這些“秘密武器”,讓你輕松躋身Kaggle前2%
大數據文摘出品
編譯:Conrad、Hope、云舟
Kaggle的比賽真的好玩到令人上癮。在享受比賽的過程中,如果比賽成績能夠名列前茅那就非常棒了~~~
一位名叫Abhay Pawar的小哥開發(fā)了一些特征工程和機器學習建模的標準方法。這些簡單而強大的技術幫助他在Instacart Market Basket Analysis競賽中取得了前2%的成績。
下文是他以***人稱為小伙伴們分享他的技術經驗。希望對你有所幫助。enjoy!
要構建數值型連續(xù)變量的監(jiān)督學習模型,最重要的方面之一就是好好理解特征。觀察一個模型的部分依賴圖有助于理解模型的輸出是如何隨著每個特征變化而改變的。
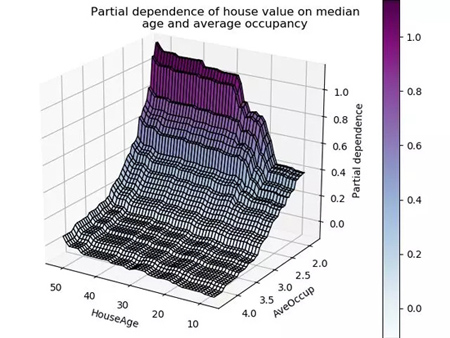
但是,繪制的圖形是基于訓練好的模型構建的,這會引發(fā)一些問題。而如果我們直接用未經學習的訓練數據去作圖,我們就能更好理解這些數據的深層含義。因為這樣做能幫助我們進行:
- 特征理解
- 識別嘈雜特征(這是最有趣的!)
- 特征工程
- 特征重要性
- 特征調試
- 泄漏檢測與理解
- 模型監(jiān)控
為了方便大家使用,我把這些方法用Python做了一個包,叫做featexp。本文中,我們會利用它來進行特征探索。我們將使用來自Kaggle競賽“違約者預測”的數據集,競賽的任務是基于已有的數據預測債務違約者。
- featexp:https://github.com/abhayspawar/featexp
- Home Credit Default Risk:https://www.kaggle.com/c/home-credit-default-risk/
特征理解
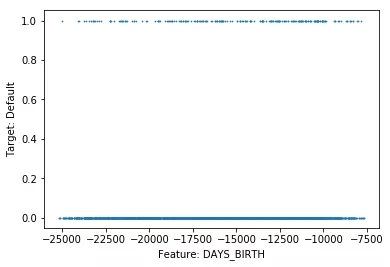
如果因變量 (分析目標) 是二分類數據,散點圖就不太好用了,因為所有點不是0就是1。針對連續(xù)型變量,數據點太多的話,會讓人很難理解目標和特征之間的關系。但是,用featexp可以做出更加友好的圖像。讓我們試一下吧!
