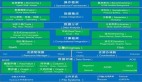
大數據處理基本過程
剛接觸大數據一個月,把一些基本知識,總體架構記錄一下,感覺坑很多,要學習的東西也很多,先簡單了解一下基本知識
什么是大數據:大數據(big data),指無法在一定時間范圍內用常規軟件工具進行捕捉、管理和處理的數據集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的信息資產。
大數據的5V特點:Volume(大量)、Velocity(高速)、Variety(多樣)、Value(低價值密度)、Veracity(真實性),百度隨便找找都有。
大數據處理流程:

1.是數據采集,搭建數據倉庫,數據采集就是把數據通過前端埋點,接口日志調用流數據,數據庫抓取,客戶自己上傳數據,把這些信息基礎數據把各種維度保存起來,感覺有些數據沒用(剛開始做只想著功能,有些數據沒采集, 后來被老大訓了一頓)。
2.數據清洗/預處理:就是把收到數據簡單處理,比如把ip轉換成地址,過濾掉臟數據等。
3.有了數據之后就可以對數據進行加工處理,數據處理的方式很多,總體分為離線處理,實時處理,離線處理就是每天定時處理,常用的有阿里的maxComputer,hive,MapReduce,離線處理主要用storm,spark,hadoop,通過一些數據處理框架,可以吧數據計算成各種KPI,在這里需要注意一下,不要只想著功能,主要是把各種數據維度建起來,基本數據做全,還要可復用,后期就可以把各種kpi隨意組合展示出來。
4.數據展現,數據做出來沒用,要可視化,做到MVP,就是快速做出來一個效果,不合適及時調整,這點有點類似于Scrum敏捷開發,數據展示的可以用datav,神策等,前端好的可以忽略,自己來畫頁面。
數據采集:
1.批數據采集,就是每天定時去數據庫抓取數據快照,我們用的maxComputer,可以根據需求,設置每天去數據庫備份一次快照,如何備份,如何設置數據源,如何設置出錯,在maxComputer都有文檔介紹,使用maxComputer需要注冊阿里云服務,https://help.aliyun.com/product/27797.html,鏈接是maxComputer文檔。
2.實時接口調用數據采集,可以用logHub,dataHub,流數據處理技術,DataHub具有高可用,低延遲,高可擴展,高吞吐的特點。
- 高吞吐:***支持單主題(Topic)每日T級別的數據量寫入,每個分片(Shard)支持***每日8000萬Record級別的寫入量。
- 實時性:通過DataHub ,您可以實時的收集各種方式生成的數據并進行實時的處理,
- 設計思路:首先寫一個sdk把公司所有后臺服務調用接口調用情況記錄下來,開辟線程池,把記錄下來的數據不停的往dataHub,logHub存儲,前提是設置好接收數據的dataHub表結構,https://help.aliyun.com/document_detail/47448.html?spm=a2c4g.11186623.3.2.nuizA4,這是dataHub文檔,下圖是數據監控,會看到數據會不停流入

3.前臺數據埋點,這些就要根據業務需求來設置了,也是通過流數據傳輸到數據倉庫,如上述第二步。
數據處理:
數據采集完成就可以對數據進行加工處理,可分為離線批處理,實時處理。
1.離線批處理maxComputer,這是阿里提供的一項大數據處理服務,是一種快速,完全托管的TB/PB級數據倉庫解決方案,編寫數據處理腳本,設置任務執行時間,任務執行條件,就可以按照你的要求,每天產生你需要的數據,https://help.aliyun.com/document_detail/30267.html?spm=a2c4g.11174283.3.2.0aBtdh,鏈接dataworks為文檔。下圖是檢測任務實例運行狀態

2.實時處理:采用storm/spark,目前接觸的只有storm,strom基本概念網上一大把,在這里講一下大概處理過程,首先設置要讀取得數據源,只要啟動storm就會不停息的讀取數據源。Spout,用來讀取數據。Tuple:一次消息傳遞的基本單元,理解為一組消息就是一個Tuple。stream,用來傳輸流,Tuple的集合。Bolt:接受數據然后執行處理的組件,用戶可以在其中執行自己想要的操作。可以在里邊寫業務邏輯,storm不會保存結果,需要自己寫代碼保存,把這些合并起來就是一個拓撲,總體來說就是把拓撲提交到服務器啟動后,他會不停讀取數據源,然后通過stream把數據流動,通過自己寫的Bolt代碼進行數據處理,然后保存到任意地方,關于如何安裝部署storm,如何設置數據源,網上都有教程,這里不多說。

數據展現:做了上述那么多,終于可以直觀的展示了,由于前端技術不行,借用了第三方展示平臺datav,datav支持兩種數據讀取模式,***種,直接讀取數據庫,把你計算好的數據,通過sql查出來,需要配置數據源,讀取數據之后按照給定的格式,進行格式化就可以展現出來,https://help.aliyun.com/document_detail/30360.html,鏈接為datav文檔。可以設置圖標的樣式,也可以設置參數,

第二種采用接口的形式,可以直接采用api,在數據區域配置為api,填寫接口地址,需要的參數即可,這里就不多說了。
這次先記錄這么多,以后再補充,內容為原創,若是有不對的地方還請評論糾正。