實踐 | 馬蜂窩實時計算平臺演進之路
MES 是馬蜂窩統一實時計算平臺,為各條業務線提供穩定、高效的實時數據計算和查詢服務。在整體設計方面,MES 借鑒了 Lambda 架構的思想。本篇文章,我們將從四個方面了解 MES:
1. 關于 Lambda 架構
2.MES 架構和原理
3.MES 優化歷程
4. 近期規劃
關于 Lambda 架構
Lambda 架構是由 Storm 作者 NathanMarz 根據自己在 Twitter 的分布式數據處理系統經驗,提出的一個實時大數據處理框架,具有高容錯、低延時和可擴展等特性。
Lambda 架構核心的思想主要可以歸納成兩點:
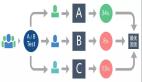
(1)數據從上游 MQ 消息中間件過來后分為 2 路,一路離線批處理, 一路實時處理并有各自的 View 以供查詢。
(2)Query 時,對數據做 Function, 結合 Batch View 和 Realtime View,得到最終結果。
具體來說,Lambda 架構將大數據系統架構為多個層次:批處理層(Batch layer)、實時處理層(Speed Layer)、服務層(Serving Layer)。
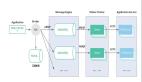
我們結合一張經典的 Lambda 架構圖分別來看:
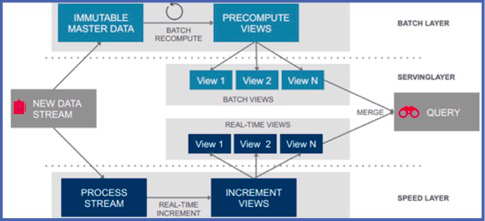
圖 1:Lambda 架構
(圖片來源:網絡)
批處理層(Batch Layer):批處理層承擔的任務是對從上游進來的所有被系統認為不可變的原始數據。類比目前的數據平臺架構來看, 即離線的那幾張保存原始數據的主表。這 3 張主表是所有完整的數據并且是不可變的,基于這幾張主表,數據經過 Batch 、ETL,產生供批處理查詢的 Batch View。
加速層(Speed Layer):批處理層雖然可以很好地處理離線數據,但它不能很好滿足對于時間粒度的需求。對于需要不斷實時生成和實時查詢處理的數據,通常會放在加速層來進行實時處理和轉化。
加速層與批處理層***的區別在于,加速層只處理最近的數據,而批處理層處理所有數據。另外在數據的讀取方面,為了滿足最小延遲,加速層不會在同一數據讀取所有新數據,而是在收到新數據時更新 Realtime View,所以我們說,在加速層進行的是一種增量的計算。
服務層(Serving Layer):服務層用于響應用戶的查詢請求,合并 Batch View 和 Realtime View 中的結果數據集到最終的數據集,并向外對用戶通過統一接口,提供實時+離線的數據統計服務。
基于 Lambda 的數據平臺架構, 可以按照分層集成眾多的大數據組件。在對 MES 的架構設計中,我們借鑒了 Lambda 架構的思想來實現更快、更準、魯棒性更好的特性。
馬蜂窩實時計算平臺 MES
為了保證 MES 實時計算平臺的性能,我們結合馬蜂窩的實際業務場景,主要圍繞低延遲,高吞吐、容災能力和 Exacty Once 的流式語義這四點,來進行架構設計和技術選型。
整體架構設計
對照 Lambda 架構,我們選用 Kafka 作為消息中間件,批處理層選擇 Hive、Presto,加速層也就是實時處理層選擇 Spark、Flink 等。
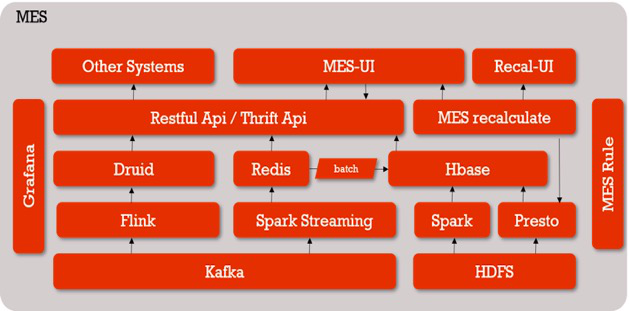
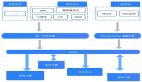
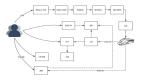
圖 2:MES 整體架構圖
數據從 Kafka 出來后走兩條線,一條是 Spark Streaming,支持秒級別的實時數據,計算結果會入庫到 Redis 里。第二天凌晨,Redis 中前一天的所有數據 Batch 到 HBase 中;
另外一條是 Flink+Druid,用來處理分鐘級和小時級的數據;
