機器學習的七原罪
打破機器學習實驗信譽的七個常見錯誤
機器學習是一種偉大的工具,正在改變著我們的世界。 在許多偉大的應用中,機器(尤其是深度學習)已被證明優于傳統方法。 從用于圖像分類的Alex-Net到用于圖像分割的U-Net,我們看到了計算機視覺和醫學圖像處理領域的巨大成功。 不過,我看到機器學習方法每天都在失敗。 在許多這樣的情況下,人們迷上了機器學習的七大罪過之一。
盡管它們都很嚴厲并得出錯誤的結論,但有些卻比另一些更糟,甚至機器學習專家也可能因自己的工作而感到興奮。 即使是其他專家,也很難發現其中的許多缺點,因為您需要詳細研究代碼和實驗設置才能弄清楚它們。 特別是,如果您的結果看起來好得令人難以置信,那么您可能希望將此博客文章用作清單,以避免對您的工作有錯誤的結論。 僅當您完全確定自己沒有遭受任何這些謬論時,才應該繼續向同事或公眾報告結果。
罪過1:數據和模型濫用
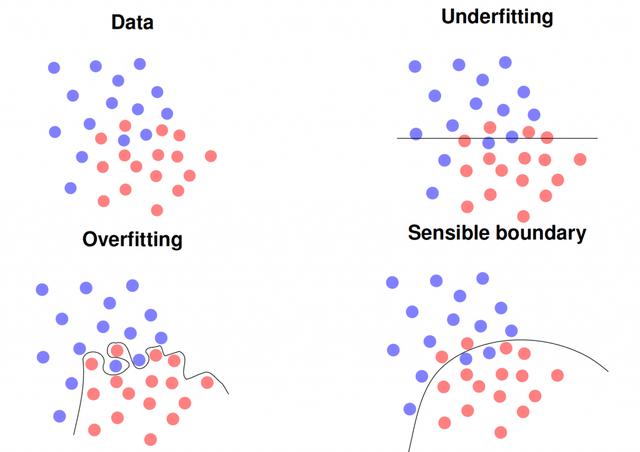
初學者在深度學習中常常犯下這種罪過。在最常見的情況下,實驗設計存在缺陷,例如訓練數據用作測試數據。使用簡單的分類器(例如最近的鄰居),這立即導致大多數問題的識別率達到100%。在更復雜,更深入的模型中,精度可能不是100%,而是98–99%。因此,如果您在第一張照片中獲得了如此高的識別率,則應始終仔細檢查實驗設置。但是,如果您使用新數據,您的模型將完全崩潰,甚至可能產生比隨機猜測更糟糕的結果,即準確度低于1 / K,其中K是類別數,例如兩類問題的比例不到50%。在同一行中,您還可以通過增加參數的數量來輕松地過度擬合模型,從而完全記住訓練數據集。另一個變體是使用過小的訓練集,它不能代表您的應用程序。所有這些模型都可能會破壞新數據,即在實際應用場景中使用時。
罪過2:不公平的比較
甚至機器學習方面的專家也可能陷入這種罪惡。如果您想證明自己的新方法比最新技術更好,那么通常會采用該方法。特別是研究論文經常屈服于這一觀點,以使評論者相信其方法的優越性。在最簡單的情況下,您可以從某個公共存儲庫下載模型,然后使用該模型進行微調或進行適當的超參數搜索,而無需針對已針對當前問題開發的模型,并調整所有參數以在測試中獲得最佳性能數據。文學中有許多這種罪惡的例子。 Isensee等人揭露了最近的例子。在他們的非新網論文中,他們證明了原始的U-net幾乎勝過所有自2015年以來針對十個不同問題提出的對該方法的改進。因此,您應該始終對最新模型執行相同數量的參數調整。
罪過3:微不足道的進步
