揭穿機器學習“皇帝的新裝”
我們常把機器學習描述為一種使用數據模式標記事物的神奇技術。聽起來艱澀,但事實上,撥開層層概念,機器學習的核心簡單到令人尷尬。
本文將用一個葡萄酒是不是好喝的例子,讓你迅速了解整個機器學習的技術過程。
數據
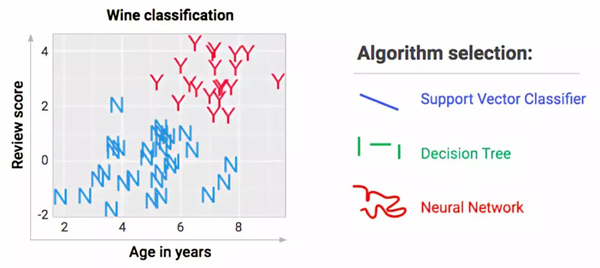
想象我們品嘗了50種葡萄酒,并且為了方便展示,我在下面進行了數據可視化。每款酒的數據包括年份、分數,再加上我們想學的特征:Y代表好喝,N代表不好喝。
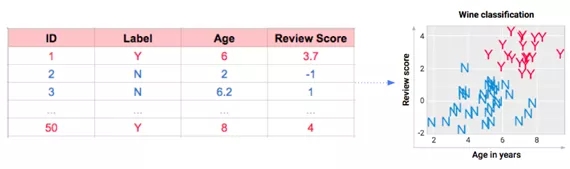
上圖的左側是表格模式,有圖展示信息的方式更加友好。如果你想要使用數據集術語,比如特性和實例,來描述這些數據,以下是一個指南。
算法
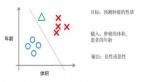
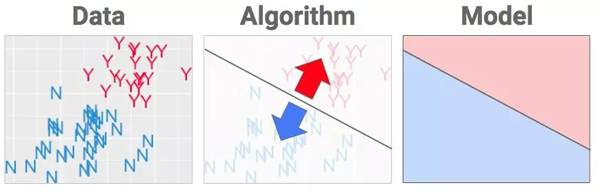
通過選擇要使用的機器學習算法,我們可以得到我們想要的輸出。在這個問題中,算法的全部工作就是把上圖中紅色的東西和藍色的東西分開。
機器學習算法的目的是在數據中選擇最合理的位置設置邊界。
如果你想劃一條線,恭喜你!你剛剛發明了一個叫作感知器機器學習算法。是的,這么科幻的名字描述的其實是一種非常簡單的概念!隨著學習的深入,你會發現被機器學習中的術語所嚇到稀松平常,但它們的內涵通常都配不上這個名字的復雜度。
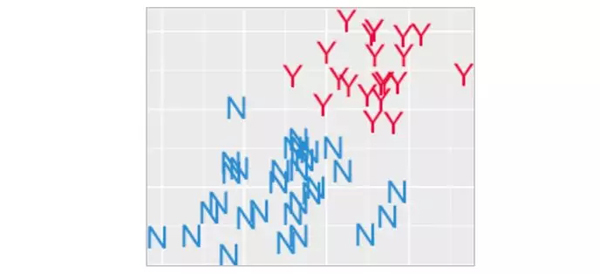
如果是你,你將如何分開藍色和紅色?
