零基礎搭建Hadoop大數據處理-初識
在互聯網的世界中數據都是以TB、PB的數量級來增加的,特別是像BAT光每天的日志文件一個盤都不夠,更何況是還要基于這些數據進行分析挖掘,更甚者還要實時進行數據分析,學習,如雙十一淘寶的交易量的實時展示。

大數據什么叫大?4個特征:
體量化 Volume,就是量大。
多樣化 Variety,可能是結構型的數據,也可能是非結構行的文本,圖片,視頻,語音,日志,郵件等
快速化 Velocity,產生快,處理也需要快。
價值密度低 Value,數據量大,但單個數據沒什么意義,需要宏觀的統計體現其隱藏的價值。
可以看出想只要一臺強大的服務器來實時處理這種體量的數據那是不可能的,而且成本昂貴,代價相當大,普通的關系型數據庫也隨著數據量的增大其處理時間也隨之增加,那客戶是不可能忍受的,所以我們需要Hadoop來解決此問題。
優點:
Hadoop是一個能夠讓用戶輕松架構和使用的分布式計算平臺。用戶可以輕松地在Hadoop上開發和運行處理海量數據的應用程序。它主要有以下幾個優點:
高可靠性。Hadoop按位存儲和處理數據的能力值得人們信賴。
高擴展性。Hadoop是在可用的計算機集簇間分配數據并完成計算任務的,這些集簇可以方便地擴展到數以千計的節點中。
高效性。Hadoop能夠在節點之間動態地移動數據,并保證各個節點的動態平衡,因此處理速度非常快。
高容錯性。Hadoop能夠自動保存數據的多個副本,并且能夠自動將失敗的任務重新分配。
低成本。與一體機、商用數據倉庫以及QlikView、Yonghong Z-Suite等數據集市相比,hadoop是開源的,項目的軟件成本因此會大大降低。
Hadoop得以在大數據處理應用中廣泛應用得益于其自身在數據提取、變形和加載(ETL)方面上的天然優勢。Hadoop的分布式架構,將大數據處理引擎盡可能的靠近存儲,對例如像ETL這樣的批處理操作相對合適,因為類似這樣操作的批處理結果可以直接走向存儲。Hadoop的MapReduce功能實現了將單個任務打碎,并將碎片任務(Map)發送到多個節點上,之后再以單個數據集的形式加載(Reduce)到數據倉庫里。
Hadoop在各應用中是最底層,最基礎的組件,所以其重要性不言而喻。
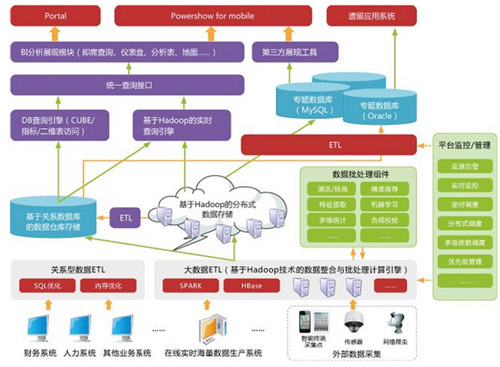
框架結構
Hadoop主要由HDFS ( 分布式文件系統)和MapReduce (并行計算框架)組成。
Hadoop 由許多元素構成。其最底部是 Hadoop Distributed File System(HDFS),它存儲 Hadoop 集群中所有存儲節點上的文件。HDFS(對于本文)的上一層是MapReduce 引擎,該引擎由 JobTrackers 和 TaskTrackers 組成。通過對Hadoop分布式計算平臺最核心的分布式文件系統HDFS、MapReduce處理過程,以及數據倉庫工具Hive和分布式數據庫Hbase的介紹,基本涵蓋了Hadoop分布式平臺的所有技術核心。
HDFS
對外部客戶機而言,HDFS就像一個傳統的分級文件系統。可以創建、刪除、移動或重命名文件,等等。但是 HDFS 的架構是基于一組特定的節點構建的,這是由它自身的特點決定的。這些節點包括 NameNode(僅一個),它在 HDFS 內部提供元數據服務;DataNode,它為 HDFS 提供存儲塊。由于僅存在一個 NameNode,因此這是 HDFS 的一個缺點(單點失敗)。
