微博短視頻百萬級高可用、高并發架構如何設計?
本文從設計及服務可用性方面,詳細解析了微博短視頻高可用、高并發架構設計中的問題與解決方案。
今天與大家分享的是微博短視頻業務的高并發架構,具體內容分為如下三個方面:
- 團隊介紹
- 微博視頻業務場景
- “微博故事”業務場景架構設計
團隊介紹

我們是隸屬于微博研發部視頻平臺研發部門的技術團隊。平臺研發是微博的核心部門之一,包括大家熟知的微博視頻在內的微博所有核心業務的基礎平臺架構、用戶關系體系等都依賴微博平臺研發部門的技術支持。
我們的團隊主要負責與視頻相關的上層業務也就是視頻微博、“微博故事”以及短視頻和直播,其中直播包括常規的直播與直播答題等新玩法。
同時我們還負責底層視頻平臺的架構搭建,包括文件平臺、轉碼平臺、配置調度中心與媒體庫。
我們致力于用技術幫助微博從容應對每天***的視頻增量與其背后多項業務的多種定制化需求。
微博視頻業務場景

我們的業務場景主要是應對熱門事件的流量暴漲,例如明星緋聞、爆炸性新聞等勢必會讓流量在短時間內急劇增長的事件。
如何從架構上保證流量暴漲時整體平臺的穩定性?如果只是簡單地通過調整服務器規模解決,流量較小時過多的服務器冗余帶來成本的浪費,流量暴漲時過少的服務器又令平臺服務處于崩潰的邊緣。
比較特別的是,我們面臨的問題與諸如“雙十一”這種在某一確定時間段內流量的可預見式高并發有著本質的不同,我們面臨的流量暴漲是不可預見的。因此通過哪些技術手段來妥善解決以上問題,將是接下探討的重點。

以上是基于微博的過去已經公開數據量級,非近期內部數據。微博視頻是一個多業務接入的綜合平臺,你可以在微博上看見現在市面上的各種玩法。
這就導致我們即將面臨的并不是某個垂直業務領域的***,而是一個構建在龐大體量下的綜合性***,這就導致現有的通用技術框架無法妥善解決我們所面臨的難題。
因為一些開源方案無法順利通過技術壓測,所以我們只能在開源方案的基礎上進行自研與優化才能得到符合微博應用場景需求的技術解決方案。

微博的短視頻業務被稱為“微博故事”,上圖展示的是“微博故事”的展現形態。這是一個布置在微博首頁一級入口上的模塊,主要展示的是用戶關注的人所上傳的 15 秒內的短視頻。
我們希望強調其“即時互動”的屬性,視頻只有 24 小時的有效展示時間。不同用戶的視頻按照時間軸在上方排序,多個視頻可依次觀看、評論、點贊等。
“微博故事”業務場景架構設計
微服務架構

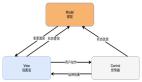
上圖展示的是這項業務的微服務架構:在接口層我們混布了 Web API 與內部的 RPC 請求。
在這里我們并未集成具有實際意義的門面層,而接下來的服務層集成了許多微服務,每個微服務集中在一個垂直功能上并可對外提供接口,這里的門面層主要作用是聚合一些微服務并對外提供綜合性接口。
除此之外還有一些依賴服務例如用戶關注、也需要依賴于其他部門的 RPC 服務;***的存儲層則是集成了 Cache 與 db 的標準方案。
技術挑戰

有人曾問到:微博短視頻業務的高并發有多高?假設我關注了 500 名好友,如果有好友發布一個視頻就會在“微博故事”頭像列表上顯示一個彩圈用以提示我去觀看。
如果我想知道自己所有關注的 500 個人所發的視頻內容,假設首頁每秒刷新十萬次,那么需要每秒鐘五千萬的 QPS。
除此之外我們還需要確定視頻是否過期、視頻發送順序等,實際的資源層讀取量將遠遠高于五千萬。
方案比較

在構建解決方案時我們思考:可以借鑒微博之前的 Feed 解決方案,我們不會進行無意義的重復性工作與思考。
即使短視頻與 Feed 都具有首頁刷新與關注人發布消息聚合的特點,但以用戶列表為形式,強調進度續播與即時互動的短視頻和以內容列表為形式,強調無閱讀狀態與***保存的微博具有本質的區別。
面對一般的 Feed 應用場景可以使用以下兩種模型:
- Feed 推模型
- Feed 拉模型
①Feed 推模型

Feed 推模型是指將用戶上傳發布的內容推送至每一位粉絲,這種方案具有很大的弊端。由于用戶尚未達成一定規模,早期的微博以 Feed 推模型為主導。
而現在一個大 V 用戶的粉絲數量普遍都是***別,如果依舊使用 Feed 推模型則意味著千萬量級的內容推送,在難以保證千萬份推送一致性的情況下,勢必會為服務器帶來巨大壓力。
微博的業務強調的就是強時效性下的內容一致性,我們需要確保熱點事件推送的瞬時與一致。
除了從技術層面很難確保***別內容推送的時效性與一致性,由于用戶上線狀態的不統一,為離線的用戶推送強時效性的內容無疑是對服務器等資源的巨大浪費,為了避免以上麻煩我們必須改變思路。
②Feed 拉模型


