億級數據算不準?轉轉財務中臺的架構"換血"實錄
引言
在轉轉業務快速發展的過程中,業財系統作為連接業務與財務的核心樞紐,其重要性日益凸顯。早期我們基于微服務架構構建了“金字塔”系統,通過統一收集上下游業務數據并加工財務指標,支撐了公司初期的財務分析需求。然而,隨著業務復雜度提升和數據量激增,這套架構逐漸暴露出諸多問題:指標差異難以溯源、數據處理效率低下、系統穩定性不足等。本文將詳細分享我們如何通過架構演進,最終構建出高效可靠的敏捷財報系統。
第一階段:微服務架構的困境分析
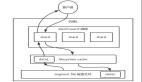
1.1 初始架構設計
 產品架構
產品架構
 數據分層加工
數據分層加工
1.2 存儲設計
業務特點分析:
特點1:各業務數據字段基本不相同,幾乎沒有可抽取出的統一字段,如果想統一存儲,只能以JSON字符串的形式;
特點2:需要對加工后的財務數據實時可查,若以JSON存儲,不方便結構化查詢;
特點3:如果不統一存儲,來一個業務新建一些表,維護成本很高,萬一數據量大,還涉及到分庫分表問題;
特點4:源數據來源方式不相同,有用接口的,有用云窗的,有人工后臺錄入的;由于早期數據量并不大,基于以上業務特點,采用了如下的存儲方式。
 image
image
引入 ES 用于支撐多維數據查詢,采用監聽 binlog 同步 ES 的方式進行數據同步。
各模塊源數據統一組裝成 JSON 字符串,存儲在金字塔項目的一張表(JSON 表,以下簡稱source_data表)中,源數據的每個模塊都有自己的唯一Code,binlog處理程序根據Code統一將 JSON 表數據按照每個模塊解析到 ES 對應索引中,這樣可以支持數據實時結構化查詢,以及后續新增模塊接入的話,不需要再開發同步ES的代碼。在 MySQL 庫中source_data表的數據量達到一定量級后,只針對source_data表分表即可。
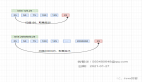
1.3 調度模型設計
由于需要離線處理多個模塊的指標數據,采用離線定時任務的方式進行處理,這里使用了分布式調度任務框架xxl-job。
 調度流程
調度流程
調度模型可以簡化為上圖流程所示。
可能這里有同學會想,為啥不采用xxl-job的分片廣播的形式進行處理, 而采用mq廣播消費的方式。
- 一方面主要是考慮到執行DWD任務種類很多,涉及物流費、支付手續費等任務。并且每個模塊處理的參數比較個性化。這里主要是做任務分發,針對一個模塊的任務只能一臺機器獲取(簡化處理模型),然后內部多線程處理這個模塊。而一臺機器可以爭搶0~N個模塊的任務。而xxl-job分片任務的初衷是多臺機器共同處理同一模塊的分片數據。
- 另一方面是想在業務層面判斷某些模塊任務是否執行完成,做一些更精細化的控制。這里xxl-job框架層面不支持。
1.4 處理模型設計
 任務處理
任務處理
在內存中通過RPC進行維度關聯并進行指標計算,計算完的結果存入dwd_financial,之后分別根據各個指標的要求匯總統計存入dws_financial表中,后續定時將指標數據同步到Hive中供分析部門使用。
第二階段:架構演進的考量
2.1 核心問題分析
問題1:數據完整性難以保證
微服務架構下,數據分散在各個微服務所對應的數據庫中,數據形成孤島。財務計算需要跨多個服務獲取維度和度量數據:
// 訂單金額計算需要調用多個服務
public BigDecimal calculateOrderAmount(Long orderId) {
Order order = orderService.getOrder(orderId); // 1. 獲取基礎訂單
User user = userService.getUser(order.getUserId()); // 2. 獲取用戶等級
Coupon coupon = couponService.getCoupon(...); // 3. 獲取優惠信息
// ...更多服務調用
}- RPC調用不穩定,難以保證維度不缺失,即使重試也不一定能100%成功,維度缺失率高達10%。
- 如果某條數據處理失敗后,簡單重試幾次還失敗,那就整體失敗了,對后續的處理鏈路會存在阻斷。如果不阻斷,計算的數據維度缺失,最終統計的結果也不準。兩者之間存在博弈。
