













揭秘華為云DLI背后的核心計算引擎
本文主要給大家介紹隱藏在華為云EI(企業智能)數據湖探索服務(以下簡稱DLI)背后的核心計算引擎——Spark。華為云EI數據湖探索服務團隊在Spark之上做了大量的性能優化與服務化改造,但其本質還是脫離不了Spark的核心概念與思想,本文從以下幾點闡述,讓讀者快速對Spark有一個直觀的認識,玩轉DLI。
Spark的誕生及優勢
2009年,Spark誕生于伯克利大學AMPLab,誕生之初是屬于伯克利大學的研究性項目。于2010年開源,2013年成為Apache開源項目,經過幾年的發展逐漸取代了Hadoop,成為了開源社區炙手可熱的大數據處理平臺。
Spark官方的解釋:“Spark是用于大規模數據處理的統一分析引擎“,把關鍵詞拆開來看,“大規模數據”指的是Spark的使用場景是大數據場景;“統一”主要體現在將大數據的編程模型進行了歸一化,同時滿足多種類型的大數據處理場景(批處理、流處理、機器學習等),降低學習和維護不同大數據引擎的成本;“分析引擎”表明Spark聚焦在計算分析,對標的是Hadoop中的MapReduce,對其模型進行優化與擴展。
Spark為了解決MapReduce模型的優化和擴展,我們先探討一下MapReduce存在的問題,然后分析Spark在MapReduce之上的改進。
(1)MapReduce中間結果落盤,計算效率低下
隨著業務數據不斷增多,業務邏輯不斷多樣化,很多ETL和數據預處理的工作需要多個MapReduce作業才能完成,但是MapReduce作業之間的數據交換需要通過寫入外部存儲才能完成,這樣會導致頻繁地磁盤讀寫,降低作業執行效率。
Spark設計之初,就想要解決頻繁落盤問題。Spark只在需要交換數據的Shuffle階段(Shuffle中文翻譯為“洗牌”,需要Shuffle的關鍵性原因是某種具有共同特征的數據需要最終匯聚到一個計算節點上進行計算)才會寫磁盤,其它階段,數據都是按流式的方式進行并行處理。
(2)編程模型單一,場景表達能力有限
MapReduce模型只有Map和Reduce兩個算子,計算場景的表達能力有限,這會導致用戶在編寫復雜的邏輯(例如join)時,需要自己寫關聯的邏輯,如果邏輯寫得不夠高效,還會影響性能。
與MapReduce不同,Spark將所有的邏輯業務流程都抽象成是對數據集合的操作,并提供了豐富的操作算子,如:join、sortBy、groupByKey等,用戶只需要像編寫單機程序一樣去編寫分布式程序,而不用關心底層Spark是如何將對數據集合的操作轉換成分布式并行計算任務,極大的簡化了編程模型
Spark的核心概念
Spark中最核心的概念是RDD(Resilient Distributed Dataset) - 彈性分布式數據集,顧名思義,它是一個邏輯上統一、物理上分布的數據集合,Spark通過對RDD的一系列轉換操作來表達業務邏輯流程,就像數學中對一個向量的一系列函數轉換。Spark通過RDD的轉換依賴關系生成對任務的調度執行的有向無環圖,并通過任務調度器將任務提交到計算節點上執行,任務的劃分與調度是對業務邏輯透明的,極大的簡化了分布式編程模型,RDD也豐富了分布式并行計算的表達能力。
RDD上的操作分為Transformation算子和Action算子。Transformation算子用于編寫數據的變換過程,是指邏輯上組成變換過程。Action算子放在程序的***一步,用于對結果進行操作,例如:將結果匯總到Driver端(collect)、將結果輸出到HDFS(saveAsTextFile)等,這一步會真正地觸發執行。
