超參數搜索不夠高效?這幾大策略了解一下
整天 babysitting 深度學習模型是不是很心累?這篇文章或許能幫到你。本文討論了高效搜索深度學習模型***超參數集的動機和策略。作者在 FloydHub 上演示了如何完成這項工作以及研究的導向。讀完這篇文章后,你的數據科學工具庫將添加一些強大的新工具,幫助你為自己的深度學習模型自動找到***配置。
與機器學習模型不同,深度學習模型實際上充滿了超參數。
當然,并非所有變量對模型的學習過程都一樣重要,但是,鑒于這種額外的復雜性,在這樣一個高維空間中找到這些變量的***配置顯然是一個不小的挑戰。
幸運的是,我們有不同的策略和工具來解決搜索問題。開始深入!
一、我們的目的
1. 怎么做?
我們希望找到***的超參數配置,幫助我們在驗證/測試集的關鍵度量上得到***分數。
2. 為何?
在計算力、金錢和時間資源有限的情況下,每個科學家和研究員都希望獲得***模型。但是我們缺少有效的超參數搜索來實現這一目標。
3. 何時?
- 研究員和深度學習愛好者在***的開發階段嘗試其中一種搜索策略很常見。這有助于從經過幾個小時的訓練獲得的***模型中獲得可能的提升。
- 超參數搜索作為半/全自動深度學習網絡中的階段或組件也很常見。顯然,這在公司的數據科學團隊中更為常見。
等等,究竟何謂超參數?
我們從最簡單的定義開始,
| 超參數是你在構建機器/深度學習模型時可以調整的「旋鈕」。 |

將超參數比作「旋鈕」或「撥號盤」
或者:
| 超參數是在開始訓練之前手動設置的具有預定值的訓練變量。 |
超參數是在開始訓練之前手動設置的具有預定值的訓練變量。
我們可能會同意學習率和 Dropout 率是超參數,但模型設計變量呢?模型設計變量包括嵌入,層數,激活函數等。我們應該將這些變量視為超參數嗎?
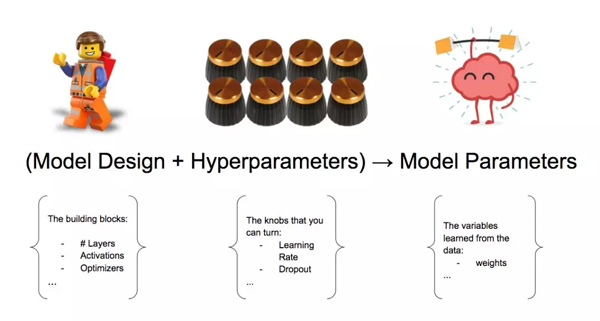
模型設計變量+超參數→模型參數
簡單起見,我們也可以將模型設計組件視為超參數集的一部分。
***,從訓練過程中獲得的參數(即從數據中學習的變量)算超參數嗎?這些權重稱為模型參數。我們不將它們算作超參數。
好的,讓我們看一個真實的例子。請看下面的圖片,僅以此圖說明深度學習模型中變量的不同分類。
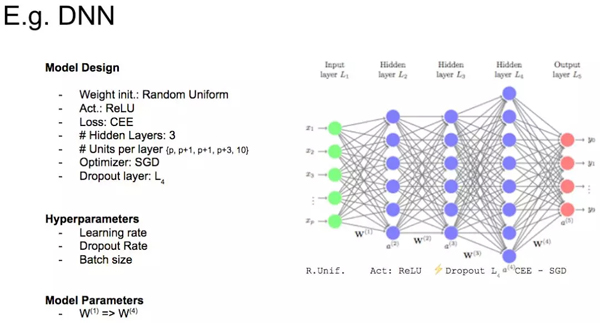
變量類別示例圖
4. 下一個問題:搜索代價高昂
我們已經知道,我們的目標是搜索超參數的***配置,但超參數搜索本質上是一個受計算能力、金錢和時間約束的迭代過程。

超參數搜索周期
一切都以猜測一個不錯的配置開始(步驟 1),然后我們需要等到訓練完畢(步驟 2)以獲得對相關度量標準的實際評估(步驟 3)。我們將跟蹤搜索過程的進度(步驟 4),然后根據我們的搜索策略選擇一個新的猜測參數(步驟 1)。
我們一直這樣做,直到達到終止條件(例如用完時間或金錢)。
我們有四種主要的策略可用于搜索***配置。
- 照看(babysitting,又叫試錯)
- 網格搜索
- 隨機搜索
- 貝葉斯優化
二、照看
照看法被稱為試錯法或在學術領域稱為研究生下降法。這種方法 100% 手動,是研究員、學生和業余愛好者最廣泛采用的方法。
該端到端的工作流程非常簡單:學生設計一個新實驗,遵循學習過程的所有步驟(從數據收集到特征圖可視化),然后她按順序迭代超參數,直到她耗盡時間(通常是到截止日期)或動機。
")
照看(babysitting)
如果你已經注冊了 deeplearning.ai 課程,那么你一定熟悉這種方法 - 這是由 Andrew Ng 教授提出的熊貓工作流程。
這種方法非常有教育意義,但它不能在時間寶貴的數據科學家的團隊或公司內部施展。
因此,我們遇到這個問題:有更好的方式來增值我的時間嗎?
