阿里云EMR Remote Shuffle Service在小米的實踐

阿里云EMR自2020年推出Remote Shuffle Service(RSS)以來,幫助了諸多客戶解決Spark作業的性能、穩定性問題,并使得存算分離架構得以實施,與此同時RSS也在跟合作方小米的共建下不斷演進。本文將介紹RSS的最新架構,在小米的實踐,以及開源。
一 問題回顧
Shuffle是大數據計算中最為重要的算子。首先,覆蓋率高,超過50%的作業都包含至少一個Shuffle[2]。其次,資源消耗大,阿里內部平臺Shuffle的CPU占比超過20%,LinkedIn內部Shuffle Read導致的資源浪費高達15%[1],單Shuffle數據量超100T[2]。第三,不穩定,硬件資源的穩定性CPU>內存>磁盤≈網絡,而Shuffle的資源消耗是倒序。OutOfMemory和Fetch Failure可能是Spark作業最常見的兩種錯誤,前者可以通過調參解決,而后者需要系統性重構Shuffle。
傳統Shuffle如下圖所示,Mapper把Shuffle數據按PartitionId排序寫盤后交給External Shuffle Service(ESS)管理,Reducer從每個Mapper Output中讀取屬于自己的Block。
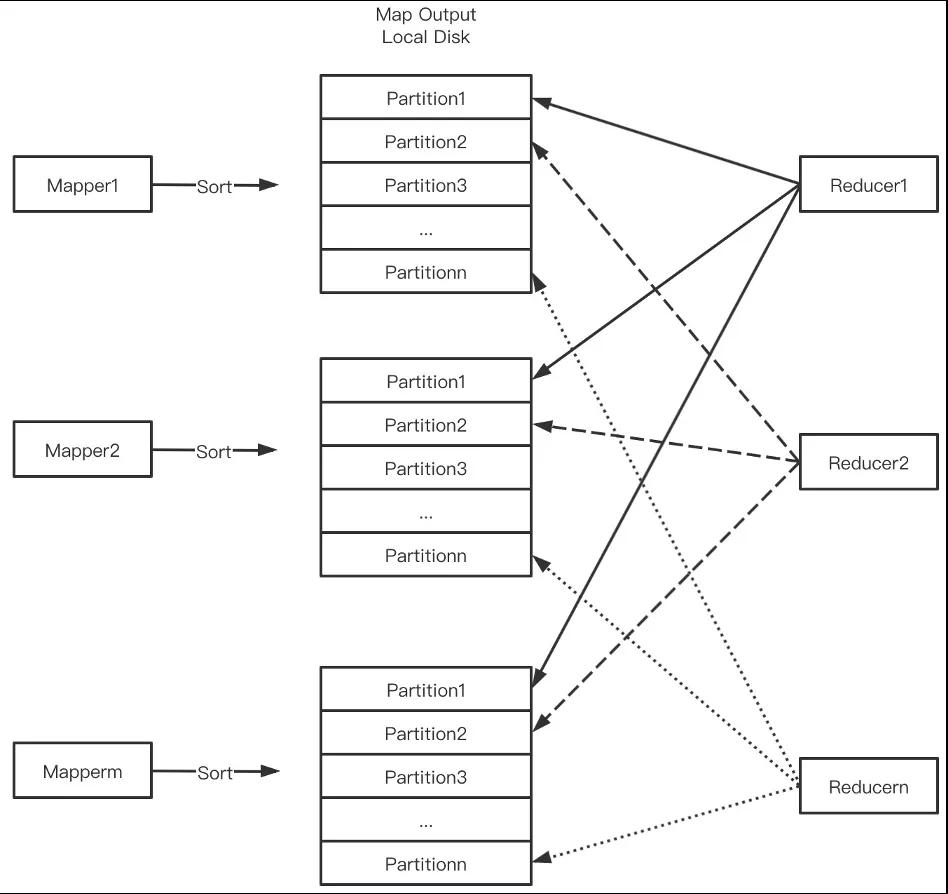
傳統Shuffle存在以下問題。
- 本地盤依賴限制了存算分離。存算分離是近年來興起的新型架構,它解耦了計算和存儲,可以更靈活地做機型設計:計算節點強CPU弱磁盤,存儲節點強磁盤強網絡弱CPU。計算節點無狀態,可根據負載彈性伸縮。存儲端,隨著對象存儲(OSS, S3)+數據湖格式(Delta, Iceberg, Hudi)+本地/近地緩存等方案的成熟,可當作容量無限的存儲服務。用戶通過計算彈性+存儲按量付費獲得成本節約。然而,Shuffle對本地盤的依賴限制了存算分離。
- 寫放大。當Mapper Output數據量超過內存時觸發外排,從而引入額外磁盤IO。
- 大量隨機讀。Mapper Output屬于某個Reducer的數據量很小,如Output 128M,Reducer并發2000,則每個Reducer只讀64K,從而導致大量小粒度隨機讀。對于HDD,隨機讀性能極差;對于SSD,會快速消耗SSD壽命。
- 高網絡連接數,導致線程池消耗過多CPU,帶來性能和穩定性問題。
- Shuffle數據單副本,大規模集群場景壞盤/壞節點很普遍,Shuffle數據丟失引發的Stage重算帶來性能和穩定性問題。
二 RSS發展歷程
針對Shuffle的問題,工業界嘗試了各種方法,近兩年逐漸收斂到Push Shuffle的方案。
