MapReuce中對大數據處理最合適的數據格式是什么?
在本章的***章節介紹中,我們簡單了解了Mapreduce數據序列化的概念,以及其對于XML和JSON格式并不友好。本節作為《Hadoop從入門到精通》大型專題的第三章第二節將教大家如何在Mapreduce中使用XML和JSON兩大常見格式,并分析比較最適合Mapreduce大數據處理的數據格式。
3.2.1 XML
XML自1998年誕生以來就作為一種數據格式來表示機器和人類都可讀的數據。它成為系統之間數據交換的通用語言,現在被許多標準所采用,例如SOAP和RSS,并且被用作Microsoft Office等產品的開放數據格式。
MapReduce和XML
MapReduce捆綁了與文本一起使用的InputFormat,但沒有支持XML,也就是說,原生Mapreduce對XML十分不友好。在MapReduce中并行處理單個XML文件很棘手,因為XML不包含其數據格式的同步標記。
問題
希望在MapReduce中使用大型XML文件,并能夠并行拆分和處理。
解決方案
Mahout的XMLInputFormat可用于MapReduce處理HDFS中的XML文件。 它讀取由特定XML開始和結束標記分隔的記錄,此技術還解釋了如何在MapReduce中將XML作為輸出發送。
MapReduce不包含對XML的內置支持,因此我們轉向另一個Apache項目——Mahout,一個提供XML InputFormat的機器學習系統。 要了解XML InputFormat,你可以編寫一個MapReduce作業,該作業使用Mahout的XML輸入格式從Hadoop的配置文件(HDFS)中讀取屬性名稱和值。
***步是對作業進行配置:

Mahout的XML輸入格式很簡陋,我們需要指定文件搜索的確切開始和結束XML標記,并使用以下方法拆分文件(并提取記錄):
- 文件沿著HDFS塊邊界分成不連續的部分,用于數據本地化。
- 每個map任務都在特定的輸入拆分上運行,map任務尋求輸入拆分的開始,然后繼續處理文件,直到***個xmlinput.start。
- 重復發出xmlinput.start和xmlinput.end之間的內容,直到輸入拆分的末尾。
接下來,你需要編寫一個映射器來使用Mahout的XML輸入格式。Text表單已提供XML元素,因此需要使用XML解析器從XML中提取內容。

表3.1 使用Java的STAX解析器提取內容
該map具有一個Text實例,該實例包含start和end標記之間數據的String表示。在此代碼中,我們可以使用Java的內置Streaming API for XML(StAX)解析器提取每個屬性的鍵和值并輸出。
如果針對Cloudera的core-site.xml運行MapReduce作業并使用HDFS cat命令顯示輸出,將看到以下內容:
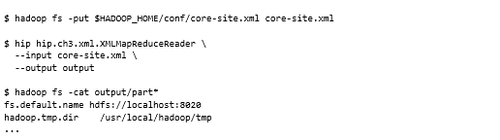
此輸出顯示已成功使用XML作為MapReduce的輸入序列化格式。不僅如此,還可以支持巨大的XML文件,因為輸入格式支持拆分XML。
寫XML
當可以正常讀XML之后,我們要解決的就是如何寫XML。 在reducer中,調用main reduce方法之前和之后都會發生回調,可以使用它來發出開始和結束標記,如下所示。
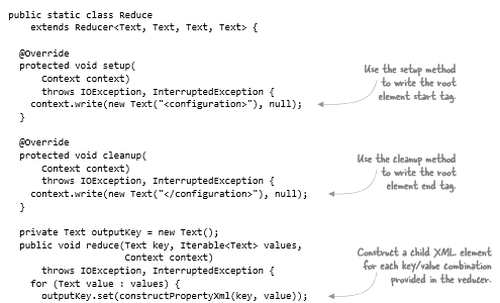

