攜程一次Redis遷移容器后的Slowlog“異常”分析

容器化對于Redis自動化運維效率、資源利用率方面都有巨大提升,攜程在對Redis在容器上性能和穩定性進行充分驗證后,啟動了生產Redis遷移容器化的項目。其中第一批次兩臺宿主機,第二批次五臺宿主機。
本次“異常”是第二批次遷移過程中發現的,排查過程一波三折,最終得出讓人吃驚的結論。
希望本次結論能給遇到同樣問題的小伙伴以啟發,另外本次分析問題的思路對于分析其他疑難雜癥也有一定借鑒作用。
一、問題描述
在某次Redis遷移容器后,DBA發來告警郵件,slowlog>500ms,同時在DBA的慢日志查詢里可以看到有1800ms左右的日志,如下圖1所示:
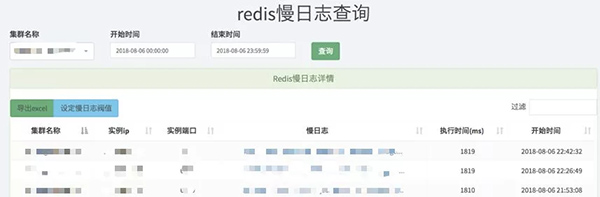
圖 1
二、分析過程
2.1 什么是Slowlog
在分析問題之前,先簡單解釋下Redis的slowlog。閱讀Redis源碼(圖2)不難發現,當某次Redis的操作大于配置中slowlog-log-slower-than設置的值時,Redis就會將該值記錄到內存中,通過slowlog get可以獲取該次slowlog發生的時間和耗時,圖1的監控數據也是從此獲得。
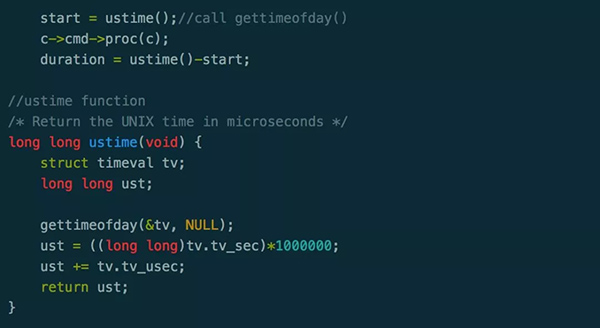
圖 2
也就是說,slowlog只是單純的計算Redis執行的耗時時間,與其他因素如網絡之類的都沒關系。
2.2 矛盾的日志
每次slowlog都是1800+ms并且都隨機出現,在第一批次Redis容器化的宿主機上完全沒有這種現象,而QPS遠小于第一批次遷移的某些集群,按常理很難解釋,這時候翻看CAT記錄,更加加重了我們的疑惑,見圖3:
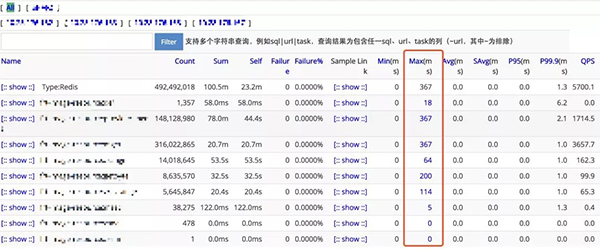
圖 3
CAT是攜程根據開源軟件(https://github.com/dianping/cat)的定制版本,用于客戶端記錄打點的耗時,從圖中可以很清晰的看到,Redis打點的最大值367ms也遠小于1800ms,它等于是說下面這張自相矛盾圖,見圖4:
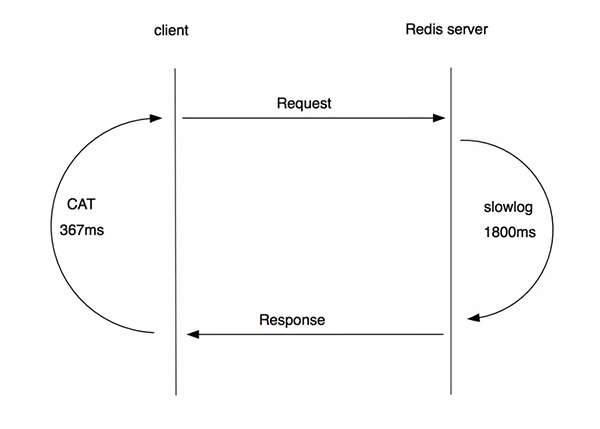
圖 4
2.3 求助社區
所以說,slowlog問題要么是CAT誤報,要么是Redis誤報,但Redis使用如此廣泛,并且經過詢問CAT的維護者說CAT有一定的消息丟棄率,而Redis在官方github issue中并沒有發現類似的slowlog情形,因此我們第一感覺是CAT誤報,并在官方Redis issue中提問,試圖獲取社區的幫助。
很快社區有人回復,可能是NUMA架構導致的問題,但也同時表示NUMA導致slowlog高達1800ms很不可思議。關于NUMA的資料網上有很多,這里不再贅述,我們在查閱相關NUMA資料后也發現,NUMA架構導致如此大的slowlog不太可能,因此放棄了這條路徑的嘗試。
2.4 豁然開朗
看上去每個方面好像都沒有問題,而且找不到突破口,排障至此陷入了僵局。
重新閱讀Redis源代碼,直覺發現gettimeofday()可能有問題,模仿Redis獲取slowlog的代碼,寫了一個簡答的死循環,每次Sleep一秒,看看打印出來的差值是否正好1秒多點,如圖5所示:

圖 5
圖5的程序大概運行了20分鐘后,奇跡出現了,gettimeofday果然有問題,下面是上面程序測試時間打印出來的LOG,如圖6:
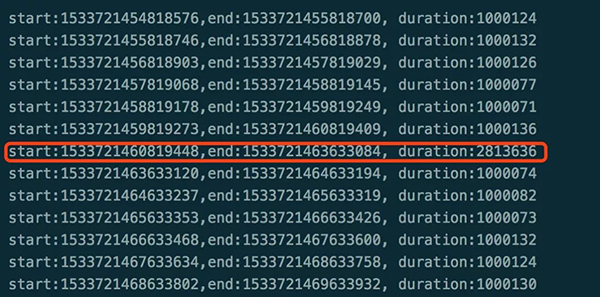
圖 6
圖6中標紅的時間減去1秒等于1813ms,與slowlog時間如此相近!在容器所在的物理機上也測試一遍,發現有同樣的現象,排除因容器導致slowlog,希望的曙光似乎就在眼前了,那么問題又來了:
- 到底為什么會相差1800ms+呢?
- 為什么第一批機器沒有這種現象呢?
- 為什么之前跑在物理機上的Redis沒有這種現象呢?
帶著這三個問題,重新審視系統調用gettimeofday獲取當前時間背后的原理,發現一番新天地。
三、系統時鐘
系統時鐘的實現非常復雜,并且參考資料非常多。
簡單來說 我們可以通過命令:
- cat /sys/devices/system/clocksource/clocksource0/current_clocksource
來獲取當前系統的時鐘源,攜程的宿主機上都是統一Time Stamp Counter(TSC):80x86微處理器包括一個時鐘輸入插口,用來接收來自外部振蕩器的時鐘信號,從奔騰80x86微處理器開始,增加了一個計數器。
隨著每增加一個時鐘信號而加一,通過rdtsc匯編指令也可以去讀TSC寄存器,這樣如果CPU的頻率是1GHz,TSC寄存器就能提供納秒級別的計時精度,并且現代CPU通過FLAG constant_tsc來保證即使CPU休眠也不影響TSC的頻率。
當選定TSC為時鐘源后,gettimeofday獲取墻上時鐘(wall-clock)正是從TSC寄存器讀出來的值轉換而來,所謂墻上時鐘主要是參照現實世界人們通過墻上時鐘獲取當前時間,但是用來計時并不準確,可能會被NTP或者管理員修改。
那么問題又來了,宿主機的時間沒有被管理員修改,難道是被NTP修改?即使是NTP來同步,每次相差也不該有1800ms這么久,它的意思是說難道宿主機的時鐘每次都在變慢然后被NTP拉回到正常時間?我們手工執行了下NTP同步,發現的確是有很大偏差,如圖7所示:

圖 7
按常識時鐘正常的物理機與NTP服務器時鐘差異都在1ms以內,相差1s+絕對有問題,而且還是那個老問題,為什么第一批次的機器上沒有問題?
四、內核BUG
兩個批次宿主機一樣的內核版本,第一批沒問題而第二批有問題,差異只可能在硬件上,非常有可能在計時上,翻看內核的commit log終于讓我們發現了這樣的commit,如圖8所示:

圖 8
該commit非常清楚指出,在4.9以后添加了一個宏定義INTEL_FAM6_SKYLAKE_X,但因為搞錯了該類型CPU的crystal frequency會導致該類型的CPU每10分鐘慢1秒鐘。
這時再看看我們的出問題的第二批宿主機xeon bronze 3104正好是skylake-x的服務器,影響4.9-4.13的內核版本,宿主機內核4.10正好中招。
并且NTP每次同步間隔1024秒約慢1700ms,與slowlog異常完全吻合,而第一批次的機器CPU都不是SKYLAKE-X平臺的,避開了這個BUG,遷移之前Redis所在的物理機內核是3.10版本,自然也不存在這個問題。至此,終于解開上面三個疑惑。
五、總結
5.1 問題根因
通過上面的分析可以看出,問題根因在于內核4.9-4.13之間skylake-x平臺TSC晶振頻率的代碼BUG,也就是說同時觸發這兩個因素都會導致系統時鐘變慢,疊加上Redis計時使用的gettimeofday會容易被NTP修改導致了本文開頭詭異的slowlog“異常”。有問題的宿主機內核升級到4.14版本后,時鐘變慢的BUG得到了修復。
5.2 怎么獲取時鐘
對于應用需要打點記錄當前時間的場景,也就是說獲取Wall-Clock,可以使用clock_gettime傳入CLOCK_REALTIME參數,雖然gettimeofday也可以實現同樣的功能,但不建議繼續使用,因為在新的POSIX標準中該函數已經被廢棄。
對于應用需要記錄某個方法耗時的場景,必須使用clock_gettime傳入CLOCK_MONOTONIC參數,該參數獲得的是自系統開機起單調遞增的納秒級別精度時鐘,相比gettimeofday精度提高不少,并且不受NTP等外部服務影響,能更準確來統計耗時(Java中對應的是System.nanoTime),也就是說所有使用gettimeofday來統計耗時(Java中是System.currenttimemillis)的做法本質上都是錯誤的。