1 Sailfish
Sailfish[3](2012)最早提出Push Shuffle + Partition數據聚合的方法,對大作業有20%-5倍的性能提升。Sailfish魔改了分布式文件系統KFS[4],不支持多副本。
2 Dataflow
Goolge BigQuery和Cloud Dataflow[5](2018)實現了Shuffle跟計算的解耦,采用多層存儲(內存+磁盤),除此之外沒有披露更多技術細節。
3 Riffle
Facebook Riffle[2](2018)采用了在Mapper端Merge的方法,物理節點上部署的Riffle服務負責把此節點上的Shuffle數據按照PartitionId做Merge,從而一定程度把小粒度的隨機讀合并成較大粒度。
4 Cosco
Facebook Cosco[6][7](2019)采用了Sailfish的方法并做了重設計,保留了Push Shuffle + Parititon數據聚合的核心方法,但使用了獨立服務。服務端采用Master-Worker架構,使用內存兩副本,用DFS做持久化。Cosco基本上定義了RSS的標準架構,但受到DFS的拖累,性能上并沒有顯著提升。
5 Zeus
Uber Zeus[8][9](2020)同樣采用了去中心化的服務架構,但沒有類似etcd的角色維護Worker狀態,因此難以做狀態管理。Zeus通過Client雙推的方式做多副本,采用本地存儲。
6 RPMP
Intel RPMP[10](2020)依靠RDMA和PMEM的新硬件來加速Shuffle,并沒有做數據聚合。
7 Magnet
LinkedIn Magnet[1](2021)融合了本地Shuffle+Push Shuffle,其設計哲學是"盡力而為",Mapper的Output寫完本地后,Push線程會把數據推給遠端的ESS做聚合,且不保證所有數據都會聚合。受益于本地Shuffle,Magnet在容錯和AE的支持上的表現更好(直接Fallback到傳統Shuffle)。Magnet的局限包括依賴本地盤,不支持存算分離;數據合并依賴ESS,對NodeManager造成額外壓力;Shuffle Write同時寫本地和遠端,性能達不到最優。Magnet方案已經被Apache Spark接納,成為默認的開源方案。
8 FireStorm
FireStorm[11](2021)混合了Cosco和Zeus的設計,服務端采用Master-Worker架構,通過Client多寫實現多副本。FireStorm使用了本地盤+對象存儲的多層存儲,采用較大的PushBlock(默認3M)。FireStorm在存儲端保留了PushBlock的元信息,并記錄在索引文件中。FireStorm的Client緩存數據的內存由Spark MemoryManager進行管理,并通過細顆粒度的內存分配(默認3K)來盡量避免內存浪費。