表3.2 用于發出開始和結束標記的reducer
這也可以嵌入到OutputFormat中。
Pig
如果想在Pig中使用XML,Piggy Bank library(用戶貢獻的Pig代碼庫)包含一個XMLLoader。其工作方式與此技術非常相似,可捕獲開始和結束標記之間的所有內容,并將其作為Pig元組中的單字節數組字段提供。
Hive
目前沒有辦法在Hive中使用XML,必須寫一個自定義SerDe。
總結
Mahout的XmlInputFormat可幫助使用XML,但它對開始和結束元素名稱的精確字符串匹配很敏感。如果元素標記包含具有變量值的屬性,無法控制元素生成或者可能導致使用XML命名空間限定符,則此方法不可用。
如果可以控制輸入中的XML,則可以通過在每行使用單個XML元素來簡化此練習。這允許使用內置的MapReduce基于文本的輸入格式(例如TextInputFormat),它將每一行視為記錄并拆分。
值得考慮的另一個選擇是預處理步驟,可以將原始XML轉換為每個XML元素的單獨行,或者將其轉換為完全不同的數據格式,例如SequenceFile或Avro,這兩種格式都解決了拆分問題。
現在,你已經了解如何使用XML,讓我們來處理另一種流行的序列化格式JSON。
3.2.2 JSON
JSON共享XML的機器和人類可讀特征,并且自21世紀初以來就存在。它比XML簡潔,但是沒有XML中豐富的類型和驗證功能。
如果有一些代碼正在從流式REST服務中下載JSON數據,并且每小時都會將文件寫入HDFS。由于下載的數據量很大,因此生成的每個文件大小為數千兆字節。
如果你被要求編寫一個MapReduce作業,需要將大型JSON文件作為輸入。你可以將問題分為兩部分:首先,MapReduce沒有與JSON一起使用的InputFormat; 其次,如何分割JSON?
圖3.7顯示了拆分JSON問題。 想象一下,MapReduce創建了一個拆分,如圖所示。對此輸入拆分進行操作的map任務將執行對輸入拆分的搜索,以確定下一條記錄的開始。對于諸如JSON和XML之類的文件格式,由于缺少同步標記或任何其他標識記錄開頭,因此知道下一條記錄何時開始是很有挑戰性的。
JSON比XML等格式更難分割成不同的段,因為JSON沒有token(如XML中的結束標記)來表示記錄的開頭或結尾。
問題
希望在MapReduce中使用JSON輸入,并確保可以為并發讀取分區輸入JSON文件。
解決方案
Elephant Bird LzoJsonInputFormat被用來作為創建輸入格式類以使用JSON元素的基礎,該方法可以使用多行JSON。

圖3.7 使用JSON和多個輸入拆分的問題示例
討論
Elephant Bird(https://github.com/kevinweil/elephant-bird)是一個開源項目,包含用于處理LZOP壓縮的有用程序,它有一個可讀取JSON的LzoJsonInputFormat,盡管要求輸入文件是LZOP-compressed。,但可以將Elephant Bird代碼用作自己的JSON InputFormat模板,該模板不具有LZOP compression要求。
此解決方案假定每個JSON記錄位于單獨的行上。JsonRecordFormat很簡單,除了構造和返回JsonRecordFormat之外什么也沒做,所以我們將跳過該代碼。JsonRecordFormat向映射器發出LongWritable,MapWritable key/value,其中MapWritable是JSON元素名稱及其值的映射。
我們來看看RecordReader的工作原理,它使用LineRecordReader,這是一個內置的MapReduce讀取器。要將該行轉換為MapWritable,讀取器使用json-simple解析器將該行解析為JSON對象,然后迭代JSON對象中的鍵并將它們與其關聯值一起放到MapWritable。映射器在LongWritable中被賦予JSON數據,MapWritable pairs可以相應地處理數據。

以下顯示了JSON對象示例:


