150倍加速機(jī)械盤(pán),UCloud云主機(jī)IO加速技術(shù)揭秘
現(xiàn)如今CPU的計(jì)算能力和磁盤(pán)的訪問(wèn)延遲之間的差距逐漸擴(kuò)大,使得用戶云主機(jī)的磁盤(pán)IO經(jīng)常成為嚴(yán)重的性能瓶頸,云計(jì)算環(huán)境下更加明顯。針對(duì)機(jī)械盤(pán)IO性能低下的問(wèn)題,我們通過(guò)自研的云主機(jī)IO加速方案,使4K隨機(jī)寫(xiě)的***性能由原來(lái)的300 IOPS提升至4.5W IOPS,提高了150倍,即用機(jī)械盤(pán)的成本獲得了SSD的性能。13年上線至今,該方案已歷經(jīng)五年的運(yùn)營(yíng)實(shí)踐,并成功應(yīng)用于全網(wǎng)93%的標(biāo)準(zhǔn)型云主機(jī),覆蓋12.7萬(wàn)臺(tái)實(shí)例,總?cè)萘窟_(dá)26PB。
一 為什么需要IO加速
傳統(tǒng)的機(jī)械磁盤(pán)在尋址時(shí)需要移動(dòng)磁頭到目標(biāo)位置,移動(dòng)磁頭的操作是機(jī)械磁盤(pán)性能低下的主要原因,雖然各種系統(tǒng)軟件或者IO調(diào)度器都致力于減少磁頭的移動(dòng)來(lái)提高性能,但大部分場(chǎng)景下只是改善效果。一般,一塊SATA機(jī)械磁盤(pán)只有300左右的4K隨機(jī)IOPS,對(duì)于大多數(shù)云主機(jī)來(lái)說(shuō),300的隨機(jī)IOPS哪怕獨(dú)享也是不夠的,更何況在云計(jì)算的場(chǎng)景中,一臺(tái)物理宿主機(jī)上會(huì)有多臺(tái)云主機(jī)。因此,必須要有其他的方法來(lái)大幅提升IO性能。
早期SSD價(jià)格昂貴,采用SSD必然會(huì)帶來(lái)用戶使用成本的提升。于是,我們開(kāi)始思考能否從技術(shù)角度來(lái)解決這個(gè)問(wèn)題,通過(guò)對(duì)磁盤(pán)性能特性的分析,我們開(kāi)始研發(fā)***代IO加速方案。即使今天SSD越來(lái)越普及,機(jī)械盤(pán)憑借成本低廉以及存儲(chǔ)穩(wěn)定的特點(diǎn),仍然廣泛應(yīng)用,而IO加速技術(shù)能讓機(jī)械盤(pán)滿足絕大多數(shù)應(yīng)用場(chǎng)景的高IO性能需求。
二 IO加速原理及***代IO加速
我們知道機(jī)械磁盤(pán)的特性是隨機(jī)IO性能較差,但順序IO性能較好,如前文中提到的4K隨機(jī)IO只能有300 IOPS的性能,但其順序IO性能可以達(dá)到45000 IOPS。
IO加速的基本原理就是利用了機(jī)械磁盤(pán)的這種性能特性,首先系統(tǒng)有兩塊盤(pán):一塊是cache盤(pán),它是容量稍小的機(jī)械盤(pán),用來(lái)暫時(shí)保存寫(xiě)入的數(shù)據(jù);另一塊是目標(biāo)盤(pán),它是容量較大的機(jī)械盤(pán),存放最終的數(shù)據(jù)。
1. IO的讀寫(xiě)
寫(xiě)入時(shí)將上層的IO順序的寫(xiě)入到cache盤(pán)上,因?yàn)槭琼樞虻姆绞綄?xiě)入所以性能非常好,然后在cache盤(pán)空閑時(shí)由專(zhuān)門(mén)的線程將該盤(pán)的數(shù)據(jù)按照寫(xiě)入的先后順序回刷到目標(biāo)盤(pán),使得cache盤(pán)保持有一定的空閑空間來(lái)存儲(chǔ)新的寫(xiě)入數(shù)據(jù)。
