5個大數據處理/數據分析/分布式工具
1.Hadoop
Hadoop是一個開源框架,它允許在整個集群使用簡單編程模型計算機的分布式環境存儲并處理大數據。它的目的是從單一的服務器到上千臺機器的擴展,每一個臺機都可以提供本地計算和存儲。
2.Druid
Druid是實時數據分析存儲系統,Java語言中***的數據庫連接池。Druid能夠提供強大的監控和擴展功能。
Druid是一個分布式的、面向列的、實時的分析數據存儲庫,通常用于為多租戶環境中的探索性儀表板供電。
Druid作為一種數據倉庫解決方案,擅長于對petabyte大小的數據集進行快速聚合查詢。Druid支持各種靈活的過濾器、精確計算、近似算法和其他有用的計算。
Druid可以同時加載流數據和批處理數據,并與Samza、Kafka、Storm、SPark和Hadoop集成。
3.Ambari
大數據平臺搭建、監控利器;類似的還有CDH
Ambari能夠:
提供Hadoop集群
- Ambari為在任意數量的主機上安裝Hadoop服務提供了一個逐步向導。
- Ambari處理集群Hadoop服務的配置。
管理Hadoop集群
- Ambari為整個集群提供啟動、停止和重新配置Hadoop服務的中央管理。
監視Hadoop集群
- Ambari為監視Hadoop集群的健康狀況和狀態提供了一個儀表板。
- 安巴里杠桿Ambari度量系統用于度量集合。
- 安巴里杠桿Ambari警報框架用于系統警報,并在需要注意時通知您(例如,節點下降,剩余磁盤空間較低等)。
4.Spark
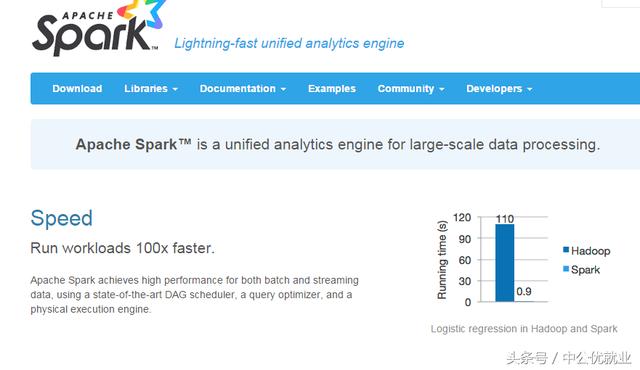
一個快速通用的集群計算系統.它在Java、Scala、Python和R中提供了高級API,并提供了支持通用執行圖的優化引擎。大規模數據處理框架(可以應付企業中常見的三種數據處理場景:復雜的批量數據處理(batch data processing);基于歷史數據的交互式查詢;基于實時數據流的數據處理,Ceph:Linux分布式文件系統。
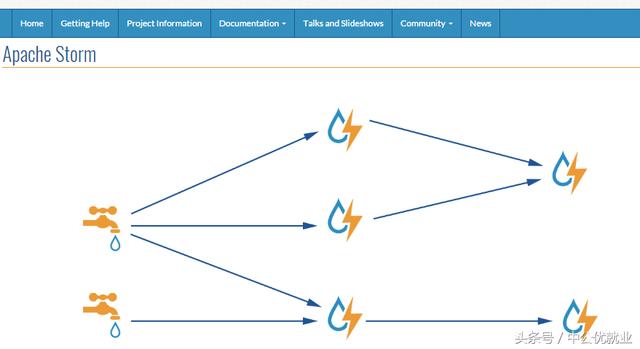
5.Storm
Storm是一個免費開源、分布式、高容錯的實時計算系統。Storm令持續不斷的流計算變得容易,彌補了Hadoop批處理所不能滿足的實時要求。Storm經常用于在實時分析、在線機器學習、持續計算、分布式遠程調用和ETL等領域。Storm的部署管理非常簡單,而且,在同類的流式計算工具,Storm的性能也是非常出眾的。