肯定有!我們可以定義一個自動化的超參數搜索程序來節約你的時間。
三、網格搜索
取自命令式指令「Just try everything!」的網格搜索——一種簡單嘗試每種可能配置的樸素方法。
工作流如下:
- 定義一個 n 維的網格,其中每格都有一個超參數映射。例如 n = (learning_rate, dropout_rate, batch_size)
- 對于每個維度,定義可能的取值范圍:例如 batch_size = [4,8,16,32,64,128,256 ]
- 搜索所有可能的配置并等待結果去建立***配置:例如 C1 = (0.1, 0.3, 4) -> acc = 92%, C2 = (0.1, 0.35, 4) -> acc = 92.3% 等...
下圖展示了包含 Dropout 和學習率的二維簡單網格搜索。

兩變量并發執行的網格搜索
這種平行策略令人尷尬,因為它忽略了計算歷史(我們很快就會對此進行擴展)。但它的本意是,你擁有的計算資源越多,你可以同時嘗試的猜測就越多!
這種方法的真正痛點稱為 curse of dimensionality(維數災難)。這意味著我們添加的維數越多,搜索在時間復雜度上會增加得越多(通常是指數級增長),最終使這個策略變得不可行!
當超參數維度小于或等于 4 時,通常使用這種方法。但實際上,即使它保證在***找到***配置,它仍然不是***方案。相反,***使用隨機搜索——我們將在下面討論。
現在試試網格搜索!
單擊以下鏈接可在 FloydHub 上打開 Workspace:https://www.floydhub.com/signup?source=run。你可以使用工作區在完全配置的云服務器上運行以下代碼(使用 Scikit-learn 和 Keras 進行網格搜索)。
- # Load the dataset
- x, y = load_dataset()
- # Create model for KerasClassifier
- def create_model(hparams1=dvalue,
- hparams2=dvalue,
- ...
- hparamsn=dvalue):
- # Model definition
- ...
- model = KerasClassifier(build_fn=create_model)
- # Define the range
- hparams1 = [2, 4, ...]
- hparams2 = ['elu', 'relu', ...]
- ...
- hparamsn = [1, 2, 3, 4, ...]
- # Prepare the Grid
- param_grid = dict(hparams1hparams1=hparams1,
- hparams2hparams2=hparams2,
- ...
