如何判斷一個元素在億級數據中是否存在?
最近有朋友問我這么一個面試題目:現在有一個非常龐大的數據,假設全是 int 類型。現在我給你一個數,你需要告訴我它是否存在其中(盡量高效)。
需求其實很清晰,只是要判斷一個數據是否存在即可。但這里有一個比較重要的前提:非常龐大的數據。
常規實現
先不考慮這個條件,我們腦海中出現的***種方案是什么?我想大多數想到的都是用 HashMap 來存放數據,因為它的寫入查詢的效率都比較高。
寫入和判斷元素是否存在都有對應的 API,所以實現起來也比較簡單。為此我寫了一個單測,利用 HashSet 來存數據(底層也是 HashMap );同時為了后面的對比將堆內存寫死:
- -Xms64m -Xmx64m -XX:+PrintHeapAtGC -XX:+HeapDumpOnOutOfMemoryError
為了方便調試加入了 GC 日志的打印,以及內存溢出后 Dump 內存:
- @Test
- public void hashMapTest(){
- long star = System.currentTimeMillis();
- Set<Integer> hashset = new HashSet<>(100) ;
- for (int i = 0; i < 100; i++) {
- hashset.add(i) ;
- }
- Assert.assertTrue(hashset.contains(1));
- Assert.assertTrue(hashset.contains(2));
- Assert.assertTrue(hashset.contains(3));
- long end = System.currentTimeMillis();
- System.out.println("執行時間:" + (end - star));
- }
當我只寫入 100 條數據時自然是沒有問題的。還是在這個基礎上,寫入 1000W 數據試試:
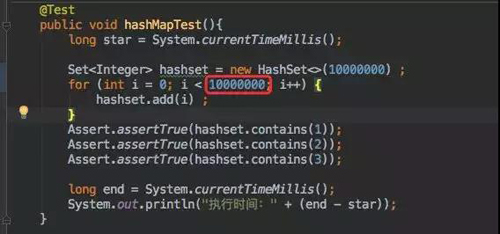
執行后馬上就內存溢出:
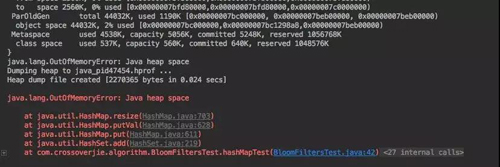
可見在內存有限的情況下我們不能使用這種方式。實際情況也是如此;既然要判斷一個數據是否存在于集合中,考慮的算法的效率以及準確性肯定是要把數據全部 load 到內存中的。
Bloom Filter
基于上面分析的條件,要實現這個需求最需要解決的是如何將龐大的數據 load 到內存中。
而我們是否可以換種思路,因為只是需要判斷數據是否存在,也不是需要把數據查詢出來,所以完全沒有必要將真正的數據存放進去。
偉大的科學家們已經幫我們想到了這樣的需求。Burton Howard Bloom 在 1970 年提出了一個叫做 Bloom Filter(中文翻譯:布隆過濾)的算法。
它主要用于解決判斷一個元素是否在一個集合中,但它的優勢是只需要占用很小的內存空間以及有著高效的查詢效率。所以在這個場景下再合適不過了。
Bloom Filter 原理
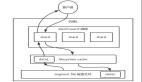
下面來分析下它的實現原理。官方的說法是:它是一個保存了很長的二級制向量,同時結合 Hash 函數實現的。
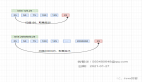
聽起來比較繞,但是通過一個圖就比較容易理解了:
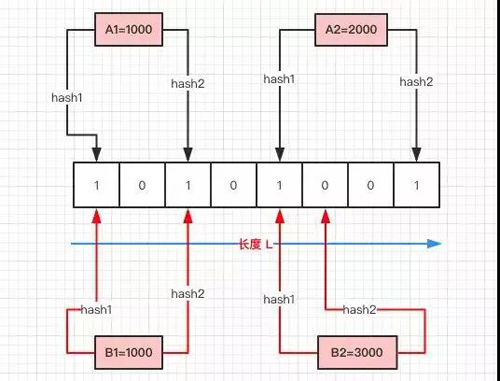
如上圖所示:
- 首先需要初始化一個二進制的數組,長度設為 L(圖中為 8),同時初始值全為 0 。
- 當寫入一個 A1=1000 的數據時,需要進行 H 次 Hash 函數的運算(這里為 2 次);與 HashMap 有點類似,通過算出的 HashCode 與 L 取模后定位到 0、2 處,將該處的值設為 1。
- A2=2000 也是同理計算后將 4、7 位置設為 1。
- 當有一個 B1=1000 需要判斷是否存在時,也是做兩次 Hash 運算,定位到 0、2 處,此時他們的值都為 1 ,所以認為 B1=1000 存在于集合中。