從上述描述可知,當前的方案基本收斂到Push Shuffle,但在一些關鍵設計上的選擇各家不盡相同,主要體現在:
- 集成到Spark內部還是獨立服務。
- RSS服務側架構,選項包括:Master-Worker,含輕量級狀態管理的去中心化,完全去中心化。
- Shuffle數據的存儲,選項包括:內存,本地盤,DFS,對象存儲。
- 多副本的實現,選項包括:Client多推,服務端做Replication。
阿里云RSS[12][13]由2020年推出,核心設計參考了Sailfish和Cosco,并且在架構和實現層面做了改良,下文將詳細介紹。
三 阿里云RSS核心架構
針對上一節的關鍵設計,阿里云RSS的選擇如下:
- 獨立服務。考慮到將RSS集成到Spark內部無法滿足存算分離架構,阿里云RSS將作為獨立服務提供Shuffle服務。
- Master-Worker架構。通過Master節點做服務狀態管理非常必要,基于etcd的狀態狀態管理能力受限。
- 多種存儲方式。目前支持本地盤/DFS等存儲方式,主打本地盤,將來會往分層存儲方向發展。
- 服務端做Replication。Client多推會額外消耗計算節點的網絡和計算資源,在獨立部署或者服務化的場景下對計算集群不友好。
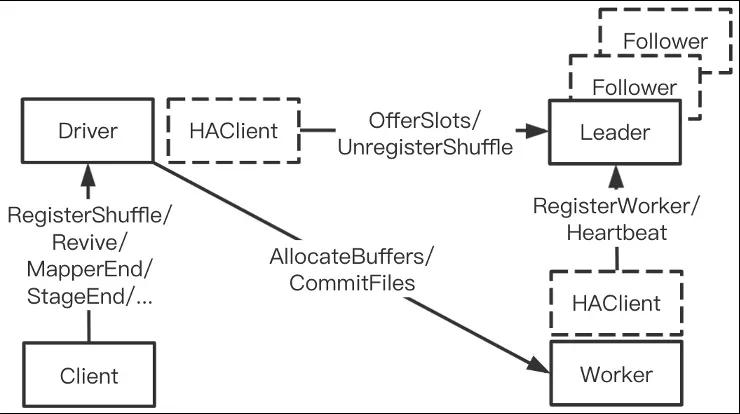
下圖展示了阿里云RSS的關鍵架構,包含Client(RSS Client, Meta Service),Master(Resource Manager)和Worker三個角色。Shuffle的過程如下:
- Mapper在首次PushData時請求Master分配Worker資源,Worker記錄自己所需要服務的Partition列表。
- Mapper把Shuffle數據緩存到內存,超過閾值時觸發Push。
- 隸屬同個Partition的數據被Push到同一個Worker做合并,主Worker內存接收到數據后立即向從Worker發起Replication,數據達成內存兩副本后即向Client發送ACK,Flusher后臺線程負責刷盤。
- Mapper Stage運行結束,MetaService向Worker發起CommitFiles命令,把殘留在內存的數據全部刷盤并返回文件列表。
- Reducer從對應的文件列表中讀取Shuffle數據。

阿里云RSS的核心架構和容錯方面的介紹詳見[13],本文接下來介紹阿里云RSS近一年的架構演進以及不同于其他系統的特色。
1 狀態下沉
