













如何實現全文檢索功能之搜索之路
引子
時間回到20年前。
張大胖學校的圖書館網站上線了,張大胖去瀏覽了一番,發現竟然沒有按照關鍵字搜索圖書的功能,大為吃驚之余,又隱約覺得機會來了: 我剛學完Web開發,其中也有數據庫相關的知識,也許我可以實現這個功能啊!
想到此處,張大胖趕緊查找聯系方式,抱著試試看的態度給圖書館的管理員發了一封電子郵件,表達了能實現這個搜索功能的信心和決心。
沒想到真的收到回信了,管理員王老師讓他在周四的下午2點半到圖書館3樓307聊一聊。
周四下午,張大胖沐浴更衣以后,如約而至。 經過一番寒暄和介紹,王老師正式進入主題:你打算怎么實現這個全文檢索功能啊?
張大胖說:“我可以用SQL的 Like來實現。”
王老師笑了:“數據量小的時候Like還湊合,數據量一大,效率就非常低了。”
張大胖有點蒙:“那怎么辦?”
王老師說:“得用inverted index才行。”
張大胖知道什么是index, 但是從來沒有聽說過inverted index,這是什么鬼?
王老師看到他迷茫的臉色,就知道這小子雖然勇氣可嘉,但是技術還是有所欠缺,鼓勵到:“這樣吧,你回去研究研究inverted index, 然后再來實現這個全文檢索功能。”
Inverted Index
張大胖灰溜溜地回到宿舍,趕緊撥號上網去查這個inverted index。
張大胖發現有很多人把他翻譯成倒排索引,聽起來雖然有點古怪,但實際上是一個非常簡單的概念。 比如說有兩篇文檔:
文檔1的內容:A computer is a device that can execute operations
文檔2的內容:Early computers are big devices
把這兩篇文章中的單詞都抽取出來,并且記錄下這些單詞出現在哪個文檔中,這就形成了一個簡單粗糙的倒排索引。
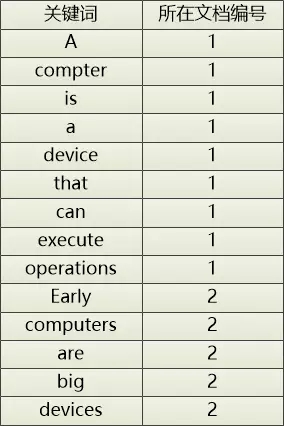
通過這個“倒排索引”,只要給出一個單詞,就可以迅速地定位到它在哪個文檔中。 用來做全文搜素非常合適。
但是上面的倒排索引有點“粗糙”,還可以在“精化”一下。
1. 對于 a, is , to ,that ,can ,the,are 這些詞對搜索來說沒什么意義,用戶幾乎不會用他們搜索,可以過濾掉。
2. 用戶搜索的時候雖然輸入了computer,但是也希望搜出computers出來,所以需要把復數單詞,過去式單詞等做還原。
3. 用戶雖然輸入了device , 但是也希望搜索出Device出來,所以需要把大寫都改成小寫。
經過這番轉換,文檔1和文檔2的關鍵字變成了這樣:
文檔1:[computer] [device] [execute] [operation]
文檔2:[early] [computer] [big] [device]
相應地,倒排索引變成了這樣:
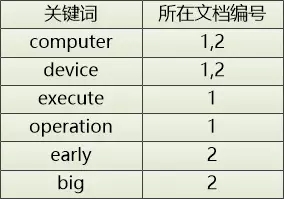
當用戶想搜索device 的時候,我們就可以告訴它,在文檔1和文檔2中都有。
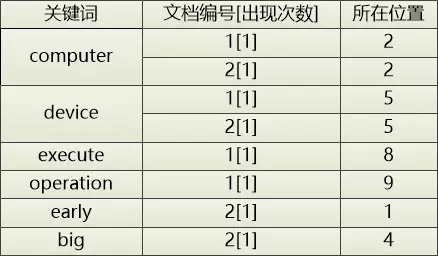
為了更好的統計和高亮顯示搜索結果,還可以記錄關鍵詞在文章中出現的次數和位置(例如:是第幾個單詞)
架構
明白了inverted index是怎么回事兒, 張大胖覺得只要把那些書籍的標題,介紹,作者等信息給提取出來,形成inverted index,不就可以做關鍵字檢索了嗎?
可是轉眼一想,這個需求應該是個通用的需求,不僅是圖書館有,很多互聯網應用,例如網上商城也需要, 我完全可以設計一個類庫出來,讓大家去使用啊。
張大胖迅速畫出一個架構圖出來:
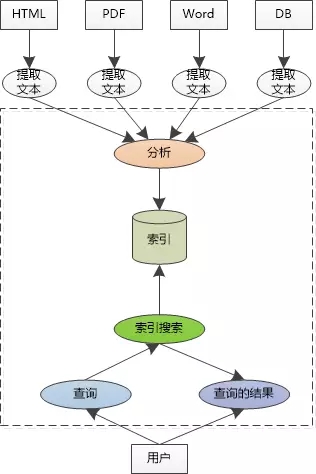
看看,不管你是什么類型的文檔,HTML, PDF, Word,甚至是數據庫的數據,只要能從中抽取出文本,就可以當作我的數據源,對文本做了分析以后,就可以存入索引庫。
用戶可以發出各種查詢,不僅僅是單個關鍵字,還支持關鍵字的組合: keyword1 AND keyword2等,對索引庫進行搜索以后,把結果返回給用戶。
“中間用虛線框起來的部分就是我應該實現的類庫!” 張大胖對這個架構很滿意。
抽象
接下來就要考慮這個類庫對外提供的API了,這是個很煩人的事情。 張大胖的腦海中不由地想起來好基友Bill的諄諄教導:“軟件設計就是一個不斷抽象的過程。”, 關鍵是要抽象啊!
可是這個系統似乎有點復雜,張大胖絞盡腦汁想了兩天也沒有頭緒,對于一個剛學會Web開發的同學,立刻就要設計類庫,確實是有點勉為其難。
沒辦法,張大胖只好致電Bill前來幫忙。
Bill對張大胖的痛苦表示了親切的慰問, 又對架構圖表示了適度的贊賞。 他說: “既然有HTML,PDF, Word文檔, 很自然,你可以做一個Document的抽象!”
“好像不行吧? 如果數據源是數據庫,怎么變成Document? ”
“很簡單, 比如一行數據就可以映射到一個Document。 當然,這個轉化必須得有程序員來完成。程序員決定什么東西是Document。” Bill說。
“Document中有什么東西? ”
“嗯,Document可以有很多屬性,每個屬性都有名稱和值, 我可以把屬性叫做Field。比如一個HTML文檔,可能有path, title,content等多個Field,其中path可以唯一地標志這個文檔, title和content需要做進行分詞,形成倒排索引,讓用戶搜索。” Bill回答。