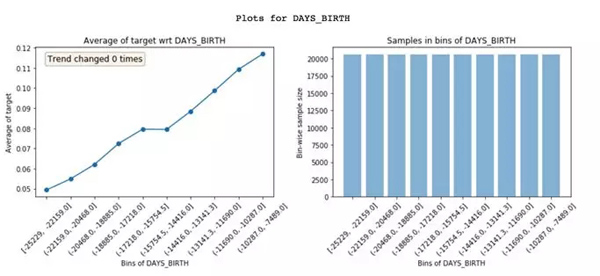
Featexp可以把一個數字特征,分成很多個樣本量相等的區(qū)間(X軸)。然后,計算出目標的平均值 (Mean),并繪制出左上方的圖像。在這里,平均值代表違約率。圖像告訴我們,年紀 (DAYS_BIRTH) 越大的人,違約率越低。
這非常合理的,因為年輕人通常更可能違約。這些圖能夠幫助我們理解客戶的特征,以及這些特征是如何影響模型的。右上方的圖像表示每個區(qū)間內的客戶數量。
識別嘈雜特征
嘈雜特征容易造成過擬合,分辨噪音一點也不容易。在featexp里,你可以跑一下測試集或者驗證集,然后對比訓練集和測試集的特征趨勢,從而找出嘈雜的特征。
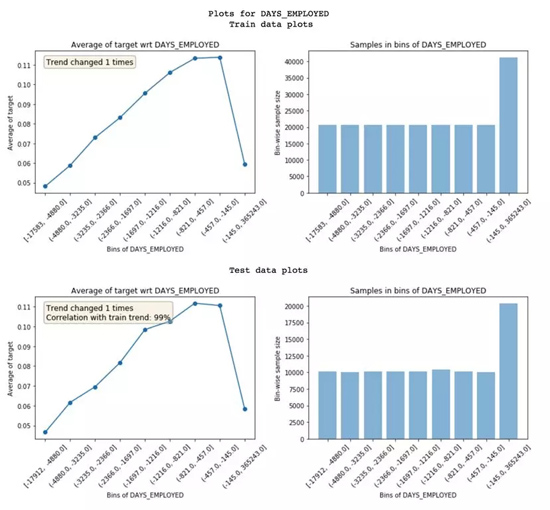
訓練集和測試集特征趨勢的對比
為了衡量噪音影響程度,featexp會計算兩個指標:
- 趨勢相關性 (從測試繪圖中可見) :如果一個特征在訓練集和測試集里面表現出來的趨勢不一樣,就有可能導致過擬合。這是因為,模型從測試集里學到的一些東西,在驗證集中不適用。趨勢相關性可以告訴我們訓練集和測試集趨勢的相似度,以及每個區(qū)間的平均值。上面這個例子中,兩個數據集的相關性達到了99%。看起來噪音不是很嚴重!
- 趨勢變化:有時候,趨勢會發(fā)生突然變化和反復變化。這可能就參入噪音了,但也有可能是特定區(qū)間內有其他獨特的特征對其產生了影響。如果出現這種情況,這個區(qū)間的違約率就沒辦法和其他區(qū)間直接對比了。
下面這個特征,就是嘈雜特征,訓練集和測試集沒有相同的趨勢:兩者相關性只有85%。有時候,可以選擇丟掉這樣的特征。
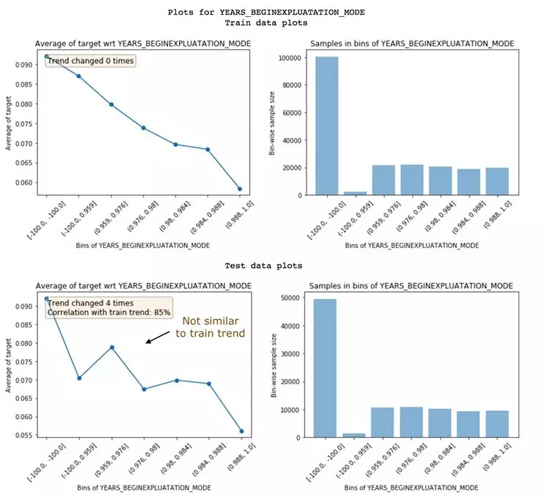
嘈雜特征的例子
拋棄相關性低的特征,這種做法在特征非常多、特征之間又充滿相關性的情況下比較適用。這樣可以減少過擬合,避免信息丟失。不過,別把太多重要的特征都丟掉了;否則模型的預測效果可能會大打折扣。同時,你也不能用重要性來評價特征是否嘈雜,因為有些特征既非常重要,又嘈雜得不得了。
用與訓練集不同時間段的數據來做測試集可能會比較好。這樣就能看出來數據是不是隨時間變化的了。
Featexp里有一個 get_trend_stats() 函數,可以返回一個數據框 (Dataframe) ,顯示趨勢相關性和趨勢變化。

get_trend_stats()返回的數據框
現在,可以試著去丟棄一些趨勢相關性弱的特征了,看看預測效果是否有提高。

用趨勢相關性進行不同特征選擇得到的的AUC值
我們可以看到,丟棄特征的相關性閾值越高,排行榜(LB)上的AUC越高。只要注意不要丟棄重要特征,AUC可以提升到0.74。有趣的是,測試集的AUC并沒有像排行榜的AUC變化那么大。完整代碼可以在featexp_demo記事本里面找到。
featexp_demo:
https://github.com/abhayspawar/featexp/blob/master/featexp_demo.ipynb
特征工程
