













數(shù)據(jù)庫(kù)查詢(xún)性能優(yōu)化指南
數(shù)據(jù)庫(kù)查詢(xún)性能優(yōu)化一直是程序員繞不開(kāi)的話題,當(dāng)我們遇到業(yè)務(wù)刷新報(bào)表緩慢或者查詢(xún)獲取結(jié)果延遲太大,可以采用提問(wèn)法來(lái)思考如何進(jìn)行優(yōu)化。
1. 什么樣的環(huán)境
硬件環(huán)境
query執(zhí)行的速度和我們的硬件息息相關(guān),當(dāng)前用的什么樣的CPU,有多少核多少線程, 內(nèi)存有多大都直接影響了運(yùn)算速度, 磁盤(pán)是SSD還是HDD,網(wǎng)卡什么速率都直接影響了我們數(shù)據(jù)讀取的時(shí)延
軟件環(huán)境
軟件環(huán)境雖然不像硬件一樣,各種參數(shù)看的見(jiàn)摸得著,但仍然影響著我們的查詢(xún)性能。沒(méi)一套系統(tǒng)實(shí)際上都在特定的場(chǎng)景有著各自的優(yōu)勢(shì)。我們的查詢(xún)系統(tǒng)是什么樣的架構(gòu),適合什么樣的query,在線還是離線, 計(jì)算多還是數(shù)據(jù)讀取多,這些在我們做優(yōu)化的時(shí)候都應(yīng)該了然于心。
下面我們根據(jù)這種思路來(lái)看看如何做性能優(yōu)化
2. 什么樣的query
首先我們優(yōu)化查詢(xún)的時(shí)候,需要看看query 究竟是哪種類(lèi)型。寫(xiě)入還是查詢(xún)(這里鑒于篇幅只談查詢(xún)), CPU密集還是IO密集。如果我們的系統(tǒng)是適合OLTP低延時(shí)點(diǎn)查的場(chǎng)景, 想要在這種系統(tǒng)上做OLAP大規(guī)模分析很顯然就不太適合, OLTP一般專(zhuān)注于數(shù)據(jù)一致性較高的點(diǎn)查,而OLAP由于數(shù)據(jù)量龐大,一般都需要采用向量并發(fā)查詢(xún)。OLAP不專(zhuān)注于毫秒級(jí)的低延遲, 而OLTP不專(zhuān)注于上億級(jí)的數(shù)據(jù)統(tǒng)計(jì)。
3. 如何尋找性能瓶頸
3.1 vmstat查看系統(tǒng)情況
整體系統(tǒng)不知道當(dāng)前的瓶頸在哪里時(shí), 我們可以先用vmstat工具來(lái)簡(jiǎn)單的看一下系統(tǒng)的大致情況。如下圖所示,2表示每個(gè)兩秒采集一次服務(wù)器狀態(tài)。

procs : 查看進(jìn)程狀態(tài)
r : 運(yùn)行隊(duì)列,即當(dāng)前可運(yùn)行(正在運(yùn)行或者等待運(yùn)行)的進(jìn)程數(shù)量。目前CPU比較空閑,這個(gè)數(shù)量很小,當(dāng)這個(gè)值超過(guò)了CPU數(shù)目,就會(huì)出現(xiàn)CPU瓶頸了。