RSS采用Master-Worker架構,最初的設計中Master統一負責集群狀態管理和Shuffle生命周期管理。集群狀態包括Worker的健康度和負載;生命周期包括每個Shuffle由哪些Worker服務,每個Worker所服務的Partition列表,Shuffle所處的狀態(Shuffle Write,CommitFile,Shuffle Read),是否有數據丟失等。維護Shuffle生命周期需要較大數據量和復雜數據結構,給Master HA的實現造成阻力。同時大量生命周期管理的服務調用使Master易成為性能瓶頸,限制RSS的擴展性。
為了緩解Master壓力,我們把生命周期狀態管理下沉到Driver,由Application管理自己的Shuffle,Master只需維護RSS集群本身的狀態。這個優化大大降低Master的負載,并使得Master HA得以順利實現。
2 Adaptive Pusher
在最初的設計中,阿里云RSS跟其他系統一樣采用Hash-Based Pusher,即Client會為每個Partition維護一個(或多個[11])內存Buffer,當Buffer超過閾值時觸發推送。這種設計在并發度適中的情況下沒有問題,而在超大并發度的情況下會導致OOM。例如Reducer的并發5W,在小Buffer[13]的系統中(64K)極端內存消耗為64K*5W=3G,在大Buffer[11]的系統中(3M)極端內存消耗為3M*5W=146G,這是不可接受的。針對這個問題,我們開發了Sort-Based Pusher,緩存數據時不區分Partition,當總的數據超過閾值(i.e. 64M)時對當前數據按照PartitionId排序,然后把數據Batch后推送,從而解決內存消耗過大的問題。
Sort-Based Pusher會額外引入一次排序,性能上比Hash-Based Pusher略差。我們在ShuffleWriter初始化階段根據Reducer的并發度自動選擇合適的Pusher。
3 磁盤容錯
出于性能的考慮,阿里云RSS推薦本地盤存儲,因此處理壞/慢盤是保證服務可靠性的前提。Worker節點的DeviceMonitor線程定時對磁盤進行檢查,檢查項包括IOHang,使用量,讀寫異常等。此外Worker在所有磁盤操作處(創建文件,刷盤)都會捕捉異常并上報。IOHang、讀寫異常被認為是Critical Error,磁盤將被隔離并終止該磁盤上的存儲服務。慢盤、使用量超警戒線等異常僅將磁盤隔離,不再接受新的Partition存儲請求,但已有的Partition服務保持正常。在磁盤被隔離后,Worker的容量和負載將發生變化,這些信息將通過心跳發送給Master。
4 滾動升級