通過查看這些圖表獲得的見解,有助于我們創(chuàng)建更好的特征。只需更好地了解數據,就可以實現更好的特征工程。除此之外,它還可以幫助你改良現有特征。下面來看另一個特征EXT_SOURCE_1:

EXT_SOURCE_1的特征與目標圖
具有較高EXT_SOURCE_1值的客戶違約率較低。但是,***個區(qū)間(違約率約8%)不遵循這個特征趨勢(上升并下降)。它只有-99.985左右的負值且人群數量較多。這可能意味著這些是特殊值,因此不遵循特征趨勢。幸運的是,非線性模型在學習這種關系時不會有問題。但是,對于像Logistic回歸這樣的線性模型,如果需要對特殊值和控制進行插值,就需要考慮特征分布,而不是簡單地使用特征的均值進行插補。
特征重要性
Featexp還可以幫助衡量特征的重要性。DAYS_BIRTH和EXT_SOURCE_1都有很好的趨勢。但是,EXT_SOURCE_1的人群集中在特殊值區(qū)間中,這表明它可能不如DAYS_BIRTH那么重要。基于XGBoost模型來衡量特征重要性,發(fā)現DAYS_BIRTH實際上比EXT_SOURCE_1更重要。
特征調試
查看Featexp的圖表,可以幫助你通過以下兩項操作來發(fā)現復雜特征工程代碼中的錯誤:
間")
零方差特征只展現一個區(qū)間
- 檢查特征的人群分布是否正確。由于一些疏忽,我遇到過多次類似上面這樣的極端情況。
- 在查看這些圖之前,我總是會先做假設,假設特征趨勢會是什么樣子的。如果特征趨勢看起來不符合預期,可能暗示著存在某些問題。實際上,這個驗證趨勢假設的過程使機器學習模型更有趣了!
泄漏檢測
從目標到特征的數據泄漏會導致過擬合。泄露的特征具有很高的特征重要性。要理解為什么在特征中會發(fā)生泄漏是很困難的,查看featexp圖像可以幫助理解這一問題。
在“Nulls”區(qū)間的特征違約率為0%,同時,在其他所有區(qū)間中的違約率為100%。顯然,這是泄漏的極端情況。只有當客戶違約時,此特征才有價值。基于此特征,可能是因為一個故障,或者因為這個特征在違約者中很常見。了解泄漏特征的問題所在能讓你更快地進行調試。

理解為什么特征會泄漏
模型監(jiān)控
由于featexp可計算兩個數據集之間的趨勢相關性,因此它可以很容易地利用于模型監(jiān)控。每次我們重新訓練模型時,都可以將新的訓練數據與測試好的訓練數據(通常是***次構建模型時的訓練數據)進行比較。趨勢相關性可以幫助你監(jiān)控特征信息與目標的關系是否發(fā)生了變化。
這些簡單的步驟總能幫助我在Kaggle或者實際工作中構建更好的模型。用featexp,花15分鐘去觀察那些圖像,是十分有價值的:它會帶你一步步看清黑箱里的世界。
還有什么其他方法可以幫助我們對特征進行探索嗎?如果你有更棒的想法,歡迎發(fā)郵件跟我交流abhayspawar@gmail.com。感謝你的閱讀!
相關報道:
https://towardsdatascience.com/my-secret-sauce-to-be-in-top-2-of-a-kaggle-competition-57cff0677d3c
【本文是51CTO專欄機構大數據文摘的原創(chuàng)文章,微信公眾號“大數據文摘( id: BigDataDigest)”】