b : 阻塞的進(jìn)程,即處在不可中斷sleep狀態(tài)下的進(jìn)程數(shù)量。
memory : 查看內(nèi)存狀態(tài)
swpd : 已使用的虛擬內(nèi)存大小,如果大于0,表示機(jī)器開(kāi)始使用虛擬內(nèi)存了,虛擬內(nèi)存運(yùn)行會(huì)很慢。這里數(shù)值為0表示我們關(guān)閉了虛擬內(nèi)存功能。
free : 空閑的物理內(nèi)存的大小。
buff : 內(nèi)存做為系統(tǒng)buffers的大小。
cache : 內(nèi)存做為系統(tǒng)cache的大小。
swap : 磁盤(pán)和內(nèi)存做數(shù)據(jù)交換的狀態(tài)
nesi : 每秒從磁盤(pán)讀入虛擬內(nèi)存的大小,如果這個(gè)值大于0,表示物理內(nèi)存不夠。
so : 每秒虛擬內(nèi)存寫(xiě)入磁盤(pán)的大小。
io:磁盤(pán)的io信息
bi : 每秒從塊設(shè)備接收的塊數(shù)量。
bo : 每秒發(fā)送給塊設(shè)備的塊數(shù)量。
如果這兩個(gè)值較大,表示IO比較頻繁,可以考慮IO優(yōu)化。
system : 系統(tǒng)狀態(tài)信息
in : 每秒CPU的中斷次數(shù)(包括時(shí)鐘中斷)
cs : 每秒上下文切換次數(shù),我們調(diào)用系統(tǒng)函數(shù)、線程的切換,就需要上下文切換,這個(gè)值要太大就可以考慮 減少系統(tǒng)的上下文切換,比如協(xié)程替代多線程等方式。
CPU : CPU信息
us : 包括用戶(hù)時(shí)間和nice時(shí)間,跑非內(nèi)核的代碼(或者用戶(hù)代碼)的時(shí)間。
sy : 系統(tǒng)占用時(shí)間,跑內(nèi)核代碼(比如系統(tǒng)調(diào)用)占用的時(shí)間。
id : 花費(fèi)在idle上的 CPU時(shí)間。
wa : 等待IO CPU時(shí)間。如果這個(gè)值太大,表示IO系統(tǒng)瓶頸在IO上。
如果CPU占用高表示系統(tǒng)在CPU上, 如果系統(tǒng)的swap比較頻繁,很可能是系統(tǒng)內(nèi)存泄露或者內(nèi)存不夠用,需要擴(kuò)展內(nèi)存, 如果是IO等待較多則系統(tǒng)瓶頸出現(xiàn)在IO上,如果上下文切換,或者系統(tǒng)調(diào)用占比太大,則我們需要思考下我們程序的設(shè)計(jì),減少系統(tǒng)調(diào)用或者上下文切換。
3.2 CPU占用過(guò)高
我們可以通過(guò)uptime、top、mpstat或者sar等一些工具來(lái)查看當(dāng)前CPU占用過(guò)高的情況.