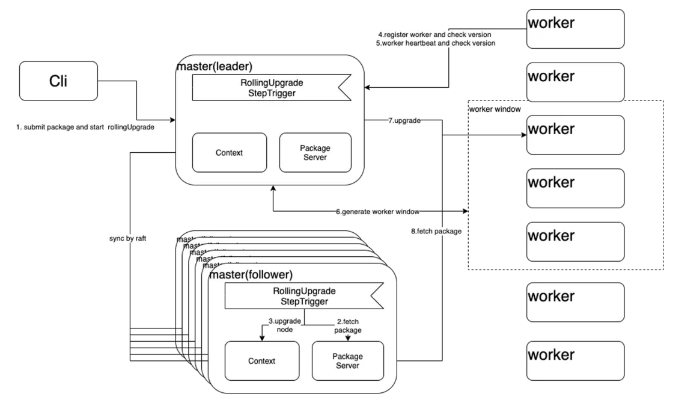
RSS作為常駐服務,有永不停服的要求,而系統本身總在向前演進,因此滾動升級是必選的功能。盡管通過Sub-Cluster部署方式可以繞過,即部署多個子集群,對子集群做灰度,灰度的集群暫停服務,但這種方式依賴調度系統感知正在灰度的集群并動態修改作業配置。我們認為RSS應該把滾動升級閉環掉,核心設計如下圖所示。Client向Master節點的Leader角色(Master實現了HA,見上文)發起滾動升級請求并把更新包上傳給Leader,Leader通過Raft協議修改狀態為滾動升級,并啟動第一階段的升級:升級Master節點。Leader首先升級所有的Follower,然后替換本地包并重啟。在Leader節點改變的情況下,升級過程不會中斷或異常。Master節點升級結束后進入第二階段:Worker節點升級。RSS采用滑動窗口做升級,窗口內的Worker盡量優雅下線,即拒絕新的Partition請求,并等待本地Shuffle結束。為了避免等待時間過長,會設置超時時間。此外,窗口內的Worker選擇會盡量避免同時包含主從兩副本以降低數據丟失的概率。
5 混亂測試框架
對于服務來說,僅依靠UT、集成測試、e2e測試等無法保證服務可靠性,因為這些測試無法覆蓋線上復雜環境,如壞盤、CPU過載、網絡過載、機器掛掉等。RSS要求在出現這些復雜情況時保持服務穩定,為了模擬線上環境,我們開發了仿真(混亂)測試框架,在測試環境中模擬線上可能出現的異常,同時保證滿足RSS運行的最小運行環境,即至少3個Master節點和2個Worker節點可用,并且每個Worker節點至少有一塊盤。我們持續對RSS做此類壓力測試。
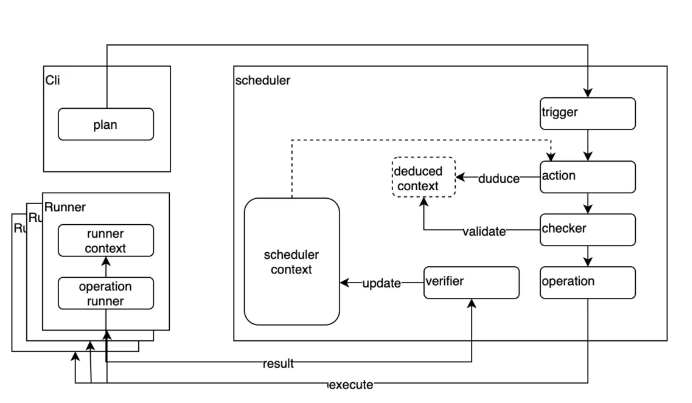
仿真測試框架架構如下圖所示,首先定義測試Plan來描述事件類型、事件觸發的順序及持續時間,事件類型包括節點異常,磁盤異常,IO異常,CPU過載等。客戶端將Plan提交給Scheduler,Scheduler根據Plan的描述給每個節點的Runner發送具體的Operation,Runner負責具體執行并匯報當前節點的狀態。在觸發Operation之前,Scheduler會推演該事件發生產生的后果,若導致無法滿足RSS的最小可運行環境,將拒絕此事件。
我們認為仿真測試框架的思路是通用設計,可以推廣到更多的服務測試中。
6 多引擎支持
