













深度學(xué)習(xí)與神經(jīng)網(wǎng)絡(luò):最值得關(guān)注的6大趨勢
神經(jīng)網(wǎng)絡(luò)的基本思想是模擬計算機(jī)“大腦”中多個相互連接的細(xì)胞,這樣它就能從環(huán)境中學(xué)習(xí),識別不同的模式,進(jìn)而做出與人類相似的決定。
典型的神經(jīng)網(wǎng)絡(luò)是由數(shù)千互連的人工神經(jīng)元組成,神經(jīng)元是構(gòu)成神經(jīng)網(wǎng)絡(luò)的基本單位。這些神經(jīng)元按順序堆疊在一起,以稱為層的形式形成數(shù)百萬個連接。單位劃分如下:
- 輸入單元:用于接收外部環(huán)境的信息;
- 隱藏單元:隱藏層將所需的計算及輸出結(jié)果傳遞給輸出層;
- 輸出單元:輸出信號表明網(wǎng)絡(luò)是如何響應(yīng)最近獲得的信息。
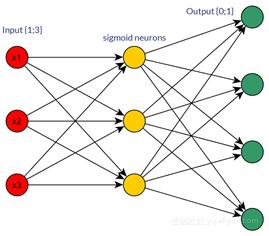
多數(shù)神經(jīng)網(wǎng)絡(luò)都是“全連接的”,也就是說,每一個隱藏單元和輸出單元都與另一邊的所有單元相連接。每個單元之間的連接稱為“權(quán)重”,權(quán)重可正可負(fù),這取決于它對另一個單元的影響程度。權(quán)重越大,對相關(guān)單元的影響也就越大。
前饋神經(jīng)網(wǎng)絡(luò)是一種最簡單的神經(jīng)網(wǎng)絡(luò),各神經(jīng)元分層排列。每個神經(jīng)元只與前一層的神經(jīng)元相連。接收前一層的輸出,并輸出給下一層,各層間沒有反饋。是目前應(yīng)用最廣泛、發(fā)展最迅速的人工神經(jīng)網(wǎng)絡(luò)之一。
下面將就神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)發(fā)展的幾大重要趨勢進(jìn)行討論:
1. 膠囊網(wǎng)絡(luò)(Capsule Networks)
膠囊網(wǎng)絡(luò)是一種新興的深層神經(jīng)網(wǎng)絡(luò),其處理信息的方式類似于人腦。
膠囊網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)相反,雖然卷積神經(jīng)網(wǎng)絡(luò)是迄今為止應(yīng)用最廣泛的神經(jīng)網(wǎng)絡(luò)之一,但其未能考慮簡單對象和復(fù)雜對象之間存在的關(guān)鍵空間層次結(jié)構(gòu)。這導(dǎo)致了誤分類并帶來了更高的錯誤率。
在處理簡單的識別任務(wù)時,膠囊網(wǎng)絡(luò)擁有更高的精度,更少的錯誤數(shù)量,并且不需要大量的訓(xùn)練模型數(shù)據(jù)。
2. 深度強(qiáng)化學(xué)習(xí)(Deep Reinforcement Learning, DRL)
深度強(qiáng)化學(xué)習(xí)是神經(jīng)網(wǎng)絡(luò)的一種形式,它的學(xué)習(xí)方式是通過觀察、行動和獎勵,與周圍環(huán)境進(jìn)行交互。深度強(qiáng)化學(xué)習(xí)已經(jīng)被成功地用于游戲策略的制定,如Atari和Go。AlphaGo擊敗了人類冠軍棋手,是深度強(qiáng)化學(xué)習(xí)最為著名的應(yīng)用。
3. 數(shù)據(jù)增強(qiáng)(Lean and augmented data learning)
到目前為止,機(jī)器學(xué)習(xí)與深度學(xué)習(xí)遇到的***挑戰(zhàn)是:需要大量使用帶標(biāo)簽的數(shù)據(jù)來訓(xùn)練系統(tǒng)。目前有兩種應(yīng)用廣泛的技巧可以幫助解決這個問題:
- 合成新的數(shù)據(jù)
- 遷移學(xué)習(xí)