該技巧假設每行一個JSON對象,以下代碼顯示了在此示例中使用的JSON文件:
現在將JSON文件復制到HDFS并運行MapReduce代碼。MapReduce代碼寫入每個JSON key/value對并輸出:
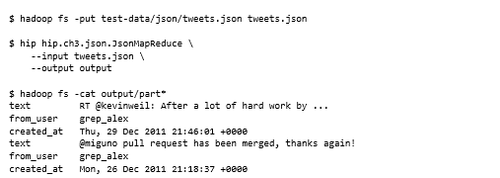
寫JSON
類似于3.2.1節,編寫XML的方法也可用于編寫JSON。
Pig
Elephant Bird包含一個JsonLoader和LzoJsonLoader,可以使用它來處理Pig中的JSON,這些加載器使用基于行的JSON。每個Pig元組都包含該行中每個JSON元素的chararray字段。
Hive
Hive包含一個可以序列化JSON的DelimitedJSONSerDe類,但遺憾的是無法對其進行反序列化,因此無法使用此SerDe將數據加載到Hive中。
總結
此解決方案假定JSON輸入的結構為每個JSON對象一行。那么,如何使用跨多行的JSON對象?GitHub上有一個項目( https://github.com/alexholmes/json-mapreduce)可以在單個JSON文件上進行多個輸入拆分,此方法可搜索特定的JSON成員并檢索包含的對象。
你可以查看名為hive-json-serde的Google項目,該項目可以同時支持序列化和反序列化。
正如你所看到的,在MapReduce中使用XML和JSON是非常糟糕的,并且對如何布局數據有嚴格要求。MapReduce對這兩種格式的支持也很復雜且容易出錯,因為它們不適合拆分。顯然,需要查看具有內部支持且可拆分的替代文件格式。
下一步是研究更適合MapReduce的復雜文件格式,例如Avro和SequenceFile。
3.3 大數據序列化格式
當使用scalar或tabular數據時,非結構化文本格式很有效。諸如XML和JSON之類的半結構化文本格式可以對包括復合字段或分層數據的復雜數據結構進行建模。但是,當處理較大數據量時,我們更需要具有緊湊序列化表單的序列化格式,這些格式本身支持分區并具有模式演變功能。
在本節中,我們將比較最適合MapReduce大數據處理的序列化格式,并跟進如何將它們與MapReduce一起使用。
3.3.1 比較SequenceFile,Protocol Buffers,Thrift和Avro
根據經驗,在選擇數據序列化格式時,以下特征非常重要:
- 代碼生成——某些序列化格式具有代碼生成作用的庫,允許生成豐富的對象,使更容易與數據交互。生成的代碼還提供了類似安全性等額外好處,以確保消費者和生產者使用正確的數據類型。
- 架構演變 - 數據模型隨著時間的推移而發展,重要的是數據格式支持修改數據模型的需求。模式演變功能允許你添加、修改并在某些情況下刪除屬性,同時為讀和寫提供向后和向前兼容性。
- 語言支持 - 可能需要使用多種編程語言訪問數據,主流語言支持數據格式非常重要。
- 數據壓縮 - 數據壓縮非常重要,因為可以使用大量數據。并且,理想的數據格式能夠在寫入和讀取時內部壓縮和解壓縮數據。如果數據格式不支持壓縮,那么對于程序員而言,這是一個很大的問題,因為這意味著必須將壓縮和解壓縮作為數據管道的一部分進行管理(就像使用基于文本的文件格式一樣)。
- 可拆分性 - 較新的數據格式支持多個并行讀取器,可讀取和處理大型文件的不同塊。文件格式包含同步標記至關重要(可隨機搜索和掃描到下一條記錄開頭)。
- 支持MapReduce和Hadoop生態系統 - 選擇的數據格式必須支持MapReduce和其他Hadoop生態系統關鍵項目,例如Hive。如果沒有這種支持,你將負責編寫代碼以使文件格式適用于這些系統。
表3.1比較了流行的數據序列化框架,以了解它們如何相互疊加。以下討論提供了有關這些技術的其他背景知識。
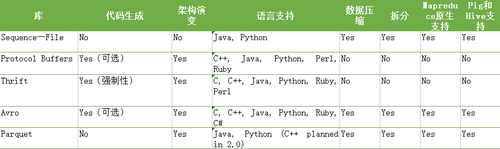
表3.1數據序列化框架的功能比較
讓我們更詳細地看一下這些格式。
SequenceFile
創建SequenceFile格式是為了與MapReduce、Pig和Hive一起使用,因此可以很好地與所有工具集成。缺點主要是缺乏代碼生成和版本控制支持,以及有限的語言支持。
Protocol Buffers
Protocol Buffers 已被Google大量用于互操作,其優勢在于其版本支持二進制格式。缺點是MapReduce(或任何第三方軟件)缺乏對讀取Protocol Buffers 序列化生成的文件支持。但是,Elephant Bird可以在容器文件中使用Protocol Buffers序列化。
Thrift
Thrift是Facebook內部開發的數據序列化和RPC框架,在本地數據序列化格式中不支持MapReduce,但可以支持不同的wire-level數據表示,包括JSON和各種二進制編碼。 Thrift還包括具有各種類型服務器的RPC層。本章將忽略RPC功能,并專注于數據序列化。
Avro
Avro格式是Doug Cutting創建的,旨在幫助彌補SequenceFile的不足。
Parquet
Parquet是一種具有豐富Hadoop系統支持的柱狀文件格式,可以與Avro、Protocol Buffers和Thrift等友好工作。盡管 Parquet 是一個面向列的文件格式,不要期望每列一個數據文件。Parquet 在同一個數據文件中保存一行中的所有數據,以確保在同一個節點上處理時一行的所有列都可用。Parquet 所做的是設置 HDFS 塊大小和***數據文件大小為 1GB,以確保 I/O 和網絡傳輸請求適用于大批量數據。
基于上述評估標準,Avro似乎最適合作為Hadoop中的數據序列化框架。SequenceFile緊隨其后,因為它與Hadoop具有內在兼容性(它設計用于Hadoop)。
你可以在Github上查看jvm-serializers項目,該項目運行各種基準測試,以根據序列化和反序列化時間等比較文件格式。它包含Avro,Protocol Buffers和Thrift基準測試以及許多其他框架。
在了解了各種數據序列化框架后,我們將在接下來幾節中專門討論這些格式。