問題2:任務調度與數據同步的不可靠性
- ES同步狀態不可見,只能預留大致時間緩沖,容易出現ES沒同步完成,就開始計算指標數據了,造成差異。
- xxl-job任務調度與云窗(58大數據平臺)數據抽取不能聯動,可能存在xxl-job還沒執行完,就開始了數據抽取任務,導致數據不準確。
問題3:擴展性瓶頸
隨著數據量增長:
- 單機處理能力達到上限(最高延遲6小時)。
- 新增指標需要修改代碼并重新部署。
- 資源無法彈性擴展。
2.2 解決思路
1. 盡量規避RPC調用:
- 如果還采用微服務架構,則需要成功將維度數據預加載到本地緩存,但維度之多,以及非維度的數據也可能需要RPC才能獲取到,所以不能完全解決。
- 不用RPC來關聯各微服務的數據,而采用數據中心的思想,將多個微服務的數據庫同步到數據中心進行統一處理。
2. 解耦分析場景:將分析型負載從交易系統中剝離。 例如將多個微服務數據關聯后分類匯總的功能,從微服務中拆分出來,微服務只做OLTP相關功能。
3. 采用統一的調度生態:如可以采用云窗統一的信號調度。不過整體架構得跟著改造,不能再用微服務處理。
4. 多機器并行處理:可以采用分布式計算框架Spark進行并行處理,優化單機處理瓶頸。
2.3 下一步如何抉擇
我們評估了三種可能的演進方向:
方案 | 優點 | 缺點 | 適用場景 |
增強現有微服務架構 | 改動小,延續現有技術棧 | 無法根本解決分析瓶頸 | 小規模數據 |
引入大數據技術棧 | 專業分析能力 | 學習成本高 | 中大規模數據分析 |
采用商業解決方案 | 開箱即用 | 成本高,靈活性差 | 快速上線需求 |
最終決策因素:
- 業務數據量已超過單機處理能力。
- 每月需要離線處理千萬級、億級別數據。
- 財務分析需求日益復雜(需要支持多維分析)。
- 團隊有3個月窗口期進行技術轉型。
經過對比,嘗試引入大數據技術棧來解決目前的痛點。
2.4 數據處理的本質差異
- 微服務實時調用 vs 大數據批處理
微服務RPC 需實時調用多個服務獲取維度及度量,網絡延遲、服務故障會導致調用鏈斷裂(如超時率高達5%),且分布式事務難以保證一致性。
大數據技術(如Spark/Hadoop)采用批處理模式,通過ETL流程將數據集中處理,所有維度關聯在計算前已完成,避免運行時依賴外部服務。
- 計算向數據移動的思想大數據框架(如MapReduce)將計算任務分發到數據存儲節點執行,減少網絡傳輸;而微服務RPC需跨網絡頻繁傳輸數據,增加不可靠性。
第三階段:新架構設計
3.1 數據模型設計
3.1.1 分層設計(核心基礎):
 數據流向
數據流向
- ODS層(Operational Data Store):操作數據存儲層,存儲原始數據鏡像。
- DW層(Data Warehouse):數據倉庫層,存儲經過標準規范化處理(即數據清洗)后的運營數據,是基礎事實數據明細層。如:收入成本明細數據、mysql各業務數據經過ETL處理后的表。
- DIM層: 維度數據層,主要包含一些字典表、維度數據。如:品類字典表、城市字典表、渠道字典表、終端類型表、支付狀態表等。
- DM層(Data Market):數據集市層,按部門按專題進行劃分,支持OLAP分析、數據分發等。如:日活用戶業務分析表,商業廣告多維分析報表,銷售回收明細寬表。
- ADS(Aplication Data Store)層:直接面向應用的數據服務層。
3.1.2 維度建模:
選擇業務過程 --> 聲明粒度 --> 確定維度 --> 設計事實表
 星型模型示例
星型模型示例
基于事實和維度描述業務場景,構建星型模型。
-- 共享維度表
CREATE TABLE dim_time (
date_key INT PRIMARY KEY,
full_date DATE,
day_of_week TINYINT,
month TINYINT,
quarter TINYINT,
year SMALLINT
);
-- 訂單事實表
CREATE TABLE fact_orders (
order_id BIGINT,
date_key INT REFERENCES dim_time,
-- 其他字段...