“遷移學(xué)習(xí)”,即把從一個任務(wù)或領(lǐng)域?qū)W到的經(jīng)驗遷移到另一個任務(wù)或領(lǐng)域,“一次學(xué)習(xí)”指遷移學(xué)習(xí)應(yīng)用到極端情況下,在只有一個相關(guān)例子,甚至沒有例子的情況下學(xué)習(xí)。由此它們成為了“精簡數(shù)據(jù)”的學(xué)習(xí)技巧。與之相仿,當(dāng)使用模擬或內(nèi)插合成新的數(shù)據(jù)時,它有助于獲取更多的訓(xùn)練數(shù)據(jù),因而能夠增強(qiáng)現(xiàn)有數(shù)據(jù)以改進(jìn)學(xué)習(xí)。
通過運(yùn)用上述技巧,我們能夠解決更多的問題,尤其是在歷史數(shù)據(jù)較少的情況下。
4. 監(jiān)督模型(Supervised Model)
監(jiān)督模型時一種學(xué)習(xí)形式,它根據(jù)預(yù)先標(biāo)記的訓(xùn)練數(shù)據(jù)學(xué)到或建立一個模式,并依此模式推斷新的實(shí)例。監(jiān)督模型使用一種監(jiān)督學(xué)習(xí)的算法,該算法包括一組輸入和標(biāo)記正確的輸出。
將標(biāo)記的輸入與標(biāo)記的輸出進(jìn)行比較。給定兩者之間的變化,計算一個誤差值,然后使用一個算法來學(xué)習(xí)輸入和輸出之間的映射關(guān)系。
5. 網(wǎng)絡(luò)記憶模型(Networks With Memory Model)
人類和機(jī)器的一個典型區(qū)別在于工作和嚴(yán)謹(jǐn)思考的能力。我們可以對計算機(jī)進(jìn)行編程,使其以極高的準(zhǔn)確率完成特定的任務(wù)。但是如果我們想要它在不同的環(huán)境中工作,還有需要解決很多問題。
要想使機(jī)器適應(yīng)現(xiàn)實(shí)世界的環(huán)境,神經(jīng)網(wǎng)絡(luò)必須能夠?qū)W習(xí)連續(xù)的任務(wù)且不產(chǎn)生“災(zāi)難性忘卻(catastrophic forgetting)”,這便需要許多方法的幫助,如:
- 長期記憶網(wǎng)絡(luò)(Long-Term Memory Networks):它能夠處理和預(yù)測時間序列
- 彈性權(quán)重鞏固算法(Elastic Weight Consolidation, EWC):該方法能夠選擇性地減慢對這些任務(wù)而言比較重要的權(quán)重的學(xué)習(xí)速率
- 漸進(jìn)式神經(jīng)網(wǎng)絡(luò)(Progressive Neural Networks):不會產(chǎn)生“災(zāi)難性忘卻”,它能夠從已經(jīng)學(xué)會的網(wǎng)絡(luò)中提取有用的特征,用于新的任務(wù)
6. 混合學(xué)習(xí)模式(Hybrid Learning Models)
不同類型的深度神經(jīng)網(wǎng)絡(luò),例如生成式對抗網(wǎng)絡(luò)(GANs)以及深度強(qiáng)化學(xué)習(xí)(DRL),在性能提升和廣泛應(yīng)用方面展現(xiàn)了了巨大的潛力。不過,深度學(xué)習(xí)模型不能像貝葉斯概率那樣為不確定性的數(shù)據(jù)場景建模。
混合學(xué)習(xí)模式結(jié)合了這兩種方法的優(yōu)勢,典型的混合學(xué)習(xí)模式包括貝葉斯生成對抗網(wǎng)絡(luò)(Bayesian GANs)以及貝葉斯條件生成對抗網(wǎng)絡(luò)(Bayesian Conditional GANs)。
混合學(xué)習(xí)模式將商業(yè)問題的范圍擴(kuò)大,使其能夠解決具有不確定性的深度學(xué)習(xí)問題,從而提高模型的性能,增強(qiáng)模型的可解釋性,實(shí)現(xiàn)更加廣泛的運(yùn)用。