存儲在 HDFS 中的文件被分成塊,然后將這些塊復制到多個計算機中(DataNode)。這與傳統的 RAID 架構大不相同。塊的大小(通常為 64MB)和復制的塊數量在創建文件時由客戶機決定。NameNode 可以控制所有文件操作。HDFS 內部的所有通信都基于標準的 TCP/IP 協議。
單節點物理結構
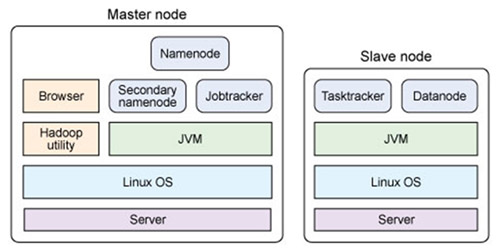
主從結構
主節點,只有一個: namenode
從節點,有很多個: datanodes
namenode負責:接收用戶操作請求 、維護文件系統的目錄結構、管理文件與block之間關系,block與datanode之間關系
NameNode 是一個通常在 HDFS 實例中的單獨機器上運行的軟件。它負責管理文件系統名稱空間和控制外部客戶機的訪問。
datanode負責:存儲文件文件被分成block存儲在磁盤上、為保證數據安全,文件會有多個副本
MapReduce
MapReduce是處理大量半結構化數據集合的編程模型。編程模型是一種處理并結構化特定問題的方式。例如,在一個關系數據庫中,使用一種集合語言執行查詢,如SQL。告訴語言想要的結果,并將它提交給系統來計算出如何產生計算。還可以用更傳統的語言(C++,Java),一步步地來解決問題。這是兩種不同的編程模型,MapReduce就是另外一種。
MapReduce和Hadoop是相互獨立的,實際上又能相互配合工作得很好。
主從結構
主節點,只有一個: JobTracker
從節點,有很多個: TaskTrackers
JobTracker負責:接收客戶提交的計算任務、把計算任務分給TaskTrackers執行、監控TaskTracker的執行情況
TaskTrackers負責:執行JobTracker分配的計算任務
Hadoop能做什么?
- 大數據量存儲:分布式存儲
- 日志處理: Hadoop擅長這個
- 海量計算: 并行計算
- ETL:數據抽取到oracle、mysql、DB2、mongdb及主流數據庫
- 使用HBase做數據分析: 用擴展性應對大量的寫操作—Facebook構建了基于HBase的實時數據分析系統
- 機器學習: 比如Apache Mahout項目
- 搜索引擎:hadoop + lucene實現
- 數據挖掘:目前比較流行的廣告推薦
- 大量地從文件中順序讀。HDFS對順序讀進行了優化,代價是對于隨機的訪問負載較高。
- 數據支持一次寫入,多次讀取。對于已經形成的數據的更新不支持。
- 數據不進行本地緩存(文件很大,且順序讀沒有局部性)
- 任何一臺服務器都有可能失效,需要通過大量的數據復制使得性能不會受到大的影響。
- 用戶細分特征建模
- 個性化廣告推薦
- 智能儀器推薦
擴展
實際應用:
Hadoop+HBase建立NoSQL分布式數據庫應用
Flume+Hadoop+Hive建立離線日志分析系統
Flume+Logstash+Kafka+Spark Streaming進行實時日志處理分析
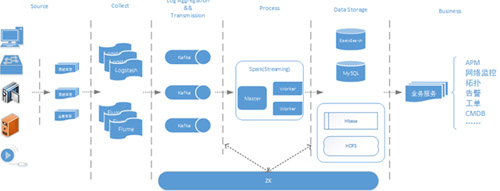
酷狗音樂的大數據平臺
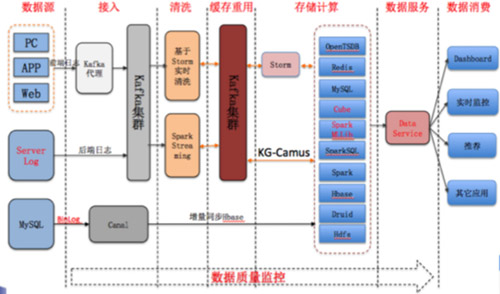
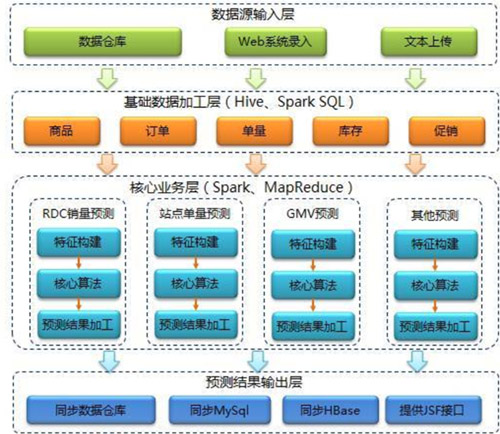
京東的智能供應鏈預測系統
Hadoop的學習不僅僅是學習Hadoop,還要學習Linux,網絡知識,Java、還有數據結構和算法等等,所以萬里長征才開始第一步,希望Hadoop學習不是從了解到放棄。