);
-- 庫存事實表
CREATE TABLE fact_inventory (
sku_id BIGINT,
date_key INT REFERENCES dim_time,
-- 其他字段...
);建模后的好處:
- 方便一致性維度的復用和管理。多個事實可以關聯相同維度。
- 擴展靈活性高:維度變化不影響現有事實,各自獨立更新。
- ETL開發高效,方便擴充不同的分析主題。
3.1.3 調度系統:
- 統一采用云窗任務依賴的方式,實現父子任務管理,統一調度模型。
- 關鍵路徑監控和自動重試。
3.2 大數據技術選型
核心組件對比:
計算引擎對比:
引擎 | 計算模型 | 適用規模 | 典型延遲 | SQL兼容性 | 容錯機制 | 資源消耗 | 學習曲線 | 最佳場景 | 企業案例 |
Hive(MR) | 批處理(MapReduce) | <10TB | 小時級 | HiveQL | 磁盤Checkpoint | 高(IO) | 低 | 歷史數據分析、小規模ETL | 傳統銀行數倉 |
Hive(Tez) | DAG批處理 | <50TB | 分鐘-小時 | HiveQL | 任務重試 | 中 | 低 | 中等規模數倉 | 電信運營商 |
Spark SQL | 內存批處理 | 10PB+ | 秒-分鐘 | ANSI SQL | 內存Lineage | 高(內存) | 中 | 大規模ETL、迭代計算 | 互聯網公司 |
Flink Batch | 流批一體 | 1PB+ | 秒級 | ANSI SQL | 精確一次(Checkpoint) | 高 | 高 | 流批統一架構 | 實時數倉場景 |
OLAP引擎對比:
維度 | StarRocks | Doris | ClickHouse |
單表查詢性能 | 快(向量化引擎 + SIMD 優化) | 較快(均衡性能) | 極快(大寬表聚合最優,SIMD 深度優化) |
多表關聯性能 | 最優(支持多種 JOIN 策略) | 良好(依賴 CBO 優化) | 較弱(需預計算寬表) |
實時寫入能力 | 支持秒級更新(主鍵模型) | 支持實時導入(Kafka/Flink) | 僅批量寫入,更新需替換分區 |
并發能力 | 高并發(千級 QPS) | 中高并發(百級 QPS) | 低并發(單查詢資源消耗高) |
數據壓縮率 | 高(列式壓縮) | 高(類似 StarRocks) | 最高(列式壓縮優化) |
- 單表性能:ClickHouse > StarRocks > Doris
- 多表關聯:StarRocks > Doris > ClickHouse
- 實時性:StarRocks ≈ Doris > ClickHouse
- 高并發場景:StarRocks > Doris > ClickHouse
通過對比可知,在計算引擎采用SparkSQL支持大規模的ETL且結合目前58云窗大數據平臺的現有功能支持,實現成本和上手成本較低,也為后面數據增長預留支撐,所以選擇SparkSQL。
在OLAP引擎方面,StarRocks/Doris在多表關聯的查詢性能及并發能力顯著優于ClickHouse。從多表關聯查詢能力以及后期擴展性上我們考慮使用StarRocks。
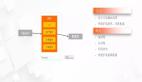
3.3 數倉體系架構圖
基于上述選型,以及結合轉轉數倉規范,構建了如下架構。
 轉轉數倉架構體系
轉轉數倉架構體系
 財報整體架構圖
財報整體架構圖
3.4 數據處理示例
在數據倉庫環境中,使用SparkSQL替代Java服務調用的計算邏輯,可以通過以下方式實現:
基礎訂單金額計算(單表)
-- 直接基于訂單事實表計算
SELECT
order_id,
original_amount,
shipping_fee,
original_amount + shipping_fee AS total_amount
FROM dwd_order_detail
WHERE dt = '${biz_date}'多維度關聯計算(替代Java服務調用)
