













京東價格保護高并發 | 七步走保證用戶體驗
京東618期間,各種促銷活動,用戶下單量激增,促銷活動所產生的價格波動頻繁,為了保障用戶權益,拒絕站在價格的高崗上,京東推出了特色服務——價格保護。當促銷活動正式開始時,不少用戶開啟了價格保護,在此高并發情況下,如何保證用戶體驗,如何保證系統的穩定性、高可用、快速計算結果,是本文的重點。
我們將按照下圖進行實踐分享:

一、高筑墻
對于任何網站,我們的系統都需要做出防護措施,面對海量流量,保障系統不被沖垮;需要通過一些像限流、降級等技術,對系統進行全方位保護。
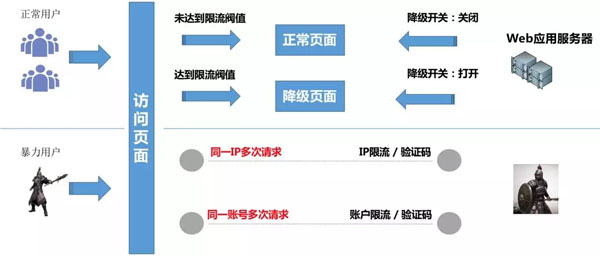
從上圖可以看到,我們針對正常用戶和暴力用戶在不影響用戶體驗的前提下,采取降級、限流等措施,以保障系統穩定。那么我們是如何做的呢,下面我們分別來說說限流、降級。
1. 限流
(1) 正常用戶限流
正常用戶訪問時,超出了系統的承載能力,這時就需要做限流,防止系統被打垮導致不可用。
通過壓測,得到單臺機器的***承載能力,而后在單臺服務器上通過限流計數方式進行訪問次數統計,設置在一段時間內只可訪問N次。例如,設置1w/分鐘,當在1分鐘內達到閾值時,將進入降級配置,過了該時間段后,在第2分鐘時,又重新進行計數,以此保證單臺機器不會超出***承載能力,后續每臺服務器都按照這個閾值進行配置。
(2)暴力用戶限流
暴力用戶頻繁刷應用系統,我們需要在這層做一些防刷,比如清洗惡意流量、做一些黑名單。當有惡意流量時,通過對IP、用戶等限制手段把它拒絕在系統之外,防止這些惡意流量把系統沖垮。
這里通過redis計數,按照IP或用戶的維度,進行原子加1,限制120/分鐘,防止惡意流量影響到我們的正常用戶訪問量。
2. 降級
當某個接口出現問題時,我們能夠對該接口降級,快速將結果返回,不影響主流程。
那么降級是怎么做的呢?

由于我們分布式集群,應用服務器數量很多,因此,我們需要將降級開關集中化管理。這里我們制作了統一的配置開關組件,通過zookeeper將配置推送到各個服務器節點,同時在zookeeper及應用服務器上分別會有快照數據,保證如果統一配置開關組件發生問題,我們應用也會讀取本地快照數據,不影響應用本身。同時在應用重啟的時候,我們也會通過接口拉取配置中心上的***快照。
對于降級,我們也需要友好提示,在前端如果降級,我們需要友好提示,或者展示降級頁面,盡量不影響用戶體驗。
二、廣積糧
對于大并發網站,我們需要進行各種數據準備,需要區分動態資源與靜態資源,將靜態資源進行緩存,以應對瞬時訪問量。

1. CDN
頁面上的靜態資源,如js、css、picture、靜態html等資源,可以提前準備,放到CDN,當頁面請求時,可將這部分網絡請求打到CDN網絡上,減少連接請求,降低應用服務器壓力。