Shuffle是通用操作,不跟引擎綁定,因此我們嘗試了多引擎支持。當前我們支持了Hive+RSS,同時也在探索跟流計算引擎(Flink),MPP引擎(Presto)結合的可能性。盡管Hive和Spark都是批計算引擎,但Shuffle的行為并不一致,最大的差異是Hive在Mapper端做排序,Reducer只做Merge,而Spark在Reducer端做排序。由于RSS暫未支持計算,因此需要改造Tez支持Reducer排序。此外,Spark有干凈的Shuffle插件接口,RSS只需在外圍擴展,而Tez沒有類似抽象,在這方面也有一定侵入性。
當前大多數引擎都沒有Shuffle插件化的抽象,需要一定程度的引擎修改。此外,流計算和MPP都是上游即時Push給下游的模式,而RSS是上游Push,下游Pull的模式,這兩者如何結合也是需要探索的。
7 測試
我們對比了阿里云RSS、Magent及開源系統X。由于大家的系統還在向前演進,因此測試結果僅代表當前。
測試環境
Header * 1: ecs.g6e.4xlarge, 16 * 2.5GHz/3.2GHz, 64GiB, 10Gbps
Worker * 3: ecs.g6e.8xlarge, 32 * 2.5GHz/3.2GHz, 128GiB, 10Gbps
阿里云RSS vs. Magnet
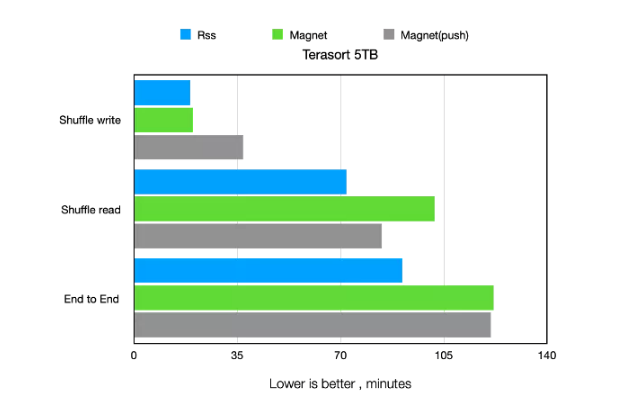
5T Terasort的性能測試如下圖所示,如上文描述,Magent的Shuffle Write有額外開銷,差于RSS和傳統做法。Magent的Shuffle Read有提升,但差于RSS。在這個Benchmark下,RSS明顯優于另外兩個,Magent的e2e時間略好于傳統Shuffle。
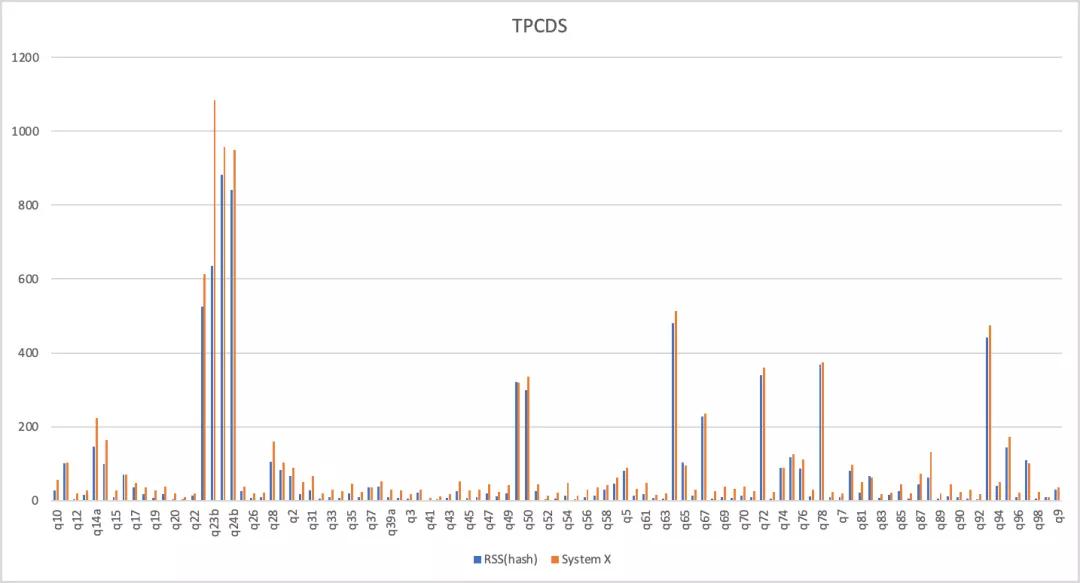
阿里云RSS vs. 開源系統X
RSS跟開源系統X在TPCDS-3T的性能對比如下,總時間RSS快了20%。
穩定性
在穩定性方面,我們測試了Reducer大規模并發的場景,Magnet可以跑通但時間比RSS慢了數倍,System X在Shuffle Write階段報錯。
四 阿里云RSS在小米的實踐
1 現狀及痛點
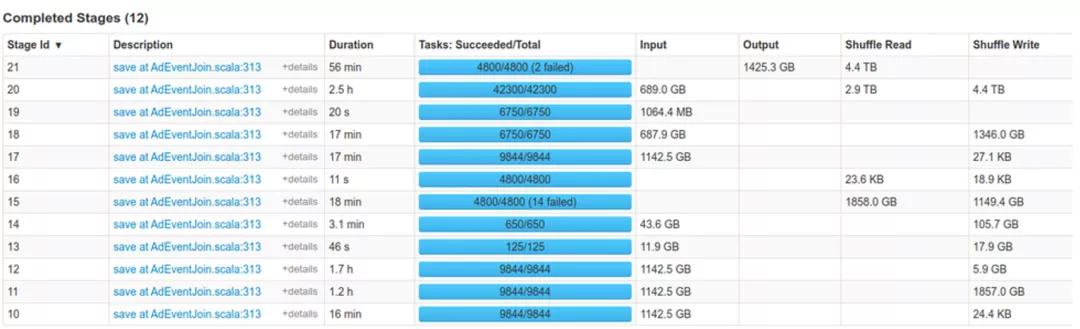
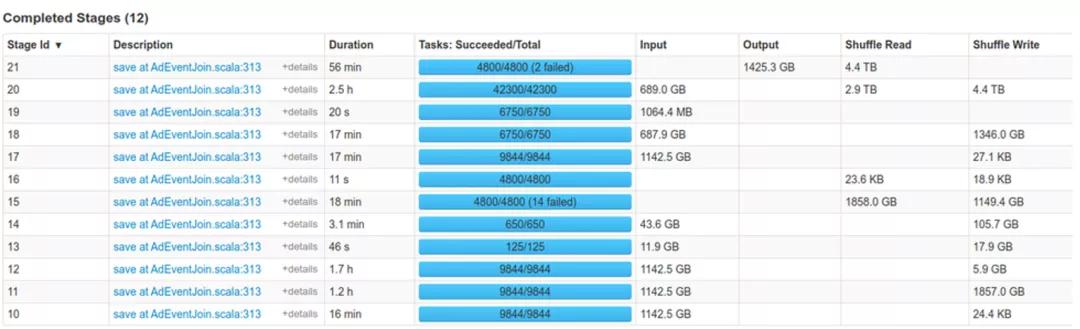
小米的離線集群以Yarn+HDFS為主,NodeManager和DataNode混合部署。Spark是主要的離線引擎,支撐著核心計算任務。Spark作業當前最大的痛點集中在Shuffle導致的穩定性差,性能差和對存算分離架構的限制。在進行資源保證和作業調優后,作業失敗原因主要歸結為Fetch Failure,如下圖所示。由于大部分集群使用的是HDD,傳統Shuffle的高隨機讀和高網絡連接導致性能很差,低穩定性帶來的Stage重算會進一步加劇性能回退。此外,小米一直在嘗試利用存算分離架構的計算彈性降低成本,但Shuffle對本地盤的依賴造成了阻礙。