為了做到上層業(yè)務(wù)無(wú)感知,我們選擇在宿主機(jī)內(nèi)核態(tài)的device mapper層(簡(jiǎn)稱(chēng)dm層)來(lái)實(shí)現(xiàn)該功能,dm層結(jié)構(gòu)清晰,模塊化較為方便,實(shí)現(xiàn)后對(duì)上層體現(xiàn)為一個(gè)dm塊設(shè)備,上層不用關(guān)心這個(gè)塊設(shè)備是如何實(shí)現(xiàn)的,只需要知道這是一個(gè)塊設(shè)備可以直接做文件系統(tǒng)使用。
械盤(pán),UCloud云主機(jī)IO加速技術(shù)揭秘")
按照上述方式,當(dāng)新的IO寫(xiě)入時(shí),dm層模塊會(huì)將該IO先寫(xiě)入cache盤(pán),然后再回刷到目標(biāo)盤(pán),這里需要有索引來(lái)記錄寫(xiě)入的IO在cache盤(pán)上的位置和在目標(biāo)盤(pán)上的位置信息,后續(xù)的回刷線程就可以利用該索引來(lái)確定IO數(shù)據(jù)源位置和目標(biāo)位置。我們將索引的大小設(shè)計(jì)為512字節(jié),因?yàn)榇疟P(pán)的扇區(qū)是512字節(jié),所以每次的寫(xiě)入信息變成了4K數(shù)據(jù)+512字節(jié)索引的模式,為了性能考慮,索引的信息也會(huì)在內(nèi)存中保留一份。
讀取過(guò)程比較簡(jiǎn)單,通過(guò)內(nèi)存中的索引判斷需要讀取位置的數(shù)據(jù)是在cache盤(pán)中還是在目標(biāo)盤(pán)中,然后到對(duì)應(yīng)的位置讀取即可。
寫(xiě)入的數(shù)據(jù)一般為4K大小,這是由內(nèi)核dm層的特性決定的,當(dāng)寫(xiě)入IO大于4K時(shí),dm層默認(rèn)會(huì)將數(shù)據(jù)切分,比如寫(xiě)入IO是16K,那么就會(huì)切分成4個(gè)4K的IO;如果寫(xiě)入數(shù)據(jù)不是按照4K對(duì)齊的,比如只有1024字節(jié),那么就會(huì)先進(jìn)行特殊處理,首先檢查該IO所覆蓋的數(shù)據(jù)區(qū),如果所覆蓋的內(nèi)存區(qū)在cache盤(pán)中有數(shù)據(jù),那么需要將該數(shù)據(jù)先寫(xiě)入目標(biāo)盤(pán),再將該IO寫(xiě)入目標(biāo)盤(pán),這個(gè)處理過(guò)程相對(duì)比較復(fù)雜,但在文件系統(tǒng)場(chǎng)景中大部分IO都是4K對(duì)齊的,只有極少數(shù)IO是非對(duì)齊的,所以并不會(huì)對(duì)業(yè)務(wù)的性能造成太大影響。
2. 索引的快速恢復(fù)與備份
系統(tǒng)在運(yùn)行過(guò)程中無(wú)法避免意外掉電或者系統(tǒng)關(guān)閉等情況發(fā)生,一個(gè)健壯的系統(tǒng)必須能夠在遇到這些情況時(shí)依然能保證數(shù)據(jù)的可靠性。當(dāng)系統(tǒng)啟動(dòng)恢復(fù)時(shí),需要重建內(nèi)存中的索引數(shù)據(jù),這個(gè)數(shù)據(jù)在cache盤(pán)中已經(jīng)和IO數(shù)據(jù)一起寫(xiě)入了,但因?yàn)樗饕情g隔存放的,如果每次都從cache盤(pán)中讀取索引,那么,數(shù)據(jù)的恢復(fù)速度會(huì)非常慢。