采用CDN時,我們需要注意,當web頁面與js發生改變,無論是先部署web應用,還是先推送js到CDN,都有可能發生js腳本錯誤。因此,我們需要在web頁面上做CDN切換開關,先將資源訪問切換到web機器上,待上線驗證后沒有問題,再部署CDN,切換靜態資源訪問到CDN。
2. 數據緩存
我們在獲取數據時,應先做出判斷,哪些地方可以用緩存,哪些地方需要讀數據庫。動態資源固定屬性,高頻訪問,則應主動緩存。例如,訂單下單時快照,訂單的類型、下單時間、訂單內商品、商品下單價等,就是固定不變的,我們通過接收訂單下單消息,進行數據主動緩存,以便后續展示訂單內商品價格、計算價保申請時下單價及促銷價做出準備,而無需實時訪問訂單接口,降低了后端接口壓力,也加快了獲取速度。
三、化繁從簡
在高并發情況下,需要快速響應,當請求過程中,獲取過多的數據,則有可能會降低響應速度,因此要將處理簡單化,只做黃金流程即可。
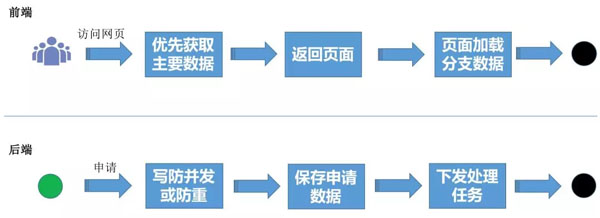
1. 前端從簡
用戶訪問頁面時,只關心關鍵部分數據,因此我們需要優先獲取主要數據,立刻返回頁面,由頁面通過ajax加載分支數據,達到頁面完整性。這樣既保證了用戶體驗,又提升系統的響應能力。
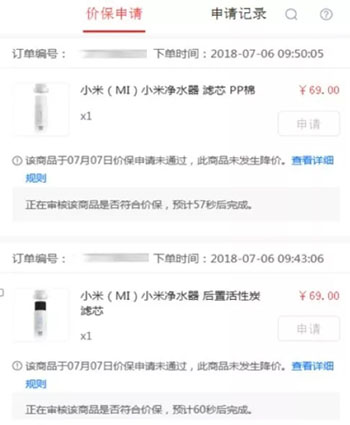
圖-價保申請
以價保申請頁面為例,用戶進入頁面,就是要進行商品價格保護,因此商品列表、申請按鈕,是用戶最想看見的。其他的信息,如商品最近一次價保記錄、下單價格等數據,就可以后續再進行加載。
2. 后端從簡
用戶進行價格保護申請時,由于處理邏輯非常復雜,需要和20多個系統進行交互,才能計算出結果,因此我們采用異步處理方案。那么在接入申請時,任何系統都可以用三步方式接入申請:
- 插入防重
- 保存申請數據
- 下發處理任務
這樣保證了用戶申請可快速接入,提升系統的接單能力,后續對處理任務進行加速,則可以很快的返回結果,不影響用戶體驗。后面的章節“處理無極限、速戰速決”會具體講解如何最快的處理任務。
四、合二為一
在高并發請求下,由于請求數巨大,cpu會頻繁切換上下文,導致cpu使用率飄升、性能下降,因此我們要盡量減少請求數,將可以合并的進行合并。
還以上面“圖-價保申請”為例,由于訂單內商品價格在后端已經緩存,我們可以將商品價格按照訂單的維度進行合并,同一個訂單下所有商品價格通過一個ajax進行請求訪問。刷新是否符合價保請求進行合并,無論用戶點擊了多少次申請,都以一個ajax進行組合刷新結果,這樣就減少了請求后端的連接訪問。
五、分而治之
1. 前端網站
我們按照訪問來源、主次流程進行集群分散:
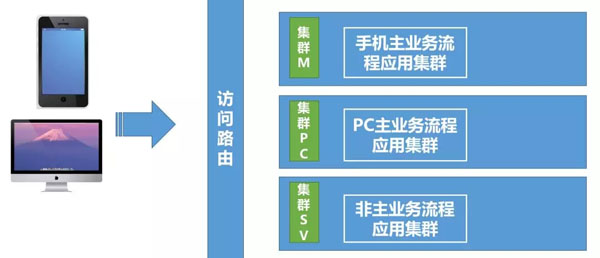
目前很多網站都制作了手機端、PC電腦端,因此按照訪問來源,我們應用集群也進行區分。這樣做不但可以使各個來源集群相互不影響,還能根據訪問來源不同的訪問量,合理分配機器。
同時,我們還按照了主、次業務,進行了集群區分,將不重要的業務放到非主業務集群上,使其不會影響到主業務流程。例如“圖-價保申請”中所示,價格、最近一次訪問記錄、申請結果刷新,這3個功能就不是主業務流程,將它們放在非主業務集群上進行訪問,就算非主業務集群出現問題,也不會影響到價保黃金流程。
