SQL Sever AlwaysOn在阿里云的突破
作者介紹
王方銘,阿里巴巴技術專家,從DBA到產品研發,伴隨阿里云數據庫產品成長至今,對數據庫技術、后端技術平臺建設有深刻的理解,目前主要負責RDS SQLServer產品研發工作。
早在2015年的時候,隨著阿里云業務突飛猛進的發展,SQL Server業務也積累了大批忠實客戶,其中一些體量較大的客戶,在類似大促的業務高峰時,RDS的單機規格(規格是按照“內存*CPU*IOPS”一定比例分配,根據底層資源不同都會有各自上限)已經不能滿足用戶的業務需求,在我們看來也需要做Scale Out了。
但SQL Server并沒有完備的中間件產品,所以無論是邏輯Sharding還是只讀分離,都需要用戶配合做應用改造,而從用戶角度看Sharding改動量很大,不是一時間能完成的,那么更多是寄希望于我們來提供讀寫分離的方案,滿足業務需求。
那么讀寫分離,我們***個想到的即是AlwaysOn技術。但由于當時AlwaysOn對域控和Windows群集都是強依賴,而這兩者又對我們所依賴的基礎設施有很大挑戰,需要做很多突破產品限制的非標準化操作才有可能實現,并且還有安全風險。所以***我們只能放棄AlwaysOn技術方案,重新設計方案幫助用戶度過難關。
面對這類客戶需求,我們的方案如何產品化是值得思考的。
一、產品快速發展
除了讀寫分離,產品上還有很多更重要的問題急需我們去解決,所以從2015年到2017年,我們經歷了一個飛速發展的階段,圍繞產品穩定性、多樣性以及用戶體驗做了非常多的事情,舉幾個點:
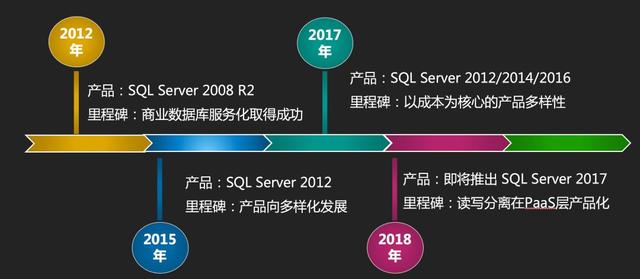
- 為了提高穩定性和用戶體驗我們***替換了底層架構,這也為后續產品多樣化發展打下基礎;
- 為了滿足不同用戶需求,推出了SQL Server 2008R2 / 2012 / 2014 / 2016 Web / Standard / Enterprise不同Version、Edition的組合版本;
- 為解決上云難問題推出了上云評估工具,以及針對不同版本、不同場景的上云方案全量備份數據上云SQL Server 2008 R2版、全量備份數據上云SQL Server 2012及以上版本、增量備份數據上云SQL Server 2012及以上版本、SQL Server實例級別數據庫上云;
- 為了提升用戶體驗支持更多特性,我們在SQL層提供了很多封裝的存儲過程,這里有些看似簡單的功能在面對外部的安全、內部的SQL鏡像等因素的共同作用下,實現的挑戰還是很大的;
- 為了讓專家服務更智能、更能貼近每個用戶,我們研發了SQL Server CloudDBA集合了云上大量性能、空間問題的解決方案。
在這當中依舊不斷有讀寫分離的用戶需求,每次遇到,我們都先引導到IaaS層用ECS自建實現。因為PaaS化的時機并不成熟。具體原因跟SQL Server當前的技術棧和云產品的結合有著密切的關系,這里也可以把我們背后的一些思考分享出來。