我們可以通過(guò)uptime看看當(dāng)前系統(tǒng)的整體情況, 當(dāng)前的系統(tǒng)時(shí)間和運(yùn)行時(shí)間, 登陸的用戶(hù)數(shù)量,還有最近5、10和15分鐘的系統(tǒng)平均負(fù)載。

top則可以顯示較詳細(xì)的信息。head部分有CPU占用的詳細(xì)信息, 下面的列表也有記錄每個(gè)進(jìn)程占用的CPU情況。
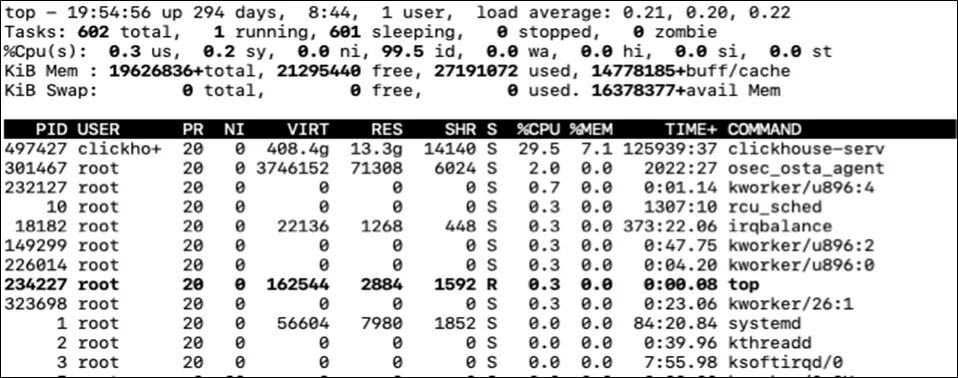
如果是多線程, 我們還可以通過(guò)top -H -p pid來(lái)查看進(jìn)程的每個(gè)線程的CPU占用情況
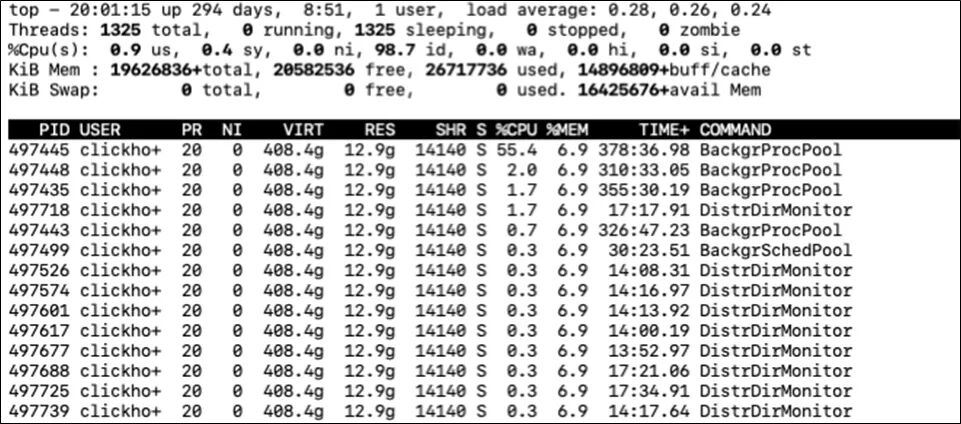
我們找到哪個(gè)線程占用的比例多之后, 可以根據(jù)這個(gè)線程的線程名查看該線程是用來(lái)做什么處理的。大致了解下是什么樣的處理讓CPU比較高。
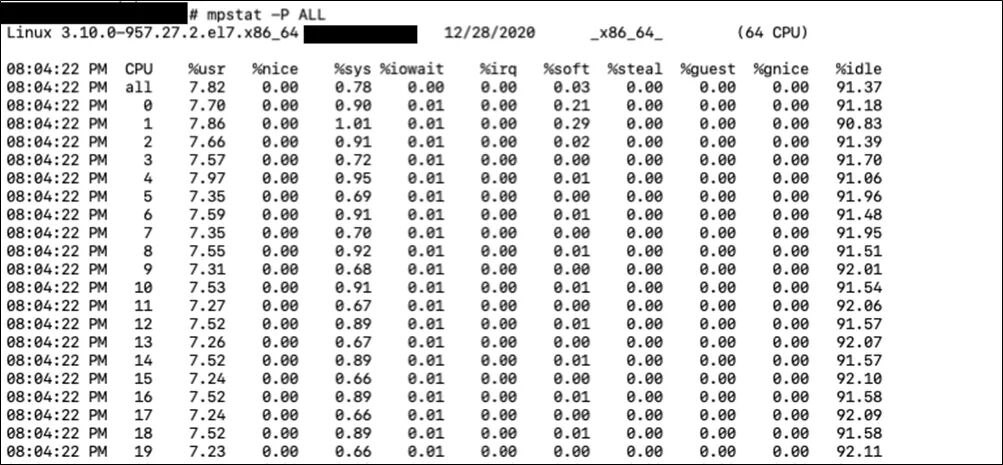
mpstat則可以查看系統(tǒng)每個(gè)核的運(yùn)行狀態(tài)。
sar的功能比較全,這里不再做科普。
CPU用戶(hù)態(tài)的占用比較高,一般就是我們的程序編寫(xiě)的效率太低,具體哪里低,我們可以通過(guò)perf工具或者Intel的vtunes來(lái)查看性能瓶頸。perf top的執(zhí)行結(jié)果如下圖所示, 我們拿到對(duì)應(yīng)的堆棧信息之后, 就可以針對(duì)性的消除CPU瓶頸了。(vtune的用法可以自行谷歌)。
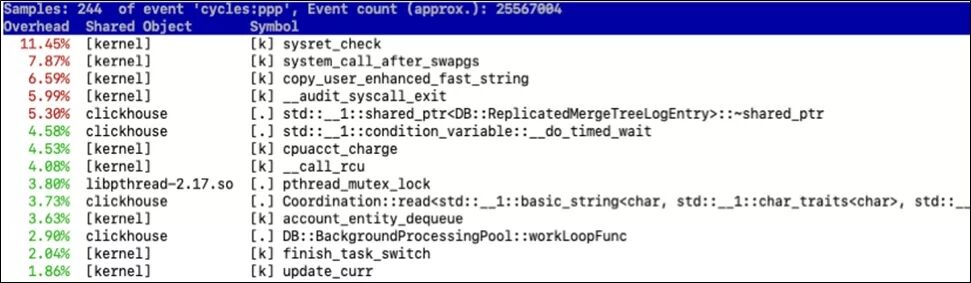
鑒于上述工具檢查出來(lái)的情況, 如果CPU確實(shí)水位很高,則CPU基本就是性能瓶頸。如果不高則,需要進(jìn)行下一步來(lái)判斷性能瓶頸。
3.3 IO占用過(guò)高的情況
IO定位的工具多種多樣, 一般查看IO問(wèn)題我們可以使用iostat、pidstat和iotop工具。當(dāng)然我們也可以使用其他的工具,大家可以自己搜索相關(guān)的工具使用, 這里主要介紹常用的幾種工具。
pidstat
pidstat是sysstat工具的一個(gè)命令,用于監(jiān)控全部或指定進(jìn)程的cpu、內(nèi)存、線程、設(shè)備IO等系統(tǒng)資源的占用情況。用戶(hù)可以通過(guò)指定統(tǒng)計(jì)的次數(shù)和時(shí)間來(lái)獲得所需的統(tǒng)計(jì)信息。

我們通過(guò)這個(gè)命令可以知道哪個(gè)進(jìn)程占用的IO比較多。然后我們可以通過(guò)指定進(jìn)程號(hào)的方式查看更詳細(xì)的信息。
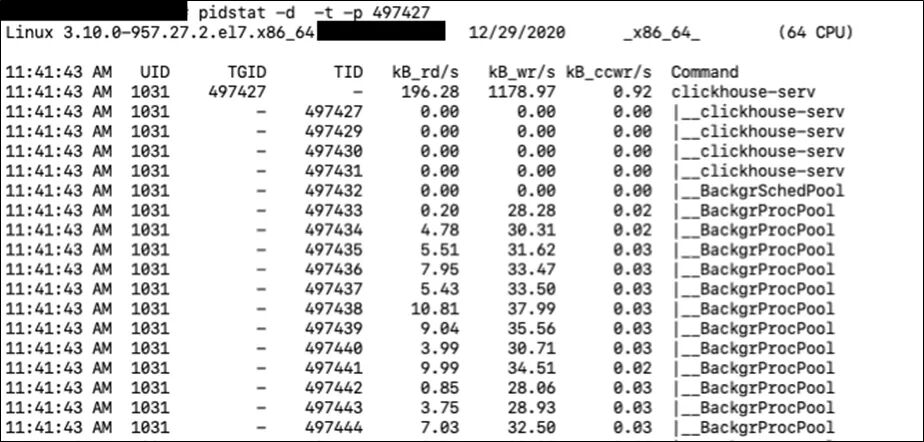
這樣我們就可以知道是哪個(gè)進(jìn)程中的哪個(gè)線程占用了較多的IO資源,然后我們可以通過(guò)對(duì)應(yīng)的TID,找到對(duì)應(yīng)的執(zhí)行代碼進(jìn)行分析。