Feed 拉模型:拉取關注的人并實時查詢狀態及內容。綜合微博的龐大用戶體量、數據寫入開銷與確保一致性三方面,我們決定選擇 Feed 拉模型。

如何通過 Feed 拉模型應對如此規模龐大的 QPS?首先我們采用了分布式緩存架構,在緩存層集成了數據分片并將緩存通過哈希算法合理分片,之后再把緩存去切片化并進行存取。
分布式緩存架構

其次我們使用了獨有的多級緩存方案也就是 L1、 Master 、Slave 三層緩存方案。
L1 是一個熱度極高容量極小的緩存,我們稱其為“極熱緩存”,其特點是便于橫向擴展。
假設 L1 只有 200MB 緩存,我們使用 LRU 算法通過熱度分析把訪問最熱的數據存儲在 L1 中;之后的 Master 與 Slave 的緩存空間則是 4GB、6GB,比 L1 大很多倍。
因為微博的流量比較集中于熱點事件中某幾位明星或某個新聞,小容量的 L1 可進行快速擴容;在發生熱門事件時利用云的彈性自動擴容從而分擔熱點事件短時間激增的流量壓力。
由于自動擴容時 L1 僅占用每臺緩存中很小的空間,擴容的速度就會非常快,通過這種手動或自動的瞬間彈性擴容來確保服務器穩定承受熱點事件背后的數據激增量。
第二層的 Master 與 Slave 具有比 L1 大好多倍的緩存空間,主要用于防止數據冷穿。
雖然 L1 主要承擔的是熱點數據,但卻無法確保一些短時間內不熱但在某個時間段熱度突然高漲所帶來的流量短時間爆發時服務器的穩定性。
HA 多機房部署

而 Master 與 Slave 作為 L1 的邏輯分組可有效防止數據過冷,在這里我們采用的是 HA 多機房部署。
例如圖中的的兩臺 IDC,我們稱左邊為 IDC-A,右邊為 IDC-B。緩存層的 Master 與 Slave 是主從同步的關系,雙機房的緩存互相主從同步。
這里的“互相主從同步”是指 IDC-A 的 MC 與 IDC-B 的 MC 之間進行雙向同步互為主從。
因為在進行雙機房部署時需要均衡兩個機房的流量負載,在緩存層需要使用 LRU 算法進行熱度分析。
如果我們將流量分為兩份并傳輸至兩個機房,通過每個機房的 IRU 算法得到的熱度信息有一定失真。
如果我們在緩存層做相互同步后每個機房的 MC 都是一個全量的熱度算法,那么兩個機房的 L1 基本可實現同步計算得出的熱度信息一定是準確的,只有保證熱度信息的準確無誤才能從容應對流量激增與整個系統的高可用性。
在這里需要強調的是,實際上我們在選型上使用的是 MC 而未使用 Redis。
MC 對于純簡單數據 Key,Value 的抗量遠大于 Redis;MC 采用預分配內存的形式放置 Key,Value,也就是把內存分成若干組相同數據區域,實際上就是若干個數組。
這種特殊結構使其在數據定位數組尋址與讀寫上的速度非常快;這種結構的缺點是:一旦緩存的數據出現變動就會出現即使內存留有空余但數據依舊無法存儲的現象。
由于這種問題的存在,MC 不適用于存儲變動大、Value 跨度大、業務多變的數據。
而 Redis 作為單線程方案,一致性更好,但在超大規模簡單 Key,Value 讀取上速度比 MC 是要差很多的。

除了上述方案之外,我們還采用了彈性擴縮容。實際應用中,基于成本的考量我們無法部署大量的服務器,于是我們采用了自研的 DCP 彈性擴縮容平臺。
首先,我們的自有機房有一些共享機器資源可在特殊情況下動態彈性擴充以應對增加的流量壓力。
當然,這部分機器的性能是有限的,當數據量超過一定閾值后我們就會接入阿里云并利用我們與阿里云的混合云 DCP 方式構建一層彈性軟平臺用于自動擴容承擔流量壓力。
除了彈性擴容我們同時也采用了定時擴容的邏輯,在每天晚高峰時段進行擴縮容從而確保整體服務的穩定性。之所以這么做,主要是為了在保證用戶體驗的前提下盡可能節約成本。

需要強調的是,擴容對速度的要求十分嚴格。只有擴容的速度越快,流量峰值來臨時可承受的數據量越大,才能確保整體服務的高可用,因而我們也在努力優化擴容的速度。
我們的 DCP 平臺上也有晚高峰固定時段擴縮容與突發流量臨時擴縮容,通過如流量監控等的自動化容量評估來判斷服務器荷載,并通過自動化任務調度妥善解決突發流量對服務器的影響。
微服務熔斷機制

當然,為了保證服務器整體的健康與穩定,我們也在其中集成了微服務熔斷機制,其原理類似于家用電表中的保險絲,可在過載的情況下迅速自動熔斷。
系統會定期進行自我評估并確定每個服務的***荷載,假設將熔斷值定為 3000QPS,那么當 QPS 超過 3000、超時或異常時服務即會迅速熔斷并關閉,從而確保其他資源的安全穩定。
通過這種框架級、細粒度的自動降級機制,系統失敗隔離能力可被有效提高,避免了雪崩式的鏈式宕機事件的發生。在熔斷的同時,自動擴容也會同步運行。
熔斷之后系統會不斷更新服務流量荷載,一旦擴容完成或者服務還能繼續承受流量即可重新恢復工作,這種熔斷機制同樣也是為服務器擴容爭取時間。