二、讀寫分離
首先明確我們討論的讀寫分離是什么,MySQL的讀寫分離大部分是利用中間層做路由解析,基本上可以實現對應用端透明,只有少部分場景需要用戶做適配。
SQL Server并沒有成熟的中間件產品,本質上講,是TDS(Tabular Data Stream)不完全開放的原因,如果要做也是有辦法的,只是投入的成本遠大于收益。基于此,SQL Server無論利用當前何種技術實現讀寫分離,對應用來講都需要做一些適配。即使是使用AlwaysOn技術,在鏈接驅動的參數配置上也會不同,所以我們后面討論的讀寫分離都是基于這個前提。
三、技術選型
我們對比了SQL Server所有相關的技術棧:
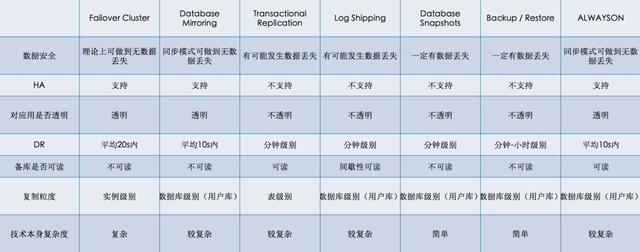
其中數據安全、HA(High Availability 高可用)、DR(Disaster Recovery 災難恢復)以及備庫是否可讀是我們最關注的。
這里的HA是指原生技術本身是否支持自動HA,當結合了部分云產品后,我們也有能力把不支持變為支持。數據安全和災難恢復的時間基本是原生技術決定的,備庫是否可讀是對單一技術的說明,但做一些技術組合是可以把不可讀變為可讀的(比如Database Mirroring + Database Snapshots)。
最終綜合來看Transactional Replication和AlwaysOn是我們覺得有機會做讀寫分離產品化的技術。
接著我們單獨來看這兩種技術對比:
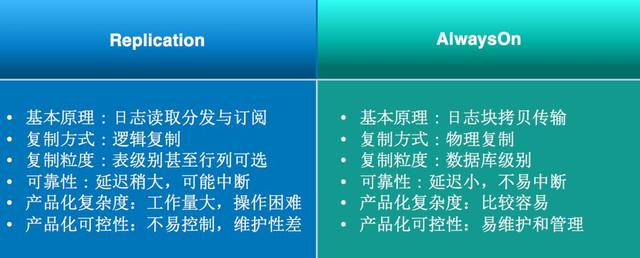
原理上講,Replication是邏輯復制,對比AlwaysOn的物理復制在性能、延遲、可靠性上都會有一定的差距。在產品復雜度讀、可控性上和易用性上,由于Replication過于靈活,細到表、列級別很難控制,無論用戶使用還是我們做產品化整個復雜度非常高,所以最終我們選用AlwaysOn。
四、AlwaysOn技術
AlwaysOn是原生支持High Availability和Disaster Recovery的技術,本身又分為Failover Cluster Instances(后續簡稱FCI)和Availability Groups(后續簡稱AG),下面的圖是FCI和AG的基礎架構:
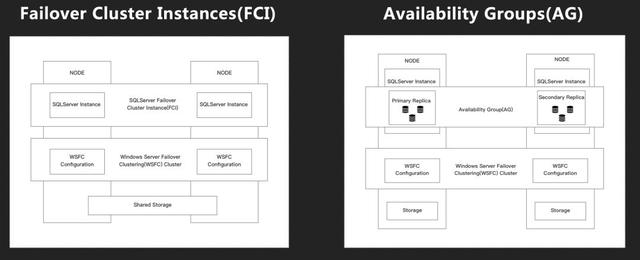
其中FCI和常規版本的AG都依賴Windows Server Failover Clustering(后續簡稱WSFC)。不同點在于,FCI是Share Storage,而AG是Share Nothing;FCI是實例級別同步,而AG是DB級別。
那么很容易想到,Share Nothing會有同步和異步的區別(和鏡像技術類似),其中兩者的區別點需要我們知道AlwaysOn的基本同步過程:
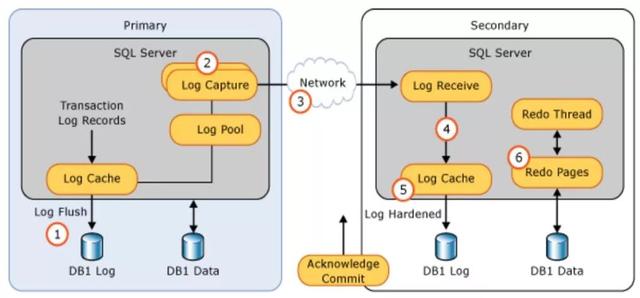
首先在Primary節點的日志(Commit/Log Block Write)會從Log Cache刷到磁盤,同時Primary節點的Log Capture也會把日志發送到其它所有Replica節點,對應節點的Log Receive線程把收到的日志同樣從Log Cache刷到磁盤,***會由Redo Thread應用這些日志刷到數據文件里。
這其中還有一步,就是在Secondary端刷日志的時候,如果Primary節點等待這次返回的Acknowlege Commit,那么就是同步模式;反之如果Primary端不等Secondary的返回,那么就是異步模式,兩者的區別由此展開。
這是基本的同步過程,但無論是AlwaysOn還是Database Mirroring都存在一種情況,即同步模式下如果Secondary端異常,Primary端沒有收到它的心跳,也沒有收到這次的Acknowlege Commit,那么也并不會算作寫入失敗。
因為它一旦認定Secondary異常,就不會等這次ACK,而是退化為類似異步的模式,但會把Secondary端的異常狀態記錄在基表里,通過相關視圖 :sys.dm_hadr_database_replica _states、sys.database_mirroring暴露出來,就是我們常見的NOT SYNCHRONIZING / Disconnect狀態。
這時候自動化運維系統或者DBA就需要做判斷處理,等到Secondary修復重新聯機后,會向Primary報告End of Log (EOL) LSN,Primary端再向它發送EOL LSN之后hardened的所有日志。
一旦Secondary端開始接收到這些日志,并逐步刷到日志文件中,那么整個AG或者Mirroring相關的視圖又會標記其狀態為Synchronizing,表明正在追趕,直到Last Hardened (LH) LSN達到主備一致狀態,這時重新回到同步模式。
以前的情況一直是這樣。直到SQLServer 2017 CU 1引入了REQUIRED_SYNCHRONIZ ED_SECONDARIES_TO_COMMIT這個參數,參數名字很長,但也基本包含了它的作用,應對剛才的場景是可以讓Primary端一直等到Secondary節點重新聯機并同步后再提供服務。
了解了AG同步、異步以及FCI,再總結下我們關心的點:
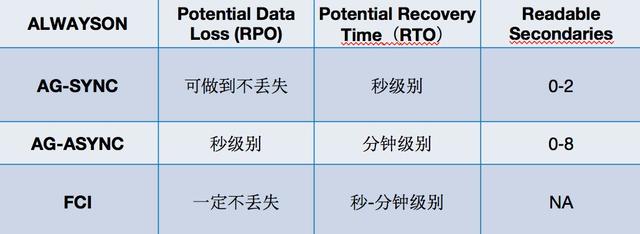
在實際方案中,這些也可以結合起來,最終再和阿里云產品整合做一個整體方案。之前也講到,阿里云從15年就開始做類似方案來解決用戶問題,一直到最終PaaS化,也過度了三個版本。
五、云上演進