在完成所有實驗之后,您最終找到了一個模型,該模型產生的結果要比最新模型更好。但是,即使在這一點上,您還沒有完成。機器學習中的所有內容都是不精確的。此外,由于學習過程的概率性,您的實驗會受到許多隨機因素的影響。為了考慮這種隨機性,您需要執行統計測試。這通常是通過使用不同的隨機種子多次運行實驗來執行的。這樣,您可以報告所有實驗的平均效果和標準偏差。使用像t檢驗這樣的顯著性檢驗,您現在可以確定觀察到的改善僅與機會相關的概率。為了使您的結果有意義,此概率應至少低于5%或1%。為此,您不必是專家統計學家。甚至還有在線工具可以計算它們,例如用于識別率比較或相關性比較。如果您進行重復實驗,請確保您還應用Bonferroni校正,即,將所需的顯著性水平除以相同數據上的實驗重復次數。有關統計測試的更多詳細信息,您應該查看我們的深度學習講座的視頻。
罪四:混雜因素和不良數據
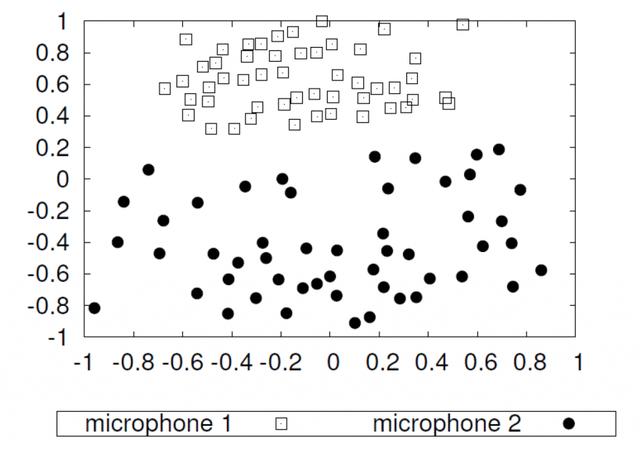
數據質量是機器學習的最大陷阱之一。它可能會導致嚴重的偏見,甚至導致種族主義的AI。但是,問題不在于訓練算法,而在于數據本身。例如,我們展示了使用兩個不同的麥克風對51個揚聲器進行降維錄音。因為我們錄制了相同的揚聲器,所以在進行適當的特征提取后,實際上應該將它們投影到相同的位置。但是,我們可以觀察到,相同的記錄形成兩個獨立的簇。實際上,在記錄場景的攝像機上,一個麥克風直接位于揚聲器的嘴部,而另一個麥克風位于大約2.5米遠的地方。通過使用來自兩個不同供應商的兩個麥克風,或者在醫學成像的情況下,通過使用兩個不同的掃描儀,已經可以產生類似的效果。如果您現在在掃描儀A上記錄了所有病理患者,在掃描儀B上記錄了所有對照對象,則您的機器學習方法將可能學會區分掃描儀,而不是實際的病理。您將對實驗結果感到非常滿意,并獲得接近完美的識別率。但是,您的模型在實踐中將完全失敗。因此,請避免混淆因素和不良數據!
罪過5:標簽不當
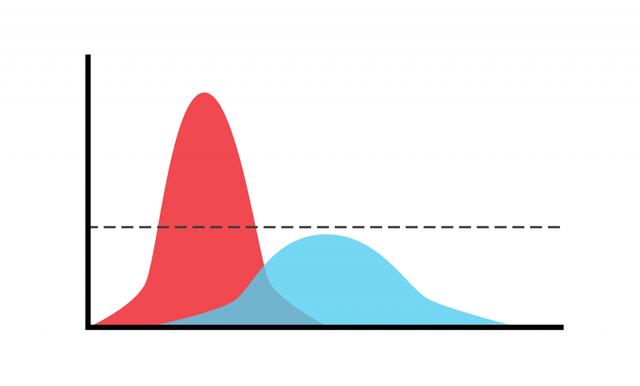
Protagoras已經知道:"在所有方面,衡量標準是人。"這也適用于許多分類問題的標簽或基本事實。我們訓練機器學習模型以反映人造類別。在許多問題中,我們認為在定義它們的那一刻,這些類是清晰的。一旦我們查看了數據,就會發現它通常也包含模棱兩可的情況,例如在ImageNet Challenge中顯示兩個對象而不是一個的圖像。如果我們去處理諸如情感識別之類的復雜現象,那就更加困難了。在這里,我們意識到在許多現實生活中的觀察中,即使人類也無法清晰地評估情緒。為了獲得正確的標簽,因此我們需要詢問多個評估者并獲得標簽分布。我們在上圖中對此進行了描述:紅色曲線顯示了清晰表殼的尖峰分布,即所謂的原型。藍色曲線表示模糊情況的廣泛分布。在這里,不僅機器,而且人類評級者都可能最終陷入矛盾的解釋中。如果您僅使用一個評估者來創建您的基本事實,您甚至不會意識到這個問題,因此通常會引發有關標簽噪聲及其有效處理方法的討論。如果您可以使用真實的標簽分布(當然這是很昂貴的),您甚至可以證明您可以通過消除模棱兩可的情況來顯著提高系統性能,例如我們在行為情感的情感識別中所看到的與現實生活中的情感。但是,在您的實際應用程序中可能并非如此,因為您從未見過模棱兩可的情況。因此,與單個評估者相比,您應該更喜歡多個評估者。