- hparamsnhparamsn=hparamsn)
- # GridSearch in action
- grid = GridSearchCV(estimator=model,
- param_gridparam_grid=param_grid,
- n_jobs=,
- cv=,
- verbose=)
- gridgrid_result = grid.fit(x, y)
- # Show the results
- print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
- means = grid_result.cv_results_['mean_test_score']
- stds = grid_result.cv_results_['std_test_score']
- params = grid_result.cv_results_['params']
- for mean, stdev, param in zip(means, stds, params):
- print("%f (%f) with: %r" % (mean, stdev, param))
四、隨機搜索
幾年前,Bergstra 和 Bengio 發表了一篇驚人的論文 (http://www.jmlr.org/papers/volume13/bergstra12a/bergstra12a.pdf),證明了網格搜索的低效率。
網格搜索和隨機搜索之間唯一真正的區別在于策略周期的第 1 步 - 隨機搜索從配置空間中隨機選取點。
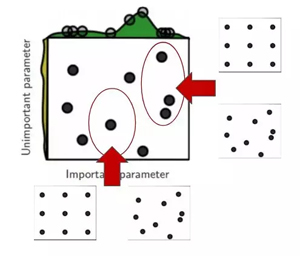
讓我們使用下面的圖片(論文中提供)來展示研究員的證明。

網格搜索 vs 隨機搜索
圖像通過在兩個超參數空間上搜索***配置來比較兩種方法。它還假設一個參數比另一個參數更重要。這是一個安全的假設,因為開頭提到的深度學習模型確實充滿了超參數,并且研究員/科學家/學生一般都知道哪些超參數對訓練影響***。
在網格搜索中,很容易注意到,即使我們已經訓練了 9 個模型,但我們每個變量只使用了 3 個值!然而,使用隨機布局,我們不太可能多次選擇相同的變量。結果是,通過第二種方法,我們將為每個變量使用 9 個不同的值訓練 9 個模型。
從每個圖像布局頂部的曲線圖可以看出,我們使用隨機搜索可以更廣泛地探索超參數空間(特別是對于更重要的變量)。這將有助于我們在更少的迭代中找到***配置。
總結:如果搜索空間包含 3 到 4 個以上的維度,請不要使用網格搜索。相反,使用隨機搜索,它為每個搜索任務提供了非常好的基準。

網格搜索和隨機搜索的優缺點
現在試試隨機搜索!
單擊以下鏈接可在 FloydHub 上打開 Workspace:https://www.floydhub.com/signup?source=run。你可以使用工作區在完全配置的云服務器上運行以下代碼(使用 Scikit-learn 和 Keras 進行隨機搜索)。
- # Load the dataset
- X, Y = load_dataset()
- # Create model for KerasClassifier
- def create_model(hparams1=dvalue,
- hparams2=dvalue,
- ...
- hparamsn=dvalue):
- # Model definition
- ...
- model = KerasClassifier(build_fn=create_model)
- # Specify parameters and distributions to sample from
- hparams1 = randint(1, 100)
- hparams2 = ['elu', 'relu', ...]
- ...
- hparamsn = uniform(0, 1)
- # Prepare the Dict for the Search
- param_dist = dict(hparams1hparams1=hparams1,
- hparams2hparams2=hparams2,
- ...
- hparamsnhparamsn=hparamsn)
- # Search in action!
- n_iter_search = 16 # Number of parameter settings that are sampled.
- random_search = RandomizedSearchCV(estimator=model,
- param_distparam_distributions=param_dist,
- n_iter=n_iter_search,
- n_jobs=,
- cv=,
- verbose=)
- random_search.fit(X, Y)
- # Show the results
- print("Best: %f using %s" % (random_search.best_score_, random_search.best_params_))
- means = random_search.cv_results_['mean_test_score']
- stds = random_search.cv_results_['std_test_score']
- params = random_search.cv_results_['params']
- for mean, stdev, param in zip(means, stds, params):
- print("%f (%f) with: %r" % (mean, stdev, param))
1. 后退一步,前進兩步
另外,當你需要為每個維度設置空間時,每個變量使用正確的比例非常重要。
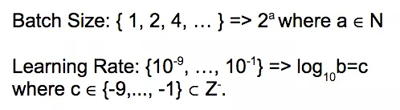
常用的批大小和學習率的比例空間
例如,通常使用 2 的冪作為批大小的值,并在對數尺度上對學習率進行采樣。
放大!
從上面的布局之一開始進行一定數量的迭代也很常見,然后通過在每個變量范圍內更密集地采樣并放大到有希望的子空間,然后甚至用相同或不同的搜索策略開始新的搜索。
2. 還有一個問題:獨立猜測!
不幸的是,網格和隨機搜索都有共同的缺點:每一次新猜測都獨立于之前的訓練!
這聽起來可能有些奇怪、令人意外,盡管需要大量時間,但令照看法起效的是科學家有效推動搜索和實驗的能力,他們通過使用過去的實驗結果作為資源來改進下一次訓練。
等一下,這些好像在哪兒聽過...... 嘗試將超參數搜索問題建模為機器學習任務會怎么樣?!