***版本我們使用了ECS、SSD云盤、OSS、VPC、SLB作為基礎;在SQL技術上,我們使用SQL+WSFC+AD的方式,目前看這種方式支持的版本也非常多,從12到17都可以;驗證方式既可以用域控也可以用證書。
但有2個缺點:
- 成本高。除了Primary和兩個Secondary節點,還要有兩個AD節點,畢竟我們每個環節都要保證高可用;
- 穩定性不夠。網絡抖動的情況非常容易讓WSFC判斷異常,SQL端DB同時出現不可用。
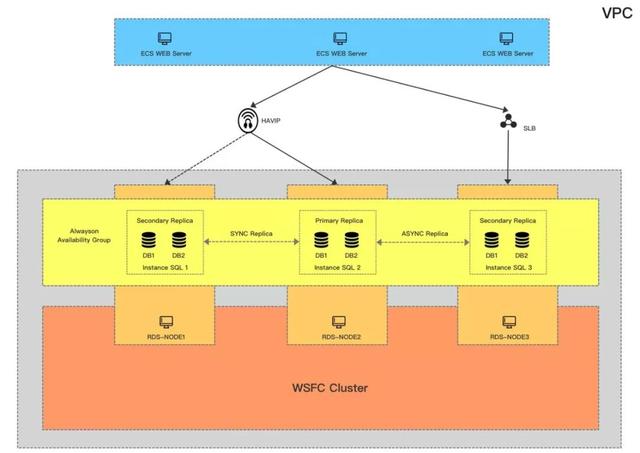
這是第二版的架構,跟***版相比,我們用到了HAVIP來解決監聽器問題,去掉了AD只能用證書做驗證,但也因此最小資源開銷降低到3。
這個方案也是之前在阿里云上用的比較多的,但同***個方案一樣,在網絡穩定性上會有很多挑戰,因為我們未來面對的場景不只是同城跨可用區,還會有更多跨Region以及打通海外的場景,所以這個方案也只能Cover一部分用戶的需求,但對我們不是一個最終方案。
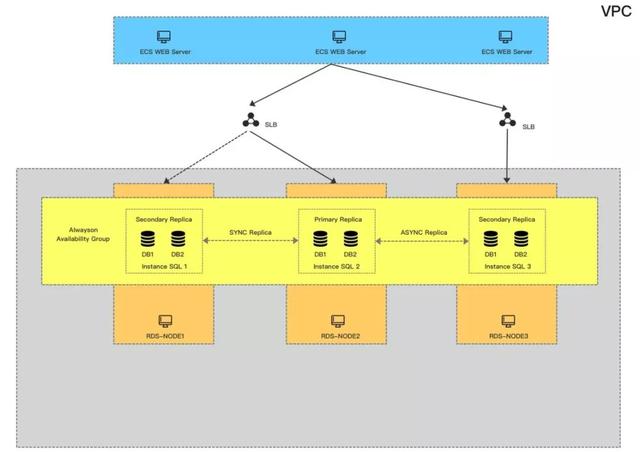
最終我們找到了方案三,去除了WSFC和AD,只關注基礎云產品和SQL本身。
最重要的是跟方案二相比,對網絡的抖動敏感度會更低也更可控,最多是在Primary端出現Send Queue的堆積,這個我們完全可以通過SQLServer相關的Performance Counter監控并做一些修復調整。
但沒有方案是***的,可控性強的代價是,這種無群集無域控架構原生是不具備HADR能力的,這點熟悉WSFC的同學可以知道。之前架構的HA都是依賴WSFC,包括健康檢查、資源管理、分布式元數據通知維護以及故障轉移,所以這時候就必須我們自己去解決這個問題。
為此我們也做了很多努力,最終實現了支持AlwaysOn無域控無群集的HA系統,不依賴Cluster完全自主可控的HA。
六、產品化
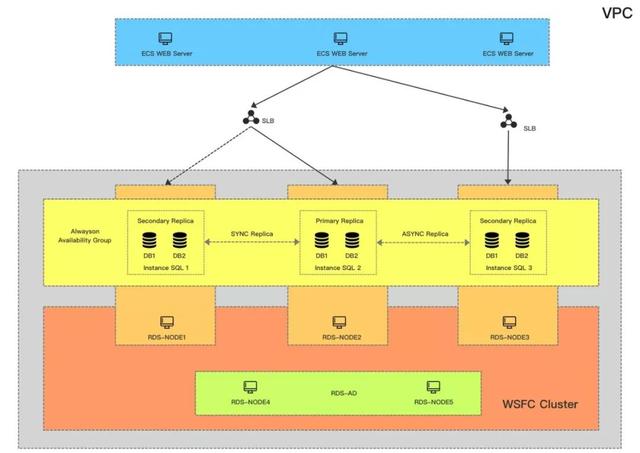
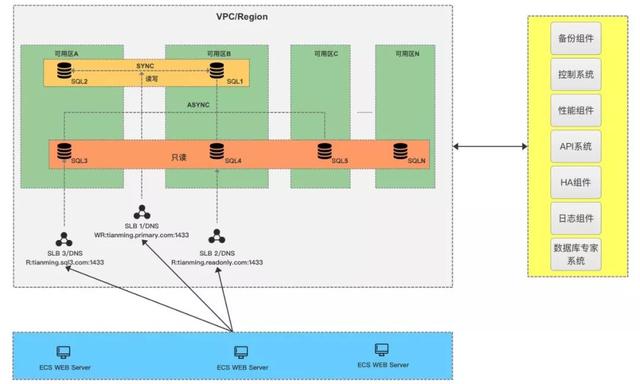
最終的產品架構如下,首先會保證有2個同步節點做主備,并且盡量分配在不同的可用區,其它只讀節點默認是異步,最多可以有7個只讀節點;用戶的訪問鏈路可以有三種:
讀寫鏈路:會指向兩個同步節點,由我們的HA來保證高可用;
統一只讀鏈路:根據用戶需求設定,把指定的Replica節點綁定到一起按照一定的權重比例分配鏈接;
單一只讀鏈路:即每個只讀節點會提供一個單獨的鏈接,讓用戶也可以自己靈活配置,比如用戶的APP Server就是在可用區A,那么就可以直接訪問可用區A的只讀地址,避免再通過統一只讀被路由到其它區域。
至此,SQLServer AlwaysOn已經在阿里云PaaS化,當然目前只是支持最主要功能,后續還有很多可以完善豐富的地方。如果大家有任何好的建議或者問題,也很歡迎留言與我交流。