為此,我們?cè)O(shè)計(jì)了內(nèi)存索引的定期dump機(jī)制,每隔大約1小時(shí)就將內(nèi)存中的索引數(shù)據(jù)dump到系統(tǒng)盤(pán)上,啟動(dòng)時(shí)首先讀取該dump索引,然后再?gòu)腸ache盤(pán)中讀取dump索引之后的***1小時(shí)內(nèi)的索引,這樣,就大大提升了系統(tǒng)恢復(fù)的啟動(dòng)時(shí)間。
依據(jù)上述原理,UCloud自研了***代IO加速方案。采用該方案后,系統(tǒng)在加速隨機(jī)寫(xiě)入方面取得了顯著效果,且已在線上穩(wěn)定運(yùn)行。
三 ***代IO加速方案存在的問(wèn)題
但隨著系統(tǒng)的運(yùn)行,我們也發(fā)現(xiàn)了一些問(wèn)題。
械盤(pán),UCloud云主機(jī)IO加速技術(shù)揭秘")
1)索引內(nèi)存占用較大
磁盤(pán)索引因?yàn)樯葏^(qū)的原因最小為512字節(jié),但內(nèi)存中的索引其實(shí)沒(méi)有必要使用這么多,過(guò)大的索引會(huì)過(guò)度消耗內(nèi)存。
2)負(fù)載高時(shí)cache盤(pán)中堆積的IO數(shù)據(jù)較多
IO加速的原理主要是加速隨機(jī)IO,對(duì)順序IO因?yàn)闄C(jī)械盤(pán)本身性能較好不需要加速,但該版本中沒(méi)有區(qū)分順序IO和隨機(jī)IO,所有IO都會(huì)統(tǒng)一寫(xiě)入cache盤(pán)中,使得cache堆積IO過(guò)多。
3)熱升級(jí)不友好
初始設(shè)計(jì)時(shí)對(duì)在線升級(jí)的場(chǎng)景考慮不足,所以***代IO加速方案的熱升級(jí)并不友好。
4)無(wú)法兼容新的512e機(jī)械磁盤(pán)
傳統(tǒng)機(jī)械磁盤(pán)物理扇區(qū)和邏輯扇區(qū)都是512字節(jié),而新的512e磁盤(pán)物理扇區(qū)是4K了,雖然邏輯扇區(qū)還可以使用512字節(jié),但性能下降嚴(yán)重,所以***代IO加速方案的4K數(shù)據(jù)+512字節(jié)索引的寫(xiě)入方式需要進(jìn)行調(diào)整。
5)性能無(wú)法擴(kuò)展
系統(tǒng)性能取決于cache盤(pán)的負(fù)載,無(wú)法進(jìn)行擴(kuò)展。
四 第二代IO加速技術(shù)
上述問(wèn)題都是在***代IO加速技術(shù)線上運(yùn)營(yíng)的過(guò)程中發(fā)現(xiàn)的。并且在對(duì)新的機(jī)械磁盤(pán)的兼容性方面,因?yàn)閭鹘y(tǒng)的512字節(jié)物理扇區(qū)和邏輯扇區(qū)的512n類(lèi)型磁盤(pán)已經(jīng)逐漸不再生產(chǎn),如果不對(duì)系統(tǒng)做改進(jìn),系統(tǒng)可能會(huì)無(wú)法適應(yīng)未來(lái)需求。因此,我們?cè)?**代方案的基礎(chǔ)上,著手進(jìn)行了第二代IO加速技術(shù)的研發(fā)和優(yōu)化迭代。
1. 新的索引和索引備份機(jī)制