2. 后端數據
后端進行讀寫分離,分庫分表:
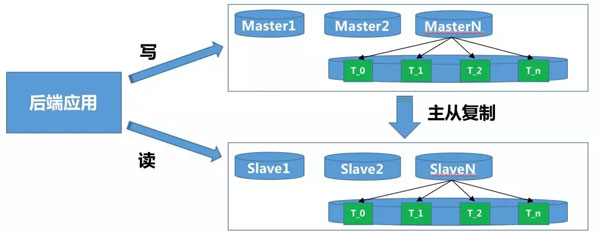
對數據查詢時,是否需要實時數據,決定是否采用讀從庫。
對大量數據寫時,應將數據按照業務需要的維度進行分庫分表,降低數據庫壓力。
這里我們說下我們是如何進行分庫的。價保系統的主要維度是用戶,因此我們按照用戶PIN進行分庫路由,以用PIN取Hash值,然后取模。例如我們要分2個庫,則算法hash值%2。那么問題來了,當業務量開始增長,2個庫滿足不了我們的要求,需要擴展更多的庫,例如5個庫,怎么辦?一般做法是將2個庫的數據進行清理,然后按照新的庫個數5重新打散數據,hash值%5。
這樣做實在太麻煩了,因此我們這里采用二叉樹算法,可以很平滑的擴容數據庫,不用進行數據打散重新分配,怎么做的呢?下面我們先回憶下二叉樹:
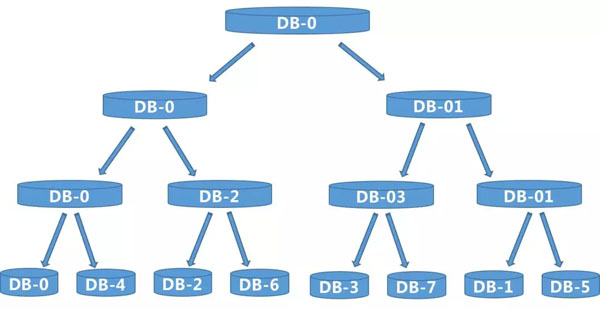
從上圖可看出,1個→2個→4個→8個,新裂變出的節點,只需要將數據冗余父節點,按照2的N次方,向下裂變即可。
那我們看看是如何進行擴容的:
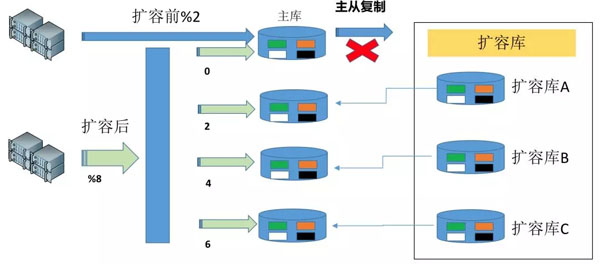
在擴容前,有2個數據庫DB-0和DB-1,現在需要擴容到8個數據庫,以DB-0為例:
- 我們只需要新找3臺數據庫,掛載到DB-0上當做從庫,而后進行主從復制;
- 在數據量最少的時間段,將主從復制切斷,同時將擴容的ABC三個從庫切換為主庫,此時4個數據庫數據一致,每個有1/4的數據屬于自己,其他數據則為冗余數據。
- 將路由算法調整到 hash值%8,部署新應用,將所有主庫連接上后進行接量,此時有新、舊2個應用同時在。但是如果舊應用接量,則同步不到新裂變出的數據庫2、4、6上;
- 制作數據遷移任務、數據比對任務,將0庫按照切斷主從復制的時間開始,按照hash值%8,將2、4、6的數據(以最終狀態為準)同步到各自的庫上,同時做數據比對驗證;
- 停止舊應用,由擴容后的新應用開始承接所有的量,此時,數據庫擴容完成。
在擴容完成后,我們只需要做冗余數據的清理即可,實現方式很多,例如可以通過數據歸檔任務:
- 寫防重
- 一定時間段之前的數據進行歸檔
這樣,經過一段時間后,冗余數據就會被清理掉,同時因為有防重,也不會出現多次歸檔導致歸檔數據重復。
六、處理無極限
經過上面的幾步,用戶可正常的打開頁面,提交商品價格保護申請,那么如何能將這巨大的申請量全部吃下,并迅速的返回,成了我們系統的一大難題。處理的慢,就有可能獲取當時促銷價不準確,導致用戶價保失敗,用戶體驗會急劇下降。
下面我們將演示如何從有極限到無極限:
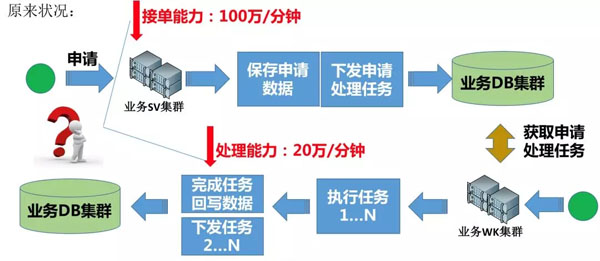
圖 – 有極限
大家看,為什么上圖是有極限呢?