iostat
iostat是I/O statistics(輸入/輸出統(tǒng)計(jì))的縮寫(xiě),它可以對(duì)系統(tǒng)的磁盤(pán)操作活動(dòng)進(jìn)行監(jiān)控,匯報(bào)磁盤(pán)活動(dòng)統(tǒng)計(jì)情況。但是iostat僅對(duì)系統(tǒng)的整體情況進(jìn)行統(tǒng)計(jì),不能對(duì)某個(gè)進(jìn)程進(jìn)行深入分析,單獨(dú)的進(jìn)程分析我們可以用iotop工具,使用方法和top類(lèi)似。
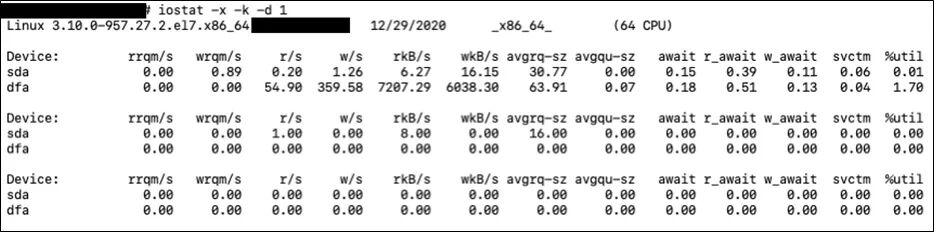
1 表示每秒打印一次當(dāng)前磁盤(pán)的統(tǒng)計(jì)信息。我們需要注意的是后面幾個(gè)指標(biāo)。
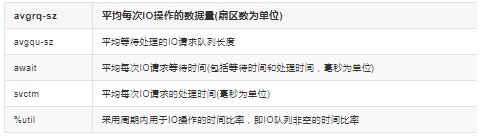
avgrq-sz直接反應(yīng)了當(dāng)前io的種類(lèi),比如大塊數(shù)據(jù)讀取還是小數(shù)據(jù)量的讀取。
avgqu-sz反應(yīng)了當(dāng)前IO的繁忙情況, 如果隊(duì)列長(zhǎng)度太長(zhǎng),說(shuō)明IO現(xiàn)在很忙很多任務(wù)處理不過(guò)來(lái),換句話說(shuō) I,IO成為了瓶頸。
await 也是一樣, 如果等待比較高,說(shuō)明IO成了累贅。
svctm則和avgrq-sz一樣,反應(yīng)了IO操作的處理規(guī)模,如果是大塊數(shù)據(jù)讀寫(xiě), 這個(gè)時(shí)間就會(huì)拉長(zhǎng)。
iotop
iotop 可以用于查看哪些進(jìn)程執(zhí)行占用了的 I/O,使用方式和top類(lèi)似,這里不再做過(guò)多描述。

3.4 其他情況
如果TOP占用不高, IO也不是瓶頸,則可能處在程序架構(gòu)上, 比如并發(fā)控制的不夠好有較多的線程在sleep狀態(tài)。這種情況可以通過(guò)pstack看看當(dāng)前所有線程的堆棧。
4. 優(yōu)化性能瓶頸
CPU瓶頸型
面對(duì)這種類(lèi)型,一般我們需要通過(guò)perf配合對(duì)應(yīng)的代碼去進(jìn)行優(yōu)化,核心思想就是減少計(jì)算的量。具體方法以下僅供參考:
- 多采用SIMD來(lái)代替老式的計(jì)算指令或者C++的操作運(yùn)算符。可以引進(jìn)類(lèi)似Intel的MKL庫(kù)來(lái)輔助計(jì)算。
- 減少不必要的重復(fù)計(jì)算,減少for循環(huán)的次數(shù)。比如有些std庫(kù)的數(shù)據(jù)結(jié)構(gòu)都有find函數(shù)都帶有起始坐標(biāo),善用起始坐標(biāo)避免從0坐標(biāo)重復(fù)查詢(xún)。