可能你會說一條平直的線就夠了。但我們的目標是把Y和N分開,而不是裝飾性的地平線。
機器學習算法的目的是選擇最合理的位置設置邊界,這是由據點到達的位置來決定的。但它是怎么做到的呢?一般來說,是通過優化一個目標函數。
優化
如果計劃給自己的博客文章做優化,我們可以這樣想:目標函數就像棋盤游戲得分的規則,優化它就是想出如何玩才能讓玩得更好并贏到最好的分數。
目標函數(損失函數)就像棋盤游戲的積分系統。
在機器學習的傳統中,我們更喜歡棍棒而不是胡蘿卜--分數是對錯誤的懲罰(在分界線的錯誤一側貼上標簽),而游戲就是去盡可能的得到盡量少的錯誤分數。這就是為什么ML中的目標函數往往被稱為“損失函數”,即目標是最小化損失。
現在我們可以回到最開始的問題了,把你的手指水平地對著屏幕并不斷畫出直線,直到你得到一個零分的結果(即沒有一點能夠逃避你充滿力量的、憤怒的手指所畫出來的線)。
希望您找到的解決方案是這樣的:

希望你能聰明地意識到,在上面的三個解決方案中,最右邊的是最好的。
如果你喜歡多樣性,你會喜歡算法的。因為它們太多了,并且它們之間的不同之處往往在于它們如何在不同的位置上嘗試分離邊界。
在優化問題中,以微小的增量旋轉邊界顯然是不靠譜的。還有更好的方法可以更快地到達最優位置。 一些研究人員畢生致力于想出在最少的轉變中獲得最好的邊界位置的方法,不管數據域看起來有多不正常(由你的輸入決定)。
另一個變化的來源是邊界的形狀。原來地邊界不一定是直的。不同的算法使用不同的邊界。
當我們選擇這些各種各樣的名稱時,我們只是選擇在標簽之間繪制的邊界的形狀,即在選擇我們要用一條對角線,多條水平和豎直線還是靈活的波形短線去分隔它們?
潮人算法
如今,沒有一位數據科學家再使用簡陋的直線了。靈活多變的形狀在當今大多數的人群中都很受歡迎的(你可能知道,例如神經網絡——雖然他們沒有太多的神經,他們的名字在半個多世紀前就被命名了,而且似乎沒有人喜歡我的建議——就是我們把他們重新命名為“瑜伽網絡”或“多層數學運算”)。

如果你一直期望的是有魔力的算法,那么早一點失望,就早一點清醒,當這些科幻迷信般的興奮褪去,你才會新生出做真正酷的事情的篤定。機器學習本身可能平淡無奇,但是你可以用它做的事情卻可以驚天動地,它能讓你寫出你完全想不到的程序代碼,讓你可以自動化那些無法言喻的過程,不要嫌棄機器學習的簡單,杠桿也很簡單,但是它可以撬動整個世界
除了這種市場營銷式的用其他線性算法和智能神經網絡做對比,更值得我們關注的是這些算法的柔韌擴展性。雖然其他算法在處理數據拉伸變換時不那么智能,但是天底下沒有免費的午餐,運用神經網絡也是要付出昂貴代價的(下文有更多說明),所以不要相信那些宣稱神經網絡永遠是最完美方案的人。
神經網絡也可以叫做瑜伽網絡
這些奇奇怪怪的算法名稱不過是告訴你什么形狀的分界線會被放入你的數據集中。如果你是一位致力于將機器學習投入實際應用的學習者,那么記不住這些名詞也沒關系。實際操作時,你只需要把你的數據扔到盡可能多的算法里去嘗試,然后重復訓練那些看起來最有希望的算法。證明巧克力布丁最好的方法就是吃掉它,所以我們開始享用吧。
就算你認認真真的學習了資料,你也不可能第一次就碰巧拿到正確的算法。別焦慮,這不是只有標準答案的競賽。盡管抱著玩的心態,敲敲打打,多多琢磨。對機器學習這個布丁的證明就隱藏在吃透它的過程里-這套算法適用于新的數據嗎?你不用擔心算法是如何工作的,將這個問題留給專門設計新算法的研究者們吧 (而且你最終會越來越熟悉這些術語,就像你會記住那些播爛了的肥皂劇里的角色一樣,久而久之,你會記住所有這些拗口的術語)
模型
一旦確立好分界線,算法就結束了。而你從算法中得到的就是你一直想要的:模型。所謂模型不過是“計算機菜譜”的酷炫叫法,它實際上就是計算機用來將數據轉換成決策的指令。當我再次展示一瓶新的葡萄酒時,如果數據落在藍色區域,就被命名為藍。落在紅色區域?那就命名為紅。
標簽
一旦你將剛出爐的模型投入使用,在向計算機輸入酒齡,評級分數后,你的系統就會查找這瓶紅酒數據對應的區域,并輸出一個標簽。
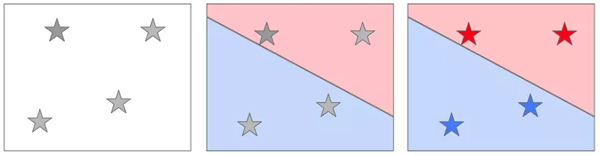
當我有四瓶新的葡萄酒時,我只需要將輸入的數據和菜單上的紅藍區域匹配,并插上標簽,看,就是這么簡單!