(一個包含多個Field的Document)
“用戶創建了Document和Field以后,就可以進行分析了原始的內容劃分成一個個Term,” 張大胖開始開竅,“這樣,我可以定義一個Analyzer的抽象類,讓別的程序可以擴展它。”
“對,分析的結果可以加入索引庫,這個操作可以讓一個單獨的類,比如IndexWriter類來完成。” Bill 說。
“可是IndexWriter如何知道索引應該存在什么地方? 內存? 文件系統?”
“那就再來一個抽象的概念:Directory,表示索引文件的存儲。”
張大胖怕忘記,趕緊畫類圖:
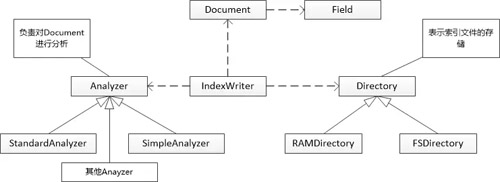
“看起來還是挺漂亮的嘛!” 張大胖說。
“好的設計一般都比較漂亮。” Bill 來了一句至理名言。
“對于對于用戶搜索來說,肯定得有個叫做Query的東西,用來表達用戶的搜索要求。當然,這個Query也應該允許擴展。 ” 張大胖嘗試著抽象。
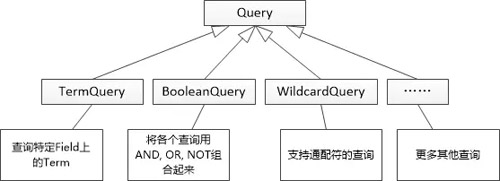
“但是這些類使用起來還是比較麻煩, 最好是支持用戶輸入字符串來表達搜索的意圖:(computer or phone) and price” Bill還是經驗老道,“必須得有個解析器來完成從字符串到Query的轉化,然后我們讓IndexSearcher 來接收Query,就可以實現搜索的功能了。 ”

張大胖很興奮,一個復雜的系統,就這么被搞定了,雖然其中有很多細節沒有覆蓋,但大的方向已經確定, 細節在具體的開發中來處理吧。
他摩拳擦掌,準備大干一場,把這個設計給實現了。
可是Bill在網上搜索了一會兒,潑了一盆冷水:“大胖,好像有個叫做Lucene的開源系統,和我們的設計很像啊,功能更加強大,要不你就用它這個實現吧。”
張大胖趕緊跑到電腦前去看,果然,這個叫Lucene的家伙實現得非常完善,還有很多高級的功能,比如僅僅是“相似度”這個功能,非得對搜索有深入研究才行,自己是望塵莫及。
他嘆了一口氣說:“好吧,我去圖書館找王老師,就用這個Lucene吧!”
三年以后
張大胖已經變成了利用Lucene做搜索的高手,各種細節和最佳實踐盡在掌握。隨著互聯網應用的爆炸式增長,搜索變成了一個常見的需求,他甚至在業余時間專門去給人做Lucene的咨詢,賺了不少外快。
但是做得多了,張大胖也覺得很煩,這個Lucene用起來實在是太“低級”,很多人向他抱怨: 我就想搜索一下我的商品描述,現在還得理解什么“Directory”,"Analyzer","Query",實在是太復雜了! 還有我們的數據越來越多,索引也越來占的空間也越來越大,怎么才能實現分布式的存儲啊?
這樣的抱怨聽多了,張大胖心想:是時候對Lucene做一層封裝,提供一個簡單的API了......
后記:接下來還可以講一下Elastic Search ,也不知道大家是否感興趣,再加上這篇文章已經很長了,就停筆了。 如果各位感興趣的,留言告訴我一下,我會繼續寫下去。

【本文為51CTO專欄作者“劉欣”的原創稿件,轉載請通過作者微信公眾號coderising獲取授權】















