OSD上,最終由ObjectStore寫到磁盤上實現數據保存和持久化。那么,首先來看看ObjectStore架構。
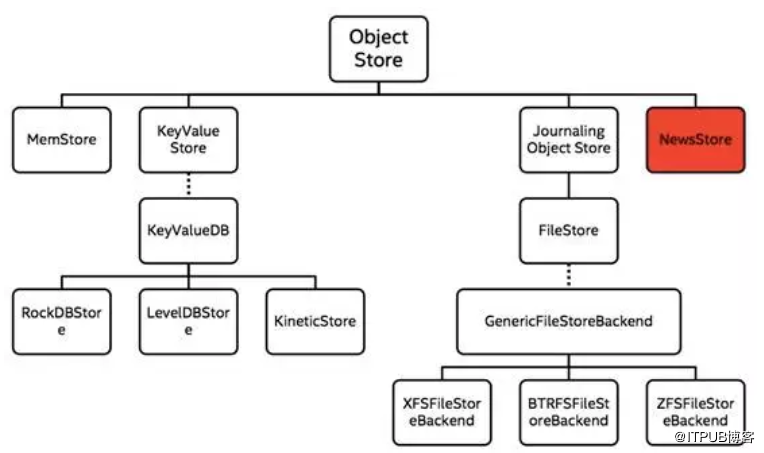
ObjectStore架構介紹
Ceph后端支持多種存儲引擎,這些存儲后端模塊是以插件式的方式被管理,目前支持的實現方式包括Filestore(默認存儲后端),KeyValue Store、Memstore、NewStore和***的Bluestore。
從架構上來看,ObjectStore封裝了下層存儲引擎的所有IO操作,并向上層提供對象(Object)、事務(Transaction)語義接口。在這里,MemStore是基于內存的實現存儲接口功能;KeyValue Store主要基于KV數據庫(如LevelDB,RocksDB等)實現接口功能。
一直以來,FileStore是Ceph目前默認的ObjectStore后端存儲引擎(仍然是其他Ceph存儲的默認后端),FileStore基于Journal機制實現了事務處理能力,除了支持事務特性(consistency、atomic等)以外,Journal還可將多個小IO寫合并為順序寫Journal來提升系統性能。
ObjectStore接口主要包括三個部分,***部分是Object的讀寫操作,類似于POSIX的部分接口;第二部分是Object的屬性(xattr)讀寫操作,這類操作是KV操作,它與某一個Object關聯;第三部分是關聯Object的KV操作(在Ceph中稱為omap)。
ObjectStore后端存儲引擎之FileStore
FileStore是利用文件系統的Posix接口實現ObjectStore API。每個Object在FileStore層會被看成是一個文件,Object的屬性(xattr)會利用文件的xattr屬性進行存取,由于有些文件系統(如ext4)對xattr的長度有限制,因此,在FileStore中,超出長度限制的Metadata會被存儲在DBObjectMap里。而Object的KV關系則直接利用DBObjectMap功能實現。
但是FileStore存在一些問題,例如Journal機制使一次寫請求在OSD端往下寫時,變為兩次寫操作(同步寫Journal,異步寫入Object);當然,可以通過SSD實現Journal可緩解Journal和object寫操作的性能影響;寫入的每個Object都對應OSD本地文件系統的一個物理文件,對于大量小Object存儲場景來說,OSD端無法緩存本地所有文件的元數據,這使讀寫操作可能需要多次本地IO操作,系統性能差等。
ObjectStore后端存儲引擎之NewStore
為了解決上述FileStore的問題,Ceph引入了新的存儲引擎NewStore(又被稱為KeyFile Store),其關鍵結構如下圖所示:
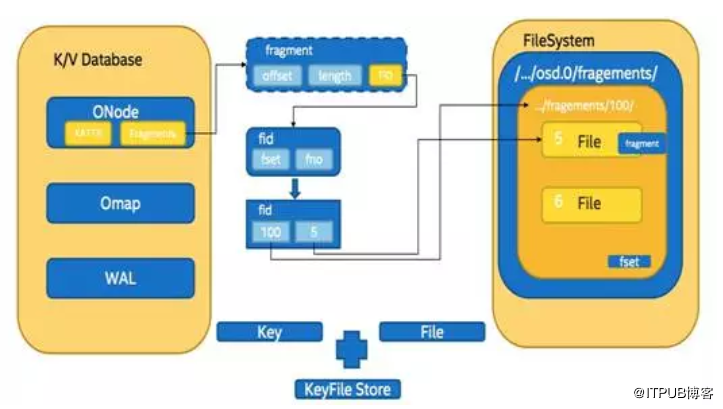
NewStore解耦Object與本地物理文件間的一一對應關系,通過索引結構(上圖中ONode)在Object和本地物理文件建立映射關系,并使用KV數據庫存儲索引數據;在保證事務特性的同時,對于Object的操作無需Journal支持;在KV數據庫上層建立Onode數據cache以加速讀取操作;單個Object可以有多個fragement文件,多個Object也可共存于一個fragement文件,更加靈活。
