六個大數據采集工具架構分析
隨著大數據越來越被重視,數據采集的挑戰變的尤為突出。今天為大家介紹幾款數據采集平臺:Apache Flume、Fluentd、Logstash、Chukwa、Scribe、Splunk Forwarder。
大數據平臺與數據采集
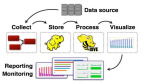
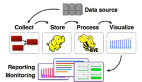
任何完整的大數據平臺,一般包括以下的幾個過程:
- 數據采集
- 數據存儲
- 數據處理
- 數據展現(可視化,報表和監控)
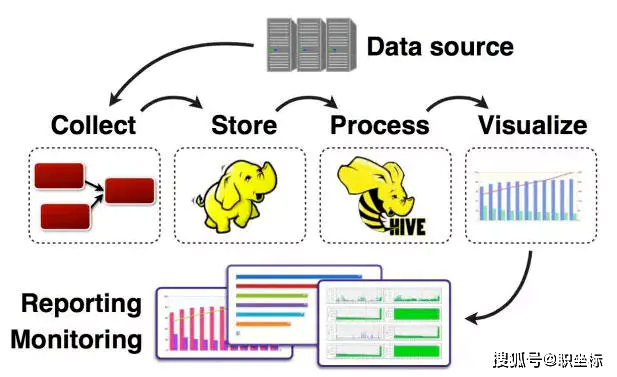
其中,數據采集是所有數據系統必不可少的,隨著大數據越來越被重視,數據采集的挑戰也變的尤為突出。這其中包括:
- 數據源多種多樣
- 數據量大,變化快
- 如何保證數據采集的可靠性的性能
- 如何避免重復數據
- 如何保證數據的質量
我們今天就來看看當前可用的六款數據采集的產品,重點關注它們是如何做到高可靠,高性能和高擴展。
01、Apache Flume
Flume 是Apache旗下的一款開源、高可靠、高擴展、容易管理、支持客戶擴展的數據采集系統。
Flume使用JRuby來構建,所以依賴Java運行環境。
Flume最初是由Cloudera的工程師設計用于合并日志數據的系統,后來逐漸發展用于處理流數據事件。
幾乎在大部分的情況下ELK作為一個棧是被同時使用的。所有當你的數據系統使用ElasticSearch的情況下,logstash是首選。
02、Chukwa
Apache Chukwa是apache旗下另一個開源的數據收集平臺,它遠沒有其他幾個有名。Chukwa基于Hadoop的HDFS和MapReduce來構建(顯而易見,它用Java來實現),提供擴展性和可靠性。Chukwa同時提供對數據的展示,分析和監視。很奇怪的是它的上一次github的更新事7年前。可見該項目應該已經不活躍了。
Chukwa的部署架構如下:
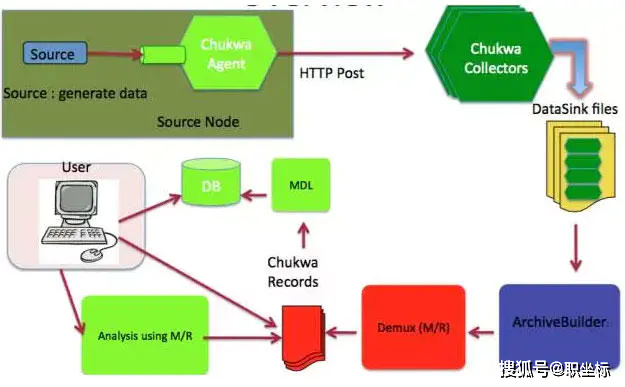
Chukwa的主要單元有:Agent,Collector,DataSink,ArchiveBuilder,Demux等等,看上去相當復雜。由于該項目已經不活躍,我們就不細看了。