請允許我介紹下貝葉斯優化。
五、貝葉斯優化
此搜索策略構建一個代理模型,該模型試圖從超參數配置中預測我們關注的指標。
在每次新的迭代中,代理人將越來越自信哪些新的猜測可以帶來改進。就像其他搜索策略一樣,它也有相同的終止條件。

貝葉斯優化工作流
如果聽起來有點困惑,請不要擔心——是時候參考另一個圖例了。
1. 高斯過程在起作用
我們可以將高斯過程定義為代理,它將學習從超參數配置到相關度量的映射。它不僅會將預測轉化為一個值,還會為我們提供不確定性的范圍(均值和方差)。
我們來深入研究這個偉大教程
(https://www.iro.umontreal.ca/~bengioy/cifar/NCAP2014-summerschool/slides/Ryan_adams_140814_bayesopt_ncap.pdf) 提供的示例。
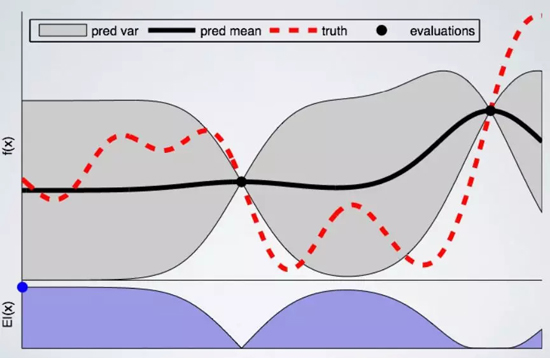
有 2 個點的高斯過程的優化過程
在上圖中,我們遵循單變量(在水平軸上)的高斯過程優化的***步。在我們想象的例子中,這可以代表學習率或 dropout 率。
在垂直軸上,我們繪制了相關度量作為單個超參數的函數。因為我們正在尋找盡可能低的值,所以可以將其視為損失函數。
黑點代表訓練到當前階段的模型。紅線是 ground truth,換句話說,就是我們正在努力學習的函數。黑線表示我們對 ground truth 函數的實際假設的平均值,灰色區域表示空間中的相關不確定性或方差。
我們可以注意到,點周圍的不確定性有所減少,因為我們對這些點的結果非常有信心(因為我們已經在這里訓練了模型)。同時,在我們擁有較少信息的領域,不確定性會增加。
現在我們已經定義了起點,準備好選擇下一個有希望的變量來訓練一個模型。為此,我們需要定義一個采集函數,它將告訴我們在哪里采樣下一個參數。
在此示例中,我們使用了 Expected Improvement:這個函數旨在在我們使用不確定性區域中的建議配置時找到盡可能低的值。上面的 Expected Improvement 圖表中的藍點即為下一次訓練選擇的點。

3 點高斯過程
我們訓練的模型越多,代理人對下一個有希望采樣的點就越有信心。以下是模型經過 8 次訓練后的圖表:

8 點高斯過程
高斯過程屬于基于序列模型的優化(SMBO)類別的算法。正如我們剛看到的,這些算法為開始搜索***超參數配置提供了非常好的基準。但是,跟所有工具一樣,它們也有缺點:
- 根據定義,該過程是有順序的
- 它只能處理數值參數
- 即使訓練表現不佳,它也不提供任何停止訓練的機制
請注意,我們只是簡單地談到了這個話題,如果你對細節部分以及如何擴展 SMBO 感興趣,那么請看一下這篇論文
(https://www.cs.ubc.ca/~hutter/papers/10-TR-SMAC.pdf)。
2. 現在試試貝葉斯優化!
單擊以下鏈接可在 FloydHub 上打開 Workspace:https://www.floydhub.com/signup?source=run。你可以使用工作區在完全配置的云服務器上運行以下代碼(使用 Hyperas 進行貝葉斯優化(SMBO-TPE))。
- def data():
- """
- Data providing function:
- This function is separated from model() so that hyperopt
- won't reload data for each evaluation run.
- """
- # Load / Cleaning / Preprocessing
- ...
- return x_train, y_train, x_test, y_test
- def model(x_train, y_train, x_test, y_test):
- """
- Model providing function:
- Create Keras model with double curly brackets dropped-in as needed.
- Return value has to be a valid python dictionary with two customary keys:
- - loss: Specify a numeric evaluation metric to be minimized
- - status: Just use STATUS_OK and see hyperopt documentation if not feasible
- The last one is optional, though recommended, namely:
- - model: specify the model just created so that we can later use it again.