- 當有一個 B2=3000 時,也是同理。***次 Hash 定位到 index=4 時,數組中的值為 1,所以再進行第二次 Hash 運算,結果定位到 index=5 的值為 0,所以認為 B2=3000 不存在于集合中。
整個的寫入、查詢的流程就是這樣,匯總起來就是:對寫入的數據做 H 次 Hash 運算定位到數組中的位置,同時將數據改為 1 。
當有數據查詢時也是同樣的方式定位到數組中。一旦其中的有一位為 0 則認為數據肯定不存在于集合,否則數據可能存在于集合中。
所以布隆過濾有以下幾個特點:
- 只要返回數據不存在,則肯定不存在。
- 返回數據存在,但只能是大概率存在。
- 同時不能清除其中的數據。
***點應該都能理解,重點解釋下 2、3 點。為什么返回存在的數據卻是可能存在呢,這其實也和 HashMap 類似。
在有限的數組長度中存放大量的數據,即便是再***的 Hash 算法也會有沖突,所以有可能兩個完全不同的 A、B 兩個數據***定位到的位置是一模一樣的。
這時拿 B 進行查詢時那自然就是誤報了。刪除數據也是同理,當我把 B 的數據刪除時,其實也相當于是把 A 的數據刪掉了,這樣也會造成后續的誤報。
基于以上的 Hash 沖突的前提,所以 Bloom Filter 有一定的誤報率,這個誤報率和 Hash 算法的次數 H,以及數組長度 L 都是有關的。
自己實現一個布隆過濾
算法其實很簡單不難理解,于是利用 Java 實現了一個簡單的雛形:
- 首先初始化了一個 int 數組。
- 寫入數據的時候進行三次 Hash 運算,同時把對應的位置置為 1。
- 查詢時同樣的三次 Hash 運算,取到對應的值,一旦值為 0 ,則認為數據不存在。
代碼如下:
- public class BloomFilters {
- /**
- * 數組長度
- */
- private int arraySize;
- /**
- * 數組
- */
- private int[] array;
- public BloomFilters(int arraySize) {
- this.arraySize = arraySize;
- array = new int[arraySize];
- }
- /**
- * 寫入數據
- * @param key
- */
- public void add(String key) {
- int first = hashcode_1(key);
- int second = hashcode_2(key);
- int third = hashcode_3(key);
- array[first % arraySize] = 1;
- array[second % arraySize] = 1;
- array[third % arraySize] = 1;
- }
- /**
- * 判斷數據是否存在
- * @param key
- * @return
- */
- public boolean check(String key) {
- int first = hashcode_1(key);
- int second = hashcode_2(key);
- int third = hashcode_3(key);
- int firstIndex = array[first % arraySize];
- if (firstIndex == 0) {
- return false;
- }
- int secondIndex = array[second % arraySize];
- if (secondIndex == 0) {
- return false;
- }
- int thirdIndex = array[third % arraySize];
- if (thirdIndex == 0) {
- return false;
- }
- return true;
- }
- /**
- * hash 算法1
- * @param key
- * @return
- */
- private int hashcode_1(String key) {
- int hash = 0;