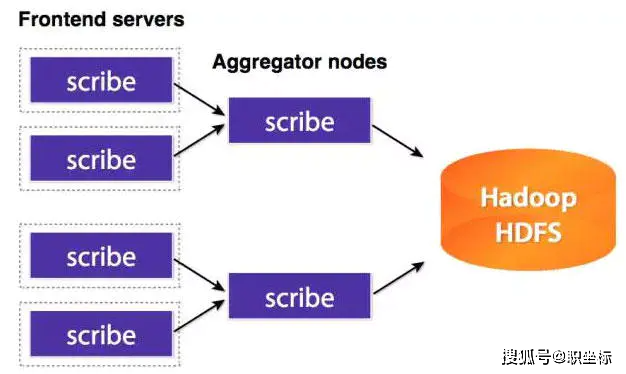
03、Scribe
Scribe是Facebook開發的數據(日志)收集系統。已經多年不維護,同樣的,就不多說了。
04、Splunk Forwarder
以上的所有系統都是開源的。在商業化的大數據平臺產品中,Splunk提供完整的數據采金,數據存儲,數據分析和處理,以及數據展現的能力。
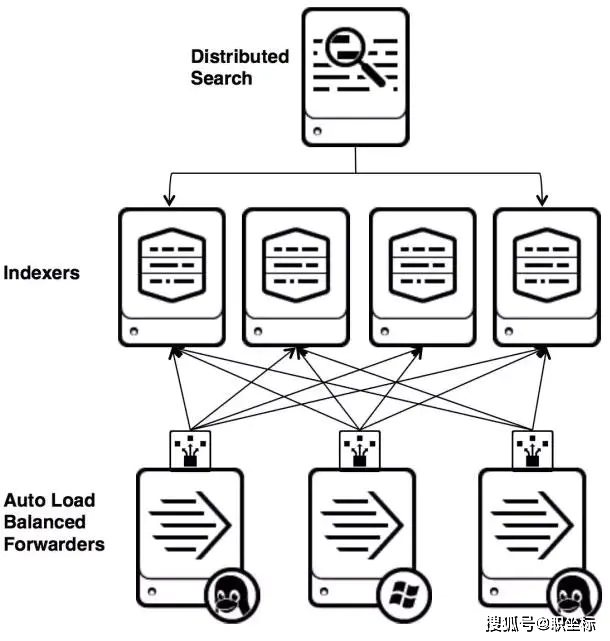
Splunk是一個分布式的機器數據平臺,主要有三個角色:
- Search Head負責數據的搜索和處理,提供搜索時的信息抽取。
- Indexer負責數據的存儲和索引
- Forwarder,負責數據的收集,清洗,變形,并發送給Indexer
Splunk內置了對Syslog,TCP/UDP,Spooling的支持,同時,用戶可以通過開發Script Input和Modular Input的方式來獲取特定的數據。在Splunk提供的軟件倉庫里有很多成熟的數據采集應用,例如AWS,數據庫(DBConnect)等等,可以方便的從云或者是數據庫中獲取數據進入Splunk的數據平臺做分析。
這里要注意的是,Search Head和Indexer都支持Cluster的配置,也就是高可用,高擴展的,但是Splunk現在還沒有針對Farwarder的Cluster的功能。也就是說如果有一臺Farwarder的機器出了故障,數據收集也會隨之中斷,并不能把正在運行的數據采集任務Failover到其它的Farwarder上。
總結
我們簡單討論了幾種流行的數據收集平臺,它們大都提供高可靠和高擴展的數據收集。大多平臺都抽象出了輸入,輸出和中間的緩沖的架構。利用分布式的網絡連接,大多數平臺都能實現一定程度的擴展性和高可靠性。
其中Flume,Fluentd是兩個被使用較多的產品。如果你用ElasticSearch,Logstash也許是首選,因為ELK棧提供了很好的集成。Chukwa和Scribe由于項目的不活躍,不推薦使用。
Splunk作為一個優秀的商業產品,它的數據采集還存在一定的限制,相信Splunk很快會開發出更好的數據收集的解決方案。