- """
- # Model definition / hyperparameters space definition / fit / eval
- return {'loss': <metrics_to_minimize>, 'status': STATUS_OK, 'model': model}
- # SMBO - TPE in action
- best_run, best_model = optim.minimize(modelmodel=model,
- datadata=data,
- algo=tpe.suggest,
- max_evals=,
- trials=Trials())
- # Show the results
- x_train, y_train, x_test, y_test = data()
- print("Evalutation of best performing model:")
- print(best_model.evaluate(x_test, y_test))
- print("Best performing model chosen hyper-parameters:")
- print(best_run)
六、搜索策略對比
現在讓我們來總結一下到目前為止所涵蓋的策略,以了解每個策略的優缺點。
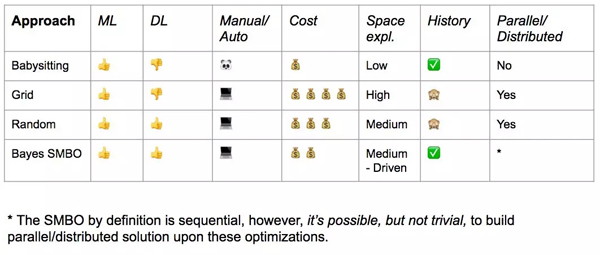
總結
如果你或你的團隊有足夠的資源,貝葉斯 SMBO 可能是***,但是你也應該考慮建立一個隨機搜索的基準。
另一方面,如果你還在訓練或處于設計階段,即使在空間探索方面不切實際,照看法也是可以一試的。
正如我在上一節中提到的,如果一個訓練表現不佳,我們必須等到計算結束,因為這些策略都不能提供節省資源的機制。
因此,我們得出了***一個問題:我們能優化訓練時間嗎?
我們來試試看。
七、提前終止的力量
提前終止不僅是一項著名的正則化技術,而且在訓練錯誤時,它還是一種能夠防止資源浪費的機制。
下面是最常用的終止訓練標準的圖表:
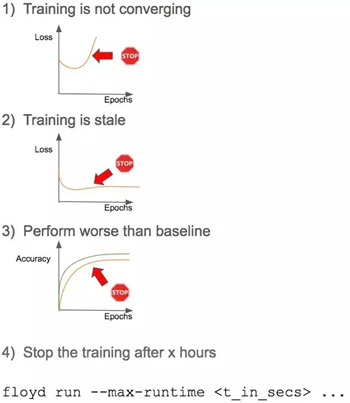
終止標準
前三個標準顯而易見,所以我們把注意力集中在***一個標準上。
通常情況下,研究人員會根據實驗類別來限定訓練時間。這樣可以優化團隊內部的資源。通過這種方式,我們能夠將更多資源分配給最有希望的實驗。
floyd-cli(我們的用戶用來與 FloydHub 通信的軟件,已經在 Github 上開源)為此提供了一個標準:我們的高級用戶正在大規模使用它來調節他們的實驗。
這些標準可以在照看學習過程時手動應用,或者你可以通過常見框架中提供的鉤子/回調在實驗中集成這些規則來做得更好:
- Keras 提供了一個很好的提前終止功能,甚至還有一套回調組件。由于 Keras 最近已經整合到 Tensorflow 中,你也可以使用 Tensorflow 代碼中的回調組件。
- Tensorflow 提供了訓練鉤子,這些鉤子可能不像 Keras 回調那樣直觀,但是它們能讓你對執行狀態有更多的控制。
- Pytorch 還沒有提供鉤子或回調組件,但是你可以在論壇上查看 TorchSample 倉庫。我不太清楚 Pytorch 1.0 的功能列表(該團隊可能會在 PyTorch 開發者大會上發布一些內容),這個功能可能會隨新版本一起發布。
- Fast.ai 庫也提供回調組件,即使它目前沒有提供任何形式的文檔(WIP),你也可以去找一個不錯的教程。幸運的是,他們有一個很棒的社區。
- Ignite(Pytorch 的高級庫)提供類似于 Keras 的回調,雖然還在開發階段,但它看起來確實是一個不錯的選擇。
名單就這么多了,我的討論只涉及最常用/***的框架。-(我希望不會損害其他框架作者的玻璃心。如果是這樣,你可以將你的意見轉發給我,我會很樂意更新列表!)
還沒有結束。
機器學習有一個子領域叫做「AutoML」(Automatic Machine Learning,自動機器學習),目的是實現模型選擇、特征提取和/或超參數優化的自動化。
這就引出了***一個問題(我保證是***一個!):我們能了解整個過程嗎?