- int i;
- for (i = 0; i < key.length(); ++i) {
- hash = 33 * hash + key.charAt(i);
- }
- return Math.abs(hash);
- }
- /**
- * hash 算法2
- * @param data
- * @return
- */
- private int hashcode_2(String data) {
- final int p = 16777619;
- int hash = (int) 2166136261L;
- for (int i = 0; i < data.length(); i++) {
- hash = (hash ^ data.charAt(i)) * p;
- }
- hash += hash << 13;
- hash ^= hash >> 7;
- hash += hash << 3;
- hash ^= hash >> 17;
- hash += hash << 5;
- return Math.abs(hash);
- }
- /**
- * hash 算法3
- * @param key
- * @return
- */
- private int hashcode_3(String key) {
- int hash, i;
- for (hash = 0, i = 0; i < key.length(); ++i) {
- hash += key.charAt(i);
- hash += (hash << 10);
- hash ^= (hash >> 6);
- }
- hash += (hash << 3);
- hash ^= (hash >> 11);
- hash += (hash << 15);
- return Math.abs(hash);
- }
- }
實現邏輯其實就和上文描述的一樣。下面來測試一下,同樣的參數:
- -Xms64m -Xmx64m -XX:+PrintHeapAtGC
- @Test
- public void bloomFilterTest(){
- long star = System.currentTimeMillis();
- BloomFilters bloomFilters = new BloomFilters(10000000) ;
- for (int i = 0; i < 10000000; i++) {
- bloomFilters.add(i + "") ;
- }
- Assert.assertTrue(bloomFilters.check(1+""));
- Assert.assertTrue(bloomFilters.check(2+""));
- Assert.assertTrue(bloomFilters.check(3+""));
- Assert.assertTrue(bloomFilters.check(999999+""));
- Assert.assertFalse(bloomFilters.check(400230340+""));
- long end = System.currentTimeMillis();
- System.out.println("執行時間:" + (end - star));
- }
執行結果如下:
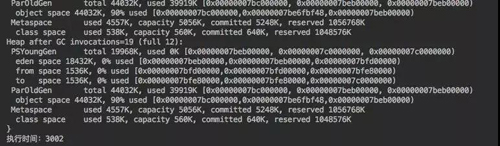
只花了 3 秒鐘就寫入了 1000W 的數據同時做出來準確的判斷。
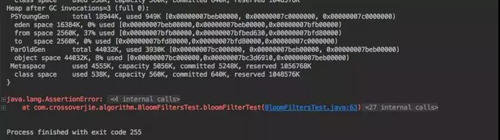
當讓我把數組長度縮小到了 100W 時就出現了一個誤報,400230340 這個數明明沒在集合里,卻返回了存在。
這也體現了 Bloom Filter 的誤報率。我們提高數組長度以及 Hash 計算次數可以降低誤報率,但相應的 CPU、內存的消耗就會提高;這就需要根據業務需要自行權衡。
Guava 實現
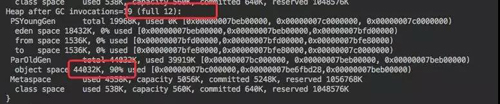