***代的IO加速技術(shù)因?yàn)楸P(pán)的原因無(wú)法沿用4K+512Byte的格式,為了解決這個(gè)問(wèn)題,我們把數(shù)據(jù)和索引分開(kāi),在系統(tǒng)盤(pán)上專(zhuān)門(mén)創(chuàng)建了一個(gè)索引文件,因?yàn)橄到y(tǒng)盤(pán)基本處于空閑狀態(tài),所以不用擔(dān)心系統(tǒng)盤(pán)負(fù)載高影響索引寫(xiě)入,同時(shí)我們還優(yōu)化了索引的大小由512B減少到了64B,而數(shù)據(jù)部分還是寫(xiě)入cache盤(pán),如下圖所示:
械盤(pán),UCloud云主機(jī)IO加速技術(shù)揭秘")
其中索引文件頭部和數(shù)據(jù)盤(pán)頭部保留兩個(gè)4K用于存放頭數(shù)據(jù),頭數(shù)據(jù)中包含了當(dāng)前cache盤(pán)數(shù)據(jù)的開(kāi)始和結(jié)束的偏移,其后是具體的索引數(shù)據(jù),索引與cache盤(pán)中的4K數(shù)據(jù)是一一對(duì)應(yīng)的關(guān)系,也就是每個(gè)4K的數(shù)據(jù)就會(huì)有一個(gè)索引。
因?yàn)樗饕旁诹讼到y(tǒng)盤(pán),所以也要考慮,如果系統(tǒng)盤(pán)發(fā)生了不可恢復(fù)的損壞時(shí),如何恢復(fù)索引的問(wèn)題。雖然系統(tǒng)盤(pán)發(fā)生損壞是非常小概率的事件,但一旦發(fā)生,索引文件將會(huì)完全丟失,這顯然是無(wú)法接受的。因此,我們?cè)O(shè)計(jì)了索引的備份機(jī)制,每當(dāng)寫(xiě)入8個(gè)索引,系統(tǒng)就會(huì)將這些索引合并成一個(gè)4K的索引備份塊寫(xiě)入cache盤(pán)中(具體見(jiàn)上圖中的紫色塊),不滿4K的部分就用0來(lái)填充,這樣當(dāng)系統(tǒng)盤(pán)真的發(fā)生意外也可以利用備份索引來(lái)恢復(fù)數(shù)據(jù)。
在寫(xiě)入時(shí)會(huì)同時(shí)寫(xiě)入索引和數(shù)據(jù),為了提高寫(xiě)入效率,我們優(yōu)化了索引的寫(xiě)入機(jī)制,引入了合并寫(xiě)入的方式:
械盤(pán),UCloud云主機(jī)IO加速技術(shù)揭秘")
當(dāng)寫(xiě)入時(shí)可以將需要寫(xiě)入的多個(gè)索引合并到一個(gè)4K的write buffer中,一次性寫(xiě)入該write buffer,這樣避免了每個(gè)索引都會(huì)產(chǎn)生一個(gè)寫(xiě)入的低效率行為,同時(shí)也保證了每次的寫(xiě)入是4K對(duì)齊的。
2. 順序IO識(shí)別能力
在運(yùn)營(yíng)***代IO加速技術(shù)的過(guò)程中,我們發(fā)現(xiàn)用戶在做數(shù)據(jù)備份、導(dǎo)入等操作時(shí),會(huì)產(chǎn)生大量的寫(xiě)入,這些寫(xiě)入基本都是順序的,其實(shí)不需要加速,但***代的IO加速技術(shù)并沒(méi)有做區(qū)分,所以這些IO都會(huì)被寫(xiě)入在cache盤(pán)中,導(dǎo)致cache盤(pán)堆積的IO過(guò)多。為此,我們添加了順序IO識(shí)別算法,通過(guò)算法識(shí)別出順序的IO,這些IO不需要通過(guò)加速器,會(huì)直接寫(xiě)入目標(biāo)盤(pán)。
