數(shù)據(jù)庫的這些性能優(yōu)化,你做了嗎?
在互聯(lián)網(wǎng)項目中,當(dāng)業(yè)務(wù)規(guī)模越來越大,數(shù)據(jù)也越來越多,隨之而來的就是數(shù)據(jù)庫壓力會越來越大。
我們可能會采取各種方式去優(yōu)化,比如之前文章提到的緩存方案,SQL優(yōu)化等等,除了這些方式以外,這里再分享幾個針對數(shù)據(jù)庫優(yōu)化的常規(guī)手段:「數(shù)據(jù)讀寫分離」與「數(shù)據(jù)庫Sharding」。這兩點基本上是大中型互聯(lián)網(wǎng)項目中應(yīng)用的非常普遍的方案了。
下面我們來詳細看一看,
一、從讀寫分離到CQRS
據(jù)庫的這些性能優(yōu)化,你做了嗎?")
(圖片來源阿里云)
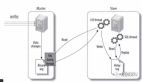
由于互聯(lián)網(wǎng)業(yè)務(wù)場景,大多數(shù)是讀多寫少,因此進行數(shù)據(jù)庫的讀寫分離是一件非常簡單且有效率的方案。
讀寫分離簡單點來說就是把對數(shù)據(jù)的讀操作和寫操作進行分開來,讓這兩種操作去訪問不同的數(shù)據(jù)庫,這樣的話,就可以減輕數(shù)據(jù)庫的壓力了。
例如上圖中,數(shù)據(jù)庫會有一個「主實例」,這個主要用來提供寫操作的(偶爾也會承擔(dān)一點讀操作),除了「主實例」以外,還會有多個「從實例」(在圖中顯示的是 只讀實例),「從實例」的功能只是用來承擔(dān)讀操作的。
那上面就出現(xiàn)了多個數(shù)據(jù)庫了,在多個數(shù)據(jù)庫之間的數(shù)據(jù)是怎么保證一致性的呢?
其實,我們常用的數(shù)據(jù)庫就自帶這類同步功能,比如 Mysql,它自己有一個master-slave功能,可以實現(xiàn)主庫與從庫數(shù)據(jù)的自動同步,是基于二進制日志復(fù)制來實現(xiàn)的。在主庫進行的寫操作,會形成二進制日志,然后Mysql會把這個日志異步的同步到從庫上,從庫再自動執(zhí)行一遍這個二進制日志,那么數(shù)據(jù)就跟主庫一致了。
除了Mysql以外,像Oracle等商業(yè)數(shù)據(jù)庫都有類似的功能,甚至是網(wǎng)絡(luò)上還有很多開源的第三方數(shù)據(jù)同步工具,也有很多成熟好用的。
好了,「主實例」與「從實例」之間的數(shù)據(jù)同步問題解決了,那現(xiàn)在還有一個問題就是,項目中是怎樣讓 寫請求 去訪問「主實例」,讓 讀請求 去訪問「從實例」的,這個路由規(guī)則是怎么實現(xiàn)的呢?
常規(guī)的有2種方式:
使用編碼方式
這個方式主要是靠開發(fā)同學(xué)在編碼的時候,根據(jù)讀寫不同的操作需求,去調(diào)用不同的數(shù)據(jù)源。例如在數(shù)據(jù)操作層(DAO層)將讀數(shù)據(jù)與寫數(shù)據(jù)分開為兩個方法(函數(shù)),然后為這兩個方法分別指定不同的數(shù)據(jù)庫即可。
但是這種方式有點硬編碼的味道了,而且對開發(fā)同學(xué)而言還得額外關(guān)注這個事情,多了一個編碼成本且容易不小心忽略掉。
使用中間件
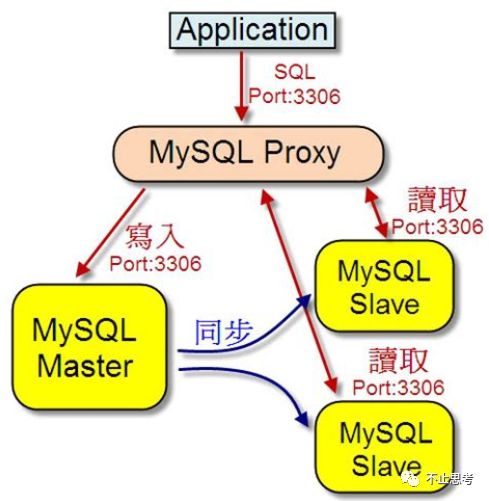
這種方式就是在后端數(shù)據(jù)庫的前面,前置一個 數(shù)據(jù)庫代理服務(wù),如下圖的:MySQL-Proxy 是Mysql提供的一個中間件,用于實現(xiàn)讀寫分離請求,但這個組件實際用的人不多,我們可以選擇其它的一些開源的組件替代,例如:MyCat、ProxySQL 等等,但大致的原理比較類似,通過這個圖很容易理解這個模式。
好了,基礎(chǔ)的讀寫分離就講完了,但感覺這個方式雖然實用是實用,就是不怎么有逼格。