剛才的方式雖然實現了功能,也滿足了大量數據。但觀察 GC 日志非常頻繁,同時老年代也使用了 90%,接近崩潰的邊緣。
總的來說就是內存利用率做的不好。其實 Google Guava 庫中也實現了該算法,下面來看看業界權威的實現:
- -Xms64m -Xmx64m -XX:+PrintHeapAtGC
- @Test
- public void guavaTest() {
- long star = System.currentTimeMillis();
- BloomFilter<Integer> filter = BloomFilter.create(
- Funnels.integerFunnel(),
- 10000000,
- 0.01);
- for (int i = 0; i < 10000000; i++) {
- filter.put(i);
- }
- Assert.assertTrue(filter.mightContain(1));
- Assert.assertTrue(filter.mightContain(2));
- Assert.assertTrue(filter.mightContain(3));
- Assert.assertFalse(filter.mightContain(10000000));
- long end = System.currentTimeMillis();
- System.out.println("執行時間:" + (end - star));
- }
也是同樣寫入了 1000W 的數據,執行沒有問題。
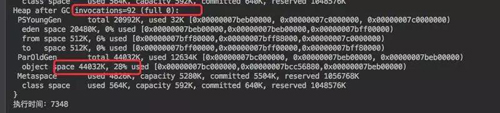
觀察 GC 日志會發現沒有一次 fullGC,同時老年代的使用率很低。和剛才的一對比這里明顯的要好上很多,也可以寫入更多的數據。
那就來看看 Guava 它是如何實現的?構造方法中有兩個比較重要的參數,一個是預計存放多少數據,一個是可以接受的誤報率。 我這里的測試 demo 分別是 1000W 以及 0.01。
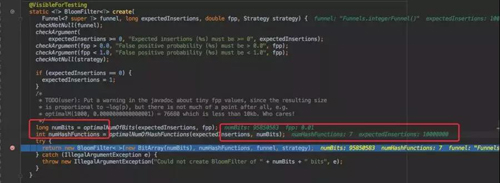
Guava 會通過你預計的數量以及誤報率幫你計算出你應當會使用的數組大小 numBits 以及需要計算幾次 Hash 函數 numHashFunctions 。這個算法計算規則可以參考維基百科。
put 寫入函數
真正存放數據的 put 函數如下:
- 根據 murmur3_128 方法的到一個 128 位長度的 byte[]。
- 分別取高低 8 位的到兩個 Hash 值。
- 再根據初始化時的到的執行 Hash 的次數進行 Hash 運算。
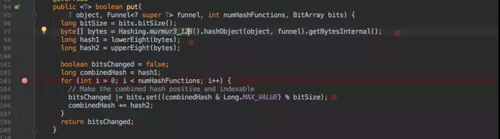
- bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
其實也是 Hash 取模拿到 index 后去賦值 1,重點是 bits.set() 方法。
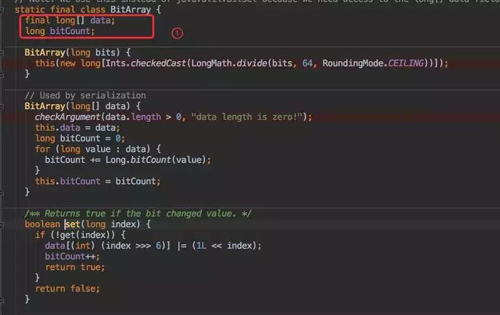
set 方法是 BitArray 中的一個函數,BitArray 就是真正存放數據的底層數據結構,利用了一個 long[]data 來存放數據。
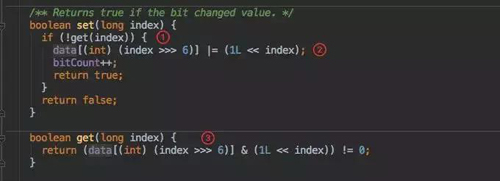
所以 set() 時候也是對這個 data 做處理:
- 在 set 之前先通過 get() 判斷這個數據是否存在于集合中,如果已經存在則直接返回告知客戶端寫入失敗。
- 接下來就是通過位運算進行位或賦值。
- get() 方法的計算邏輯和 set 類似,只要判斷為 0 就直接返回存在該值。
mightContain 是否存在函數
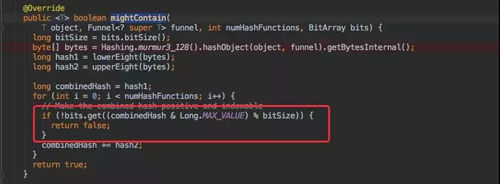
前面幾步的邏輯都是類似的,只是調用了剛才的 get() 方法判斷元素是否存在而已。
總結
布隆過濾的應用還是蠻多的,比如數據庫、爬蟲、防緩存擊穿等。特別是需要精確知道某個數據不存在時做點什么事情就非常適合布隆過濾。
本示例代碼參考這里:https://github.com/crossoverJie/JCSprout