一個(gè)IO剛開(kāi)始寫(xiě)入時(shí)是無(wú)法預(yù)測(cè)此IO是順序的還是隨機(jī)的,一般的處理方式是當(dāng)一個(gè)IO流寫(xiě)入的位置是連續(xù)的,并且持續(xù)到了一定的數(shù)量時(shí),才能認(rèn)為這個(gè)IO流是順序的,所以算法的關(guān)鍵在于如何判斷一個(gè)IO流是連續(xù)的,這里我們使用了觸發(fā)器的方式。
當(dāng)一個(gè)IO流開(kāi)始寫(xiě)入時(shí),我們會(huì)在這個(gè)IO流寫(xiě)入位置的下一個(gè)block設(shè)置一個(gè)觸發(fā)器,觸發(fā)器被觸發(fā)就意味著該block被寫(xiě)入了,那么就將觸發(fā)器往后移動(dòng)到再下一個(gè)block,當(dāng)觸發(fā)器被觸發(fā)了一定的次數(shù),我們就可以認(rèn)為這個(gè)IO流是順序的,當(dāng)然如果觸發(fā)器被觸發(fā)后一定時(shí)間沒(méi)有繼續(xù)被觸發(fā),那么我們就可以回收該觸發(fā)器。
3. 無(wú)感知熱升級(jí)
***代的IO加速技術(shù)設(shè)計(jì)上對(duì)熱升級(jí)支持并不友好,更新存量版本時(shí)只能通過(guò)熱遷移然后重啟的方式,整個(gè)流程較為繁瑣,所以在開(kāi)發(fā)第二代IO加速技術(shù)時(shí),我們?cè)O(shè)計(jì)了無(wú)感知熱升級(jí)的方案。
由于我們的模塊是位于內(nèi)核態(tài)的dm層,一旦初始化后就會(huì)生成一個(gè)虛擬的dm塊設(shè)備,該塊設(shè)備又被上層文件系統(tǒng)引用,所以這個(gè)模塊一旦初始化后就不能卸載了。為了解決這個(gè)問(wèn)題,我們?cè)O(shè)計(jì)了父子模塊的方式,父模塊在子模塊和dm層之間起到一個(gè)橋梁的作用,該父模塊只有非常簡(jiǎn)單的IO轉(zhuǎn)發(fā)功能,并不包含復(fù)雜的邏輯,因此可以確保父模塊不需要進(jìn)行升級(jí),而子模塊包含了復(fù)雜的業(yè)務(wù)邏輯,子模塊可以從父模塊中卸載來(lái)實(shí)現(xiàn)無(wú)感知熱升級(jí):
械盤(pán),UCloud云主機(jī)IO加速技術(shù)揭秘")
上圖中的binlogdev.ko就是父模塊,cachedev.ko為子模塊,當(dāng)需要熱升級(jí)時(shí)可以將cache盤(pán)設(shè)置為只讀模式,這樣cache盤(pán)只回刷數(shù)據(jù)不再寫(xiě)入,等cache盤(pán)回刷完成后,可以認(rèn)為后續(xù)的寫(xiě)入IO可直接寫(xiě)入目標(biāo)盤(pán)而不用擔(dān)心覆蓋cache盤(pán)中的數(shù)據(jù),這樣子模塊就可以順利拔出替換了。
這樣的熱升級(jí)機(jī)制不僅實(shí)現(xiàn)了熱升級(jí)的功能,還提供了故障時(shí)的規(guī)避機(jī)制,在IO加速技術(shù)的灰度過(guò)程中,我們就發(fā)現(xiàn)有個(gè)偶現(xiàn)的bug會(huì)導(dǎo)致宿主機(jī)重啟,我們***時(shí)間將所有cache盤(pán)設(shè)置為只讀,以避免故障的再次發(fā)生,并爭(zhēng)取到了debug的時(shí)間。
4. 兼容512e機(jī)械磁盤(pán)