罪過6:交叉驗證混沌
這與罪#1幾乎是相同的罪過,但是它是變相的,我已經看到這甚至發生在幾乎提交的博士學位中。 論文。 因此,即使是專家也可能會喜歡上它。 典型的設置是第一步需要選擇模型,體系結構或特征。 因為只有幾個數據樣本,所以您決定使用交叉驗證來評估每個步驟。 因此,您將數據分為N折,選擇具有N-1折的特征/模型,并在第N折上求值。 重復此N次后,您可以計算平均性能并選擇性能最佳的功能。 現在,您知道最佳功能是什么,接下來繼續使用交叉驗證為您的機器學習模型選擇最佳參數。
這似乎是正確的,對吧? 沒有! 這是有缺陷的,因為您已經在第一步中看到了所有測試數據并平均了所有觀察值。 這樣,所有數據中的信息都會傳遞到下一步,您甚至可以從完全隨機的數據中獲得出色的結果。 為了避免這種情況,您需要遵循一個嵌套過程,該過程將第一步嵌套在第二個交叉驗證循環中。 當然,這非常昂貴,并且會產生大量實驗運行。 請注意,僅由于對相同數據進行大量實驗,在這種情況下,僅由于偶然原因,您也可能會產生良好的結果。 因此,統計測試和Bonferroni校正同樣是強制性的(參見罪3號)。 我通常會盡量避免進行大型的交叉驗證實驗,并嘗試獲取更多數據,以便您可以進行訓練/驗證/測試拆分。
罪過7:對結果的過度解釋
除了所有先前的過失之外,我認為在當前的炒作階段,我們在機器學習中經常犯的最大過錯是,我們過度解釋和夸大了自己的結果。 當然,每個人都對通過機器學習創建的成功解決方案感到滿意,并且您有權為此感到自豪。 但是,您應該避免將結果推斷在看不見的數據或狀態上,以一般地說已經解決了問題,因為您已經用相同的方法解決了兩個不同的問題。
同樣,由于我們在罪過#5中所做的觀察,關于超人類表現的主張引起了懷疑。 您將如何勝過標簽的來源? 當然,您可以在疲勞和專心方面擊敗一個人,但在人工班上總體上勝過人類? 您要小心此聲明。
每個主張都應基于事實。 您可以在討論中清楚地表明推測的基礎上假設該方法的普遍適用性,但要真正聲明這一點,您必須提供實驗或理論證據。 現在,很難讓您的方法具有應有的可見性,并提出重大主張當然會有助于推廣您的方法。 盡管如此,我還是建議您堅持實地并堅持證據。 否則,我們可能很快就會遇到下一個AI Winter,以及我們在前幾年已經普遍懷疑的人工智能。 讓我們在當前周期中避免這種情況,并堅持我們真正有能力實現的目標。
當然,你們大多數人已經知道了這些陷阱。 但是,您可能希望不時查看一下機器學習的七種罪過,只是為了確保您仍然在地上并且沒有為他們所迷:
罪過1:數據和模型濫用-分開訓練和測試,檢查是否過度擬合!罪過2:不公平的比較-還調整了基線模型!罪過3:微不足道的改進-做顯著性測試!罪過4:混雜因素和 錯誤的數據-檢查您的數據和采集!罪惡#5:標簽不當-使用多個評分者!罪惡#6:交叉驗證混亂-避免過多的十字架驗證!罪惡#7:結果的過度解釋-堅持證據!