ObjectStore后端存儲引擎之BlueStore
NewStore使用RocksDB存儲Ceph日志,同時Ceph的真正數據對象存儲在文件系統中。如今有了BlueStore技術,數據對象可以無需任何文件系統的接口支持,而是直操作存儲在物理磁盤設備上的數據。
BlueStore初衷就是為了減少寫放大,并針對SSD做優化,直接管理裸盤(物理磁盤設備),從理論上來講,進一步規避了如ext4、xfs等文件系統部分的開銷,BlueStore是一個全新的 OSD存儲后端,通過塊設備提升存儲性能。Bluestore整體架構如下。
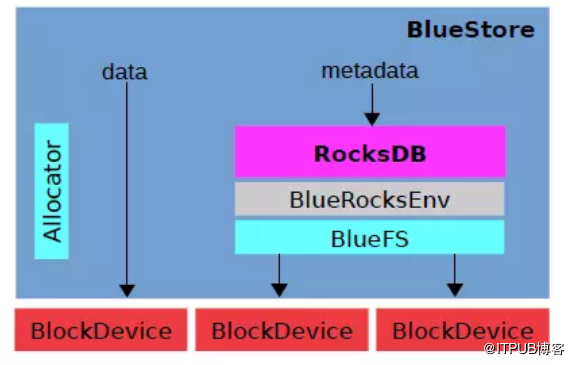
BlueStore直接管理裸設備,拋棄了本地文件系統,BlockDevice實現在用戶態下直接對裸設備進行I/O操作。既然是直接管理裸設備就必然需要進行裸設備的空間管理,對應的就是Allocator,目前支持Stupid Allocator和Bitmap Allocator兩種分配器。
相關的元數據以KV的形式保存到KV數據庫里,默認使用的是RocksDB,RocksDB本身雖然是基于文件系統,不能直接操作裸設備,但是RocksDB可將系統相關的處理抽象成Env,用戶可用實現相應的接口來操作。
RocksDB默認的Env是PosixEnv,直接對接本地文件系統。為此Bluestore實現了一個BlueRocksEnv來為RocksDB提供底層系統的封裝,實現了一個小的文件系統BlueFS對接BlueRocksEnv,在系統啟動掛載這個文件系統的時候,將所有的元數據都加載到內存中,BluesFS的數據和日志文件都通過BlockDevice保存到裸設備上,BlueFS和BlueStore可以共享裸設備,也可以分別指定不同的設備。
當BlueFS和BlueStore共享設備時,裸設備通常被分為兩部分:
設備的一部分為BlueFS的小分區,它實現了RocksDB所需的類似文件系統的功能。
設備的其余部分通常是占據設備其余部分的大分區。它由BlueStore直接管理,包含所有實際數據。
在Filestore存儲引擎里,對象的表現形式是對應到文件系統里的文件,默認4MB大小的文件,但是在目前***的ObjectStore實現——Bluestore里,已經沒有傳統的文件系統,而是自己管理裸盤,要求管理對象Onode需要常駐內存的數據結構中,持久化的時候會以KV的形式存到RocksDB里。
總結一下,從SUSE Enterprise storage 5存儲版本開始,BlueStore成為Ceph的一個新的存儲后端,它的性能優于FileStore,并提供完整的數據檢驗和和內置壓縮能力。
FileStore將數據保存到與Posix兼容的文件系統(例如Btrfs、XFS、Ext4)。在Ceph后端使用傳統的Linux文件系統盡管提供了一些好處,但也有代價,如性能、 對象屬性與磁盤本地文件系統屬性匹配存在限制等。
然而,NewStore存儲后端技術 解耦Object與本地物理文件間的對應關系,通過KV數據庫、索引技術優化日志操作。
B lueStore可使 數據對象無需任何文件系統的接口,就可以直接存儲在物理塊設備上,所以,B lueStore可以 極大的提升Ceph存儲系統性能。