2 RSS在小米的落地
小米一直在關注Shuffle優化相關技術,21年1月份跟阿里云EMR團隊就RSS項目建立了共創關系,3月份第一個生產集群上線,開始接入作業,6月份第一個HA集群上線,規模達100+節點,9月份第一個300+節點上線,集群默認開啟RSS,后續規劃會進一步擴展RSS的灰度規模。
在落地的過程,小米主導了磁盤容錯的開發,大大提高了RSS的服務穩定性,技術細節如上文所述。此外,在前期RSS還未完全穩定階段,小米在多個環節對RSS的作業進行了容錯。在調度端,若開啟RSS的Spark作業因Shuffle報錯,則Yarn的下次重試會回退到ESS。在ShuffleWriter初始化階段,小米主導了自適應Fallback機制,根據當前RSS集群的負載和作業的特征(如Reducer并發是否過大)自動選擇RSS或ESS,從而提升穩定性。
3 效果
接入RSS后,Spark作業的穩定性、性能都取得了顯著提升。之前因Fetch Failure失敗的作業幾乎不再失敗,性能平均有20%的提升。下圖展示了接入RSS前后作業穩定性的對比。
ESS:
RSS:
下圖展示了接入RSS前后作業運行時間的對比。
ESS:
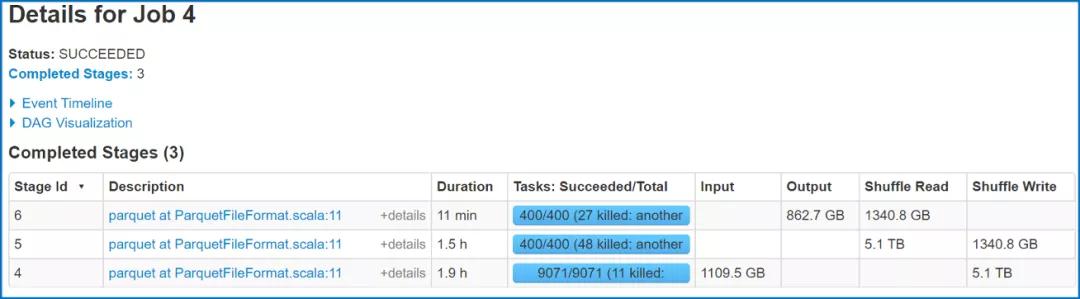
RSS:
在存算分離方面,小米海外某集群接入RSS后,成功上線了1600+ Core的彈性集群,且作業運行穩定。
在阿里云EMR團隊及小米Spark團隊的共同努力下,RSS帶來的穩定性和性能提升得到了充分的驗證。后續小米將會持續擴大RSS集群規模以及作業規模,并且在彈性資源伸縮場景下發揮更大的作用。
五 開源
重要的事說三遍:“阿里云RSS開源啦!” X 3
git地址: https://github.com/alibaba/RemoteShuffleService
開源代碼包含核心功能及容錯,滿足生產要求。
計劃中的重要Feature:
- AE
- Spark多版本支持
- Better 流控
- Better 監控
- Better HA
- 多引擎支持
歡迎各路開發者共建!
六 Reference
[1]Min Shen, Ye Zhou, Chandni Singh. Magnet: Push-based Shuffle Service for Large-scale Data Processing. VLDB 2020.
[2]Haoyu Zhang, Brian Cho, Ergin Seyfe, Avery Ching, Michael J. Freedman. Riffle: Optimized Shuffle Service for Large-Scale Data Analytics. EuroSys 2018.