從申請入庫到處理申請任務,都是采用業務DB集群,這樣的話,如果接單能力100萬/分鐘,處理能力只有20萬/分鐘,此時數據庫已達到瓶頸,那么想要處理的更快,只能繼續做分庫,添加業務WK集群機器,這樣也能讓處理能力上升,但是接單能力這邊就會出現極大的浪費。
通過這些,想必大家也能猜到,對,我們將接單、任務處理2個集群的DB分開,就能解決這個問題,同時相互間也不會有任何影響。怎么做呢?請看下圖:
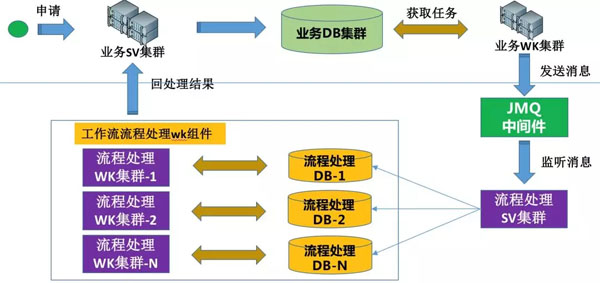
我們業務接單集群,只做業務處理,保存到業務DB集群,通過業務WK集群,將任務下發到JMQ中間件,任務流程處理SV集群進行消息監聽,將消息分庫插入到流程處理DB中,每個流程處理DB都會對應一套任務處理WK集群,那么按照上面20萬/分鐘來算,我們這邊只需要5套即可。這樣無論業務申請如何大,我們任務處理都可以隨時擴展。
七、速戰速決
在上述“處理無極限”中,我們已經可以隨時擴展,那么怎么才能最快的任務處理呢?這節我們主要說說怎么讓任務處理速度最快,同時在出異常的情況下,任務不丟失。
由于價保申請處理,業務非常復雜,我們這里采用工作流模式,以任務節點程序全自動進行處理。我們來看下,任務系統是如何演變,***達到速戰速決的。
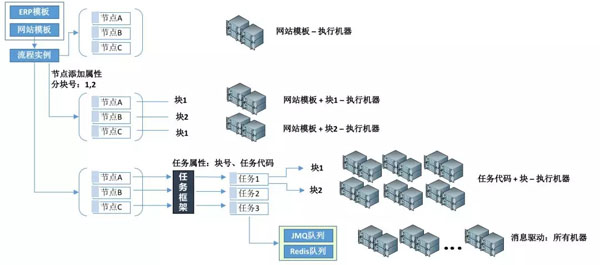
工作流的流程介紹:通過工作流流程模板Template,一個申請Apply生成一個流程實例Order,每個流程實例Order下會有N個節點任務Task。
***階段
按照Template維度,定時獲取一定數量的Task,循環執行。以機器充分執行任務的角度來看,此時一臺機器即可,兩臺機器執行,則有可能抓取到相同的任務,導致資源浪費。
第二階段
數據分塊:將一批數據,按照預先設定好的進行分塊,而后可對分塊數據進行區分對待。
如上圖,對任務節點Task進行分塊,此時定時獲取Task 維度發生變化,可從Template、塊2個維度獲取Task,目前分為2個塊,則該模板可執行機器為兩臺;塊號越多,則該模板執行的機器越多。
但是我們發現,最小粒度是Task,為什么要有Template的維度呢?
第三階段
將Template維度去掉,采用Task最小粒度維度,上圖中使用了任務框架,是我們自主研發的,如不使用該框架,只要保證最小粒度為Task,一樣可行。
我們將Task以Template+TaskCode生成任務代碼,再在Task上面進行分塊,則達到了最小粒度:任務代碼+塊。如上圖所示,還是每個任務分2個塊,此時3個任務2個塊,一共可以有6臺服務器進行任務執行。此時速度已經很快了,按照最小粒度進行區分,但是還是有機器的數量限制,只能加大塊號,以便更多機器可以執行。
第四階段
在生成Task節點的同時,將該節點信息下發到消息隊列,通過消息進行驅動,從而達到所有機器接可執行,將速度提升到最快,此時只要保證任務內部處理夠快即可。
在此階段,當任務執行異常、消息丟失,我們還有第三階段的方案進行保底、重試,同樣保證任務可高效執行。
夏慶峰:逆向流程技術專家,疑難雜癥的終結者,2014年加入京東,負責京東財務退款及價格保護研發建設,擅長京東逆向流程場景、金額拆分計算、高并發下網站優化。
【本文來自51CTO專欄作者張開濤的微信公眾號(開濤的博客),公眾號id: kaitao-1234567】