你可以認為,AutoML 是一個解決了另一個機器學習任務的機器學習任務,類似于我們利用貝葉斯優化完成的任務,本質上是元機器學習。
1. 研究:AutoML 和 PBT
你很可能聽說過谷歌的 AutoML,這是他們對神經架構搜索的品牌重塑。請記住,在本文開頭,我們決定將模型設計組件合并到超參數變量中。那么,神經架構搜索是 AutoML 的子領域,旨在為給定任務找到***模型。關于這個主題的全面討論需要一系列文章。幸運的是,來自 fast.ai 的 Rachel Thomas 博士做了一項了不起的工作,我們很樂意提供鏈接:
http://www.fast.ai/2018/07/12/auto-ml-1/。
我想和大家分享另一個來自 DeepMind 的有趣的研究成果,他們使用進化策略算法的一種變體來執行超參數搜索,稱為基于群體的訓練(Population Based Training,PBT)。PBT 也是 DeepMind 的另一項研究(《Capture the Flag: the emergence of complex cooperative agents》)的基礎,新聞報道并不完全,我強烈建議你去看看。引自 DeepMind:
| 就像隨機搜索一樣,PBT 首先需要以隨機挑選超參數的方式訓練許多并行的神經網絡。但是這些網絡并不是獨立訓練的,而是使用其它網絡的訓練信息來修正這些超參數,并將計算資源分配到那些有希望的模型上。這種方法的靈感來自于遺傳算法:其中一個群體中的每個個體(被稱為 worker)可以利用除自身外其余個體的信息。例如,一個個體可能會從表現較好的個體那里復制模型參數,它還能通過隨機改變當前的值來探索新的超參數集。 |
當然,這一領域可能還有許多其他有趣的研究。在這里,我只是和大家分享了最近得到媒體關注的一些研究。
2. 在 FloydHub 上管理你的實驗
FloydHub ***的特點之一是能夠在訓練時比較使用不同的超參數集的不同模型。
下圖展示了 FloydHub 項目中的作業列表。你可以看到此用戶正在使用作業的消息字段(例如,floyd run --message "SGD, lr=1e-3, l1_drop=0.3" ...)以突出顯示在每個作業上使用的超參數。
此外,你還可以查看每項作業的訓練指標。這些提供了快速瀏覽,幫助你了解哪些作業表現***,以及使用的機器類型和總訓練時間。
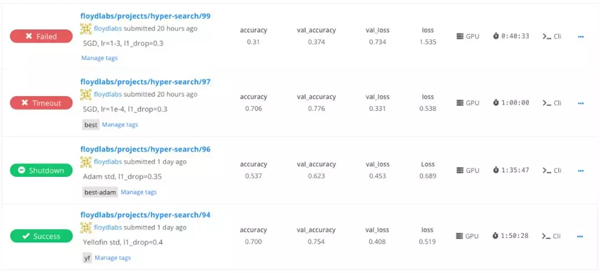
項目主頁
FloydHub 儀表板為你提供了一種簡單的方法來比較你在超參數搜索中做的所有訓練——并且實時更新。
我們建議你為每個必須解決的任務/問題創建一個不同的 FloydHub 項目。通過這種方式,你可以更輕松地組織工作并與團隊協作。
3. 訓練指標
如上所述,你可以輕松地在 FloydHub 上為你的作業發布訓練指標。當你在 FloydHub 儀表板上查看作業時,你將找到你定義的每個指標的實時圖表。
此功能無意替代 Tensorboard(我們也提供此功能),而是旨在突出顯示你已選擇的超參數配置的訓練走勢。
例如,如果你正在監督訓練過程,那么訓練指標肯定會幫助你確定和應用停止標準。
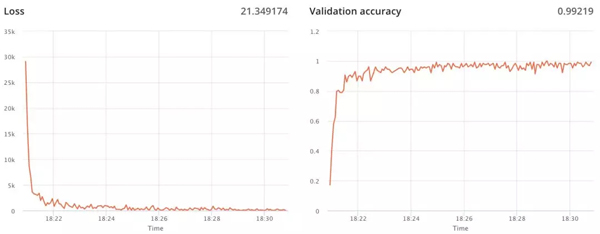
訓練指標
原文鏈接:
https://blog.floydhub.com/guide-to-hyperparameters-search-for-deep-learning-models/
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】