常見的Transformation算子包括:map、filter、groupByKey、join等,這里面又可以分為Shuffle算子和非Shuffle算子,Shuffle算子是指處理過程需要對數據進行重新分布的算子,如:groupByKey、join、sortBy等。常見的Action算子如:count、collect、saveAsTextFile等
如下是使用Spark編程模型編寫經典的WordCount程序:

圖說:該程序通過RDD的算子對文本進行拆分、統計、匯總與輸出
Spark程序中涉及到幾個概念,Application、Job、Stage、Task。每一個用戶寫的程序對應于一個Application,每一個Action生成一個Job(默認包含一個Stage),每一個Shuffle算子生成一個新的Stage,每一個Stage中會有N個Task(N取決于數據量或用戶指定值)。
Spark的架構設計
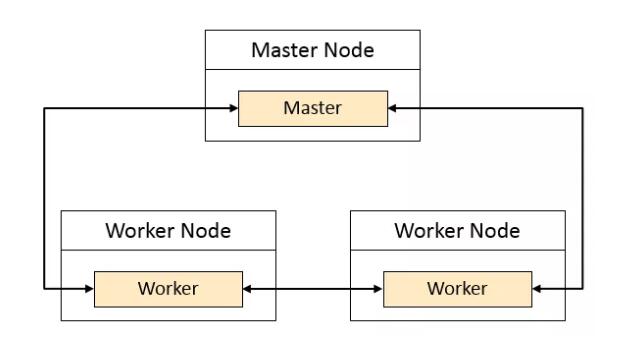
(注:橙色表示進程)
前面講述了Spark 核心邏輯概念,那么Spark的任務是如何運行在分布式計算環境的呢?接下來我們來看看開源框架Spark的架構設計。
Spark是典型的主從(Master- Worker)架構,Master 節點上常駐 Master守護進程,負責管理全部的 Worker 節點。Worker 節點上常駐 Worker 守護進程,負責與 Master 節點通信并管理 Executor。
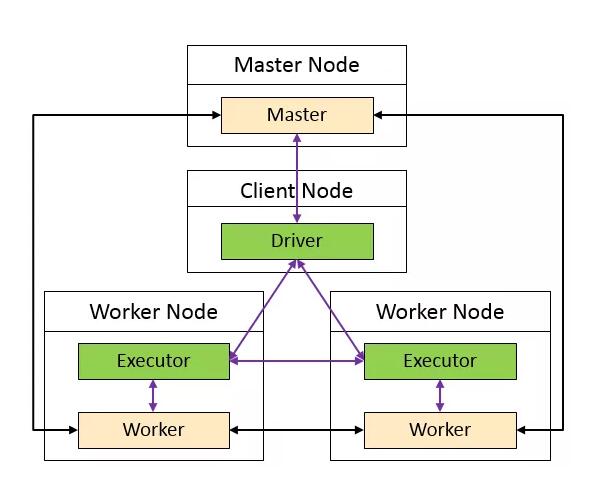
(注:橙色和綠色表示進程)
Spark程序在客戶端提交時,會在Application的進程中啟動一個Driver。看一下官方對Driver的解釋“The process running the main() function of the application and creating the SparkContext”。
我們可以把Master和Worker看成是生產部總部老大(負責全局統一調度資源、協調生產任務)和生產部分部部長(負責分配、上報分部的資源,接收總部的命令,協調員工執行任務),把Driver和Executor看成是項目經理(負責分配任務和管理任務進度)和普通員工(負責執行任務、向項目經理匯報任務執行進度)。
項目經理D to 總部老大M:Hi,老大,我剛接了一個大項目,需要你通知下面的分部部長W安排一些員工組成聯合工作小組。
總部老大M to 分部部長W:最近項目經理D接了一個大項目,你們幾個部長都安排幾個員工,跟項目經理D一起組成一個聯合工作小組。
分部部長W to 員工E:今天把大家叫到一起,是有個大項目需要各位配合項目經理D去一起完成,稍后會成立聯合工作小組,任務的分配和進度都直接匯報給項目經理D。
項目經理D to 員工E:從今天開始,我們會一起在這個聯合工作小組工作一段時間,希望我們好好配合,把項目做好。好,現在開始分配任務…
員工E to 項目經理D:你分配的xxx任務已完成,請分配其它任務。
項目所有任務都完成后,項目經理D to 總部老大M:Hi,老大,項目所有的任務都已經完成了,聯合工作小組可以解散了,感謝老大的支持。