[3]Sriram Rao, Raghu Ramakrishnan, Adam Silberstein. Sailfish: A Framework For Large Scale Data Processing. SoCC 2012.
[4]KFS. http://code.google.com/p/kosmosfs/
[5]Google Dataflow Shuffle. https://cloud.google.com/blog/products/data-analytics/how-distributed-shuffle-improves-scalability-and-performance-cloud-dataflow-pipelines
[6]Cosco: An Efficient Facebook-Scale Shuffle Service. https://databricks.com/session/cosco-an-efficient-facebook-scale-shuffle-service
[7]Flash for Apache Spark Shuffle with Cosco. https://databricks.com/session_na20/flash-for-apache-spark-shuffle-with-cosco
[8]Uber Zeus. https://databricks.com/session_na20/zeus-ubers-highly-scalable-and-distributed-shuffle-as-a-service
[9]Uber Zeus. https://github.com/uber/RemoteShuffleService
[10]Intel RPMP. https://databricks.com/session_na20/accelerating-apache-spark-shuffle-for-data-analytics-on-the-cloud-with-remote-persistent-memory-pools
[11]Tencent FireStorm. https://github.com/Tencent/Firestorm
[12]Aliyun RSS在趣頭條的實踐. https://developer.aliyun.com/article/779686
[13]Aliyun RSS架構. https://developer.aliyun.com/article/772329