- 如果是系統(tǒng)調(diào)用過(guò)多,比如分配內(nèi)存之類(lèi)的,可以考慮預(yù)分配內(nèi)存的方式,或者直接使用tcmalloc等類(lèi)似的內(nèi)存管理庫(kù)進(jìn)行兜底,有條件的可以基于這類(lèi)庫(kù)再開(kāi)發(fā)適合自己的內(nèi)存管理體系
IO瓶頸型
IO瓶頸一般都是和磁盤(pán)相關(guān)的,網(wǎng)絡(luò)上,因?yàn)榫W(wǎng)卡升級(jí),速度上去比較快,相比來(lái)說(shuō),限制的io基本都是磁盤(pán)上的io.下面也只說(shuō)說(shuō)磁盤(pán)的IO優(yōu)化方法。
- 如果是讀類(lèi)型的請(qǐng)求造成了IO瓶頸, 可以考慮上層多開(kāi)cache。比如全局的query cache, session級(jí)別的session cache, 塊設(shè)備的block cache等,從上層去減少磁盤(pán)的io請(qǐng)求。
- 如果是是小數(shù)據(jù)大并發(fā)的寫(xiě)入類(lèi)型的造成了IO瓶頸,我們可以考慮在內(nèi)存做一次cache,對(duì)這多次寫(xiě)入先在內(nèi)存處理,然后通過(guò)時(shí)間或者大小閾值等策略控制,刷到磁盤(pán)上。
- 如果是大數(shù)據(jù)的寫(xiě)入,我們可以考慮做下平滑寫(xiě)入,每次限制寫(xiě)入的數(shù)量。
- 如果是因?yàn)榱髁康年P(guān)系,某一時(shí)間點(diǎn)出現(xiàn)峰值,之后回落,則可以考慮通過(guò)第三方來(lái)寫(xiě)入。比如消息隊(duì)列,先寫(xiě)到消息隊(duì)列i進(jìn)行削峰,再平滑寫(xiě)入系統(tǒng)。
- 除此之外我們還可以換更好的硬件,比如磁盤(pán)陣列等。
內(nèi)存瓶頸型
內(nèi)存瓶頸一般比較難出現(xiàn),內(nèi)存畢竟比較便宜,基本上都會(huì)滿足內(nèi)存的需求。如果真的因?yàn)樘摂M內(nèi)存的問(wèn)題造成了程序運(yùn)行效率低下,我們一方面是考慮增加內(nèi)存,關(guān)閉虛擬內(nèi)存來(lái)解決,同時(shí)我們也應(yīng)該思考自己的程序模型,比如減少中間數(shù)據(jù)的存在, 多用寫(xiě)時(shí)復(fù)制技術(shù),多用用系統(tǒng)的no copy接口替換老的接口等。
5. 后續(xù)
如果實(shí)在沒(méi)有方法優(yōu)化了,我們真的就需要看看當(dāng)前的query是否真的合適我們的系統(tǒng)了。還是那句話,每套系統(tǒng)都有適合自己的業(yè)務(wù),一般公司的系統(tǒng)體系里都會(huì)有多種數(shù)據(jù)庫(kù)引擎,針對(duì)我們的query,去尋找合適的引擎也是一種方法。