新一代的機(jī)械磁盤(pán)以512e為主,該類(lèi)型的磁盤(pán)需要寫(xiě)入IO按照4K對(duì)齊的方式才能發(fā)揮***性能,所以原先的4K+512B的索引格式已經(jīng)無(wú)法使用,我們也考慮過(guò)把512B的索引擴(kuò)大到4K,但這樣會(huì)導(dǎo)致索引占用空間過(guò)多,且寫(xiě)入時(shí)也會(huì)額外占用磁盤(pán)的帶寬效率太低,所以最終通過(guò)將索引放到系統(tǒng)盤(pán)并結(jié)合上文提到的合并寫(xiě)入技術(shù)來(lái)解決該問(wèn)題。
5. 性能擴(kuò)展和提升
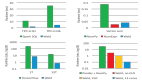
在***代的IO加速技術(shù)中只能使用1塊cache盤(pán),當(dāng)這塊cache盤(pán)負(fù)載較高時(shí)就會(huì)影響系統(tǒng)的性能,在第二代IO加速中,我們?cè)O(shè)計(jì)了支持多塊cache盤(pán),并按照系統(tǒng)負(fù)載按需插入的方式,使加速隨機(jī)IO的能力隨著盤(pán)數(shù)量的提升而提升。在本地cache盤(pán)以及網(wǎng)絡(luò)cache盤(pán)都采用SATA機(jī)械磁盤(pán)的條件下,測(cè)試發(fā)現(xiàn),隨著使用的cache盤(pán)數(shù)量的增多,隨機(jī)寫(xiě)的性能也得到了大幅度的提升。
- 在只使用一塊本地cache盤(pán)時(shí),隨機(jī)寫(xiě)性能可達(dá)4.7W IOPS:
械盤(pán),UCloud云主機(jī)IO加速技術(shù)揭秘")
- 在使用一塊本地cache盤(pán)加一塊網(wǎng)絡(luò)cache盤(pán)時(shí),隨機(jī)寫(xiě)性能可達(dá)9W IOPS:
械盤(pán),UCloud云主機(jī)IO加速技術(shù)揭秘")
- 在使用一塊本地cache盤(pán)加兩塊網(wǎng)絡(luò)cache盤(pán)時(shí),隨機(jī)寫(xiě)性能可達(dá)13.6W IOPS:
械盤(pán),UCloud云主機(jī)IO加速技術(shù)揭秘")
目前,我們已經(jīng)大規(guī)模部署應(yīng)用了第二代IO加速技術(shù)的云主機(jī)。得益于上述設(shè)計(jì),之前備受困擾的cache盤(pán)IO堆積過(guò)多、性能瓶頸等問(wèn)題得到了極大的緩解,特別是IO堆積的問(wèn)題,在***代方案下,負(fù)載較高時(shí)經(jīng)常觸發(fā)并導(dǎo)致性能損失和運(yùn)維開(kāi)銷(xiāo),采用第二代IO加速技術(shù)后,該監(jiān)控告警只有偶現(xiàn)的幾例觸發(fā)。
五 寫(xiě)在***
云主機(jī)IO加速技術(shù)極大提升了機(jī)械盤(pán)隨機(jī)寫(xiě)的處理能力,使得用戶可以利用低廉的價(jià)格滿足業(yè)務(wù)需求。且該技術(shù)的本質(zhì)并不單單在于對(duì)機(jī)械盤(pán)加速,更是使系統(tǒng)層面具備了一種可以把性能和所處的存儲(chǔ)介質(zhì)進(jìn)行分離的能力,使得IO的性能并不受限于其所存儲(chǔ)的介質(zhì)。此外,一項(xiàng)底層技術(shù)在實(shí)際生產(chǎn)環(huán)境中的大規(guī)模應(yīng)用,其設(shè)計(jì)非常關(guān)鍵,特別是版本熱升級(jí)、容錯(cuò)以及性能考慮等都需要仔細(xì)斟酌。希望本文的經(jīng)驗(yàn)分享可以讓大家更好理解底層技術(shù)的特點(diǎn)及應(yīng)用,并在下次設(shè)計(jì)做出更好的改進(jìn)。