-- 替代原Java的多服務調用邏輯
SELECT
o.order_id,
o.original_amount,
-- 用戶維度關聯計算
CASE
WHEN u.vip_level = 'PLATINUM' THEN o.original_amount * 0.9
ELSE o.original_amount
END AS vip_adjusted_amount,
-- 優惠券維度關聯計算
COALESCE(c.coupon_amount, 0) AS coupon_deduction,
-- 最終實付金額
(o.original_amount + o.shipping_fee - COALESCE(c.coupon_amount, 0)) AS final_amount
FROM dwd_order_detail o
LEFT JOIN dim_user u ON o.user_id = u.user_id AND u.dt = '${biz_date}'
LEFT JOIN dim_coupon c ON o.coupon_id = c.coupon_id AND c.dt = '${biz_date}'
WHERE o.dt = '${biz_date}'高級分析場景(窗口函數等)
-- 計算用戶最近3單平均金額(替代Java內存計算)
SELECT
order_id,
user_id,
amount,
AVG(amount) OVER (
PARTITION BY user_id
ORDER BY create_time
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS moving_avg_amount
FROM dwd_order_detail
WHERE dt BETWEEN date_sub('${biz_date}', 30) AND '${biz_date}'使用UDF封裝復雜邏輯
-- 注冊UDF
spark.udf.register("calculate_tax", (amount DECIMAL) -> {...});
-- SQL調用
SELECT order_id, calculate_tax(amount) FROM orders關鍵轉換邏輯對比:
Java代碼場景 | SparkSQL等效方案 | 優勢對比 |
多服務RPC調用 | 多表JOIN | 減少網絡開銷,性能提升10x+ |
內存中計算聚合 | GROUP BY/窗口函數 | 分布式計算,無OOM風險 |
循環處理業務邏輯 | CASE WHEN表達式鏈 | 向量化執行,效率更高 |
異常處理try-catch | COALESCE/NULLIF等函數 | 聲明式編程更簡潔 |
3.5 過程中遇到的一些問題
1. 數據一致性問題
例如某次財報分析發現:銷售部門的GMV數據與財務系統存在部分差異,追溯發現:
- 銷售部門使用訂單創建時間統計。
- 財務系統使用支付成功時間統計(凌晨創建的訂單若在次日支付,會導致日期差異)。
解決方案
- 統一統計口徑:協調各部門拉齊統計口徑。
- 校驗機制:每日跑批對比關鍵指標差異率。
2. 數據傾斜問題
大促期間,某個爆款的標品(例如SKU=888,充電器)的出庫單量占總量比例比較大,屬于熱點數據。導致Spark任務卡在最后一個Reducer,拖慢了整體進度。
2.1 原始SQL(存在傾斜)
-- 直接Join導致sku=888的數據全部進入同一個Reducer
SELECT
a.order_id,
b.sku_name,
SUM(a.quantity) AS total_qty
FROM fact_orders a
JOIN dim_sku b ON a.sku_id = b.sku_id
GROUP BY a.order_id, b.sku_name;解決方案
2.2 優化后SQL(解決傾斜)
步驟1:對傾斜鍵添加隨機后綴
-- 對事實表中的傾斜sku添加隨機后綴(0-99)
WITH skewed_data AS (