那我們怎么知道這個算法到底可行不可行呢?就像檢驗一群敲擊鍵盤的猴子是不是在寫莎士比亞詩集一樣,我們可以通過檢查輸出來判斷。
吃掉布丁才可以證明布丁
用大量的新數據來檢測你的系統,確保你的系統在這些數據上都運行良好。事實上,不管是面對一個算法還是一個拿著計算機菜譜找到你的程序員,你都應該用大量的數據去檢測。
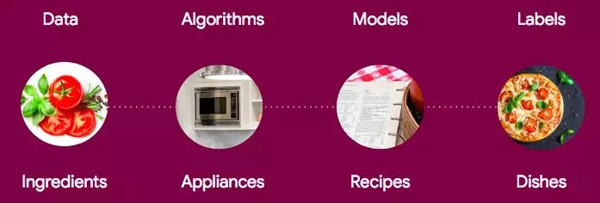
這是我另一篇文章里一份非常形象的總結:
詩人一般的機器學習
如果這句話讓你很困惑,也許下面這個類比你會更容易接受:一位詩人挑選了一種方法(算法)來組織紙面上的詞語,這種方法決定了最后詩歌的形式(邊界形狀)
例如決定這首詩是日式俳句還是十四行詩。一旦在十四行詩這個骨架上最優化地添加詞語,使其充實豐滿,那它就會變成一首詩(模型)。至于詩歌為什么會變成計算機菜譜,饒了我吧-我也不知道,但是我非常歡迎其他的建議。不管怎樣,這個類比的其他部分還是說得通的。
機器學習模型VS傳統編程代碼
不得不指出的是機器學習的這份菜譜和程序猿著眼于問題而手工敲出的代碼沒有很大區別。忘掉對機器學習人格化的幻想吧,機器學習模型和常規代碼在概念上沒有區別。是的,就是那些腦袋里充滿主觀意見和咖啡因的程序猿手寫出的菜譜代碼
不要到處嚷嚷著“再訓練”-這個術語不過是指在加入新數據樣本后需要再跑一次算法來調整模型邊界而已。但是這個名詞讓機器學習聽起來像一個活的生物,好像它天生就和那些標準程序猿產品不一樣,事實上,程序猿也可以好好坐下來根據新的信息來手工調整代碼,如果你覺得你的機器學習系統可以加快更新迭代速度,那么就把時間好好投資在測試系統上,要不然還不如跑一個睡眠程序讓你自己好好休息一下。
這就是關于機器學習的一切?
差不多啦,機器學習的核心部分就是安裝各種程序包,然后捋順你雜亂無章、毛發叢生的數據怪獸,便于挑剔的算法在你的數據集上運行。
接著就是永無止境的調整代碼設置(不要讓“超參數調優”這個聽起來高大上的名字嚇到了你)直到你歡呼:好啦!一個模型完成啦! 但是一旦你的模型在新的數據集上表現不好,你就不得不重新回到畫板前,一遍又一遍的調試,直到撥云見日,你的方案終于可以拿得出手了。這就是為什么要雇用失敗承受力強的人來做這件事

如果你一直期望的是有魔力的算法,那么早一點失望,就早一點清醒,當這些科幻迷信般的興奮死去時,我們才會新生出做真正酷的事情的信念。機器學習本身可能平淡無奇,但是你可以用它做的事情卻是驚天動地,它可以讓你寫出你完全想不到的程序代碼,讓你可以自動化那些無法言喻的過程,不要嫌棄機器學習的簡單,杠桿也很簡單,但是它可以撬動整個世界。
相關報道:
https://hackernoon.com/machine-learning-is-the-emperor-wearing-clothes-59933d12a3cc
【本文是51CTO專欄機構大數據文摘的原創文章,微信公眾號“大數據文摘( id: BigDataDigest)”】