OK,想要有逼格是吧,滿足你,那我們就來聊一聊另一個有逼格的讀寫分離概念: 「 CQRS 」
CQRS:Command Query Responsibility Segregation
命令(增刪改)和查詢的責(zé)任分離
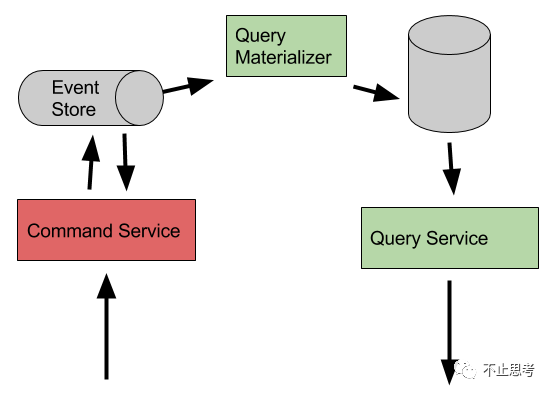
我們還是先看圖,通過上圖可以簡單的理解一下CQRS
CQRS 重點強調(diào)的就是 Query(讀) 和 Command(寫)的分離,在業(yè)務(wù)上將職責(zé)分離清晰,Command 主要做業(yè)務(wù)邏輯的執(zhí)行,Query來負責(zé)數(shù)據(jù)查詢和展示。同時 這兩種操作是基于不同的數(shù)據(jù)源,甚至是一個是數(shù)據(jù)庫,另外一個是NoSQL都可以,Query去查詢的數(shù)據(jù)源可以直接按照領(lǐng)域模型進行存儲,而并不是按照數(shù)據(jù)模型去存儲,這樣查詢出來就立即可以展示,而不用轉(zhuǎn)換,且查詢效率高。
其實CQRS是由鼎鼎大名的 Martin Fowler 提出,搞計算機的應(yīng)該都認識。想要更深入的去學(xué)習(xí)CQRS,可以翻看Martin Fowler公開的資料。
二、Sharding(分庫分表)
上面講完了數(shù)據(jù)庫的讀寫分離,現(xiàn)在我們來聊一下數(shù)據(jù)庫的Sharding。
隨著數(shù)據(jù)庫里的數(shù)據(jù)越來越大,單表查詢的性能已經(jīng)不能滿足業(yè)務(wù)要求了,這個時候就需要進行分表處理了,將大表拆分為若干個小表,不同的分表中數(shù)據(jù)也不一樣,這樣可以分散查詢壓力,提高處理效率。
然而,當(dāng)表越來越多,所有的數(shù)據(jù)都在一個數(shù)據(jù)庫上時,網(wǎng)絡(luò)IO以及文件IO也都會集中在一個數(shù)據(jù)庫上,可能會超過單臺服務(wù)器的容量, CPU、內(nèi)存、文件IO、網(wǎng)絡(luò)IO 都會成為系統(tǒng)的瓶頸,QPS/TPS也會超過單數(shù)據(jù)庫實例的處理極限。那么這個時候就需要對數(shù)據(jù)庫進行分片處理。
因為分表和分庫的思路類似,因此下面統(tǒng)一來聊技術(shù)方案。
其實分庫分表只是我們通俗的便于理解的說話,正確的描述應(yīng)該是:數(shù)據(jù)分片
數(shù)據(jù)的分片主要有2種模式:
- 垂直拆分
- 水平拆分
兩種拆分應(yīng)用的場景是不同的:
垂直拆分,是指按照業(yè)務(wù)模塊進行拆分。簡單來講,就是把業(yè)務(wù)緊密的模塊的字段/表放在一起,放在同一個數(shù)據(jù)庫或者服務(wù)器上。將不同業(yè)務(wù)的字段/表進行獨立,拆到不同的數(shù)據(jù)庫或者服務(wù)器上。比如一個游戲系統(tǒng)中,可以將玩家基本信息與道具公會等信息進行拆分。
如圖示例:

(圖片來源網(wǎng)絡(luò))
水平拆分,是指純粹的按照某種數(shù)據(jù)規(guī)則/格式進行拆分。例如 按照數(shù)據(jù)唯一ID的哈希散列拆分、按照數(shù)據(jù)的日期拆分、按照某種范圍拆分等等。水平拆分需要注意的是,隨著數(shù)據(jù)動態(tài)的變化,分片數(shù)量可能需要隨之動態(tài)調(diào)整,另外就是水平分片是沒有考慮業(yè)務(wù)特征的,因此在進行業(yè)務(wù)匯總查詢或者分片中事物處理的時候就比較麻煩一些。
如圖示例:
據(jù)庫的這些性能優(yōu)化,你做了嗎?")
另外,在實際應(yīng)用中,兩種拆分模式一般會結(jié)合在一起使用,效果更佳。
以上就是數(shù)據(jù)庫性能優(yōu)化之「數(shù)據(jù)讀寫分離」與「數(shù)據(jù)庫Sharding」方法,歡迎大家一起交流。