SELECT
order_id,
CASE
WHEN sku_id = '888' THEN
CONCAT(sku_id, '_', CAST(FLOOR(RAND() * 100) AS INT)
ELSE
sku_id
END AS skewed_sku_id,
quantity
FROM fact_orders
),
-- 維度表復制多份(與后綴范圍匹配)
expanded_dim AS (
SELECT
sku_id,
sku_name,
pos
FROM dim_sku
LATERAL VIEW EXPLODE(ARRAY_RANGE(0, 100)) t AS pos
WHERE sku_id = '888'
UNION ALL
SELECT
sku_id,
sku_name,
NULL AS pos
FROM dim_sku
WHERE sku_id != '888'
)步驟2:關聯計算
-- 關聯時匹配后綴
SELECT
a.order_id,
COALESCE(b.sku_name, c.sku_name) AS sku_name,
SUM(a.quantity) AS total_qty
FROM skewed_data a
LEFT JOIN expanded_dim b
ON a.skewed_sku_id = CONCAT(b.sku_id, '_', b.pos)
AND b.sku_id = '888'
LEFT JOIN dim_sku c
ON a.skewed_sku_id = c.sku_id
AND c.sku_id != '888'
GROUP BY a.order_id, COALESCE(b.sku_name, c.sku_name);2.3 執行過程對比
階段 | 優化前 | 優化后 |
Shuffle前 |
全部進入同一分區 |
分散到100個分區(888_0 ~ 888_99) |
Join操作 | 單節點處理所有 | 多節點并行處理子分區 |
結果合并 | 無需合并 | 通過 |
通過這種優化,我們在實際生產中成功將作業任務從 3小時 縮短到 25分鐘,關鍵點在于:將傾斜數據的計算壓力分散到多個節點,最后合并結果。
3.6 架構對比成果
維度 | 微服務架構問題 | 大數據架構解決方案 | 改進效果 |
RPC穩定性 | 頻繁超時,影響線上穩定性 | 完全消除RPC,批處理模式 | 故障率接近于0 |
任務可靠性 | 人工干預多,成功率92% | 自動化調度,成功率99.8% | 運維人力減少75% |
數據準確性 | 差異率最高10% | 統一加工邏輯,準確率99.9%+ | 質量大幅提升 |
處理能力 | 單機瓶頸,最大延遲6小時 | 分布式計算,任務量提升5倍 | 擴展性顯著增強 |
重跑效率 | 需4小時+,產生大量碎片 | 30分鐘內完成,insert overwrite模式 | 效率提升87.5% |
未來展望
當前的離線數倉架構很好地解決了T+1場景下的財報需求,但隨著業務發展,我們對實時財報也提出了更高要求。下一步計劃:
- Lambda架構:批流結合,在保持離線處理可靠性的同時增加實時處理能力。
- 技術棧升級:引入Flink實現流式計算,Kudu提供實時分析能力。
- 服務質量保障:借鑒微服務架構中的熔斷降級理念,如Sentinel提供的“錯誤率監控+人工干預+主動告警”機制,確保實時管道的穩定性。
- 擴充財報數據接入范圍: 結合數據中臺的理念,囊括整個集團財務毛利、費用相關財務指標。為后續做預測分析打好基礎,提升整體項目價值。
結語
轉轉敏捷財報架構演進過程印證了一個核心理念:沒有最好的架構,只有最適合的架構。從微服務到大數據的轉型不是簡單的技術替換,而是根據業務發展階段做出的理性選擇。希望我們的實踐經驗能為面臨類似挑戰的團隊提供參考。
最后,在這里想起蘇格拉底說過的一句話:我唯一知道的就是我一無所知。 學得越多,越能察覺過去的局限,從而以更成熟的視角輕松解決曾困擾自己的問題。
關于作者:廖儒豪。轉轉交易中臺研發工程師