上面提供一層 Restful API / Thrift API 封裝,供 MES 頁面或其他業務通過接口的方式來獲取數據;
如果實時數據出了問題,我們會通過 HDFS 中的離線主表進行重算,也是有兩條路徑:
- 一是為用戶服務的 MES 重算系統,用戶可以自助化選取重算規則,提交重算任務。這個任務會被提交到 PrestoSQL 集群,計算結果最終落地到 HBase 里,重算后 MES 的歷史數據就會和離線數據算出來的數據保持一致;
- 另外一條線是 Spark 全量重算,由數據平臺的小伙伴內部使用,解決的是基于所有事件組、所有規則的全天數據重算。Spark 會讀取配置規則,重算所有前一天的數據后入庫到 HBase,保持實時數據和離線數據的一致性;
監控系統是 Grafana,它開放了通用接口給 Python、Java 等語言來上報相關信息,只要按照接口上報要想關注的指標并進行簡單配置,就可以查詢結果,比如 MES 的延遲時間、一些 Restful 接口的調用量等, 如果出現不正常的情況將通過郵件告警;
最右邊是貫穿始終的 MES 規則,我們可以抽象地把它看作是實時的配置流。
MES 實時計算引擎
1. 技術選型
結合馬蜂窩的業務需求,我們對三大主流實時計算引擎 Storm、Spark Streaming、Flink 進行了選型對比。
Storm
Storm 是***代流式計算引擎,實現了一個數據流 (Data Flow) 的模型。我們可以把它想象成一個發射點,一條一條產生數據,形成的數據流分布式地在集群上按照 Bolt 的計算邏輯進行轉換,完成計算、過濾等操作,在下游實現聚合。
Storm 的優勢是實時性好,可以達到毫秒級。但是它的吞吐量欠佳,并且只能為消息提供「至少一次」的處理機制, 這意味著可以保證每條消息都能被處理,但也可能發生重復。
Spark Streaming
Spark Streaming 不像 Storm 那樣一次一個地處理數據流,而是在處理前按時間間隔預先將其切分為一段一段,進行「微批次」處理作業。這樣一來解決了吞吐量的問題,但它的實時性就沒有 Storm 那么高,不過也可以達到秒級處理。
在流式語義方面,由于 Spark Streaming 容錯機制基于 RDD,依靠 CheckPoint,出錯之后會從該位置重新計算,不會導致重復計算。當然我們也可以自己來管理 offset,保證 Exactly Once (只算一次的語義) 的處理。
Flink
Flink 是新一代流式計算引擎,國內的阿里就是 Flink 的重度使用和貢獻者。Flink 是原生的流處理系統,把所有的數據都看成是流,認為批處理是流處理中的一種特殊情況。數據基于 Flink Stream Source 流入,中間經過 Operator,從 Sink 流出。
為了解決流處理的容錯問題,Flink 巧妙地運用了分布式快照的設計與可部分重發的數據源實現容錯。用戶可自定義對整個 Job 進行快照的時間間隔。當任務失敗時,Flink 會將整個 Job 恢復到最近一次快照,并從數據源重發快照之后的數據。Flink 同時保證了實時性和吞吐量,流式語義也做得非常好,能夠保證 Exactly Once。
在此之外,組件技術選型的時候在滿足自己業務現狀的同時, 還需要從以前幾個方面考慮:
- 開源組件是否能覆蓋需求
- 開源組件的擴展性和二次開發的難度
- 開源組件 API 是否穩定
- 開源組件是否有應用于生產環境的案例,比如多少公司應用于生產環境
- 開源組件社區是否活躍,比如可以看 github,issues,jiras 這些活躍程度
- 開源組件 License 限定問題
- 開源組件之間的耦合問題
2. 設計
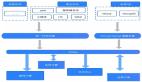
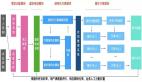
下圖描述了 MES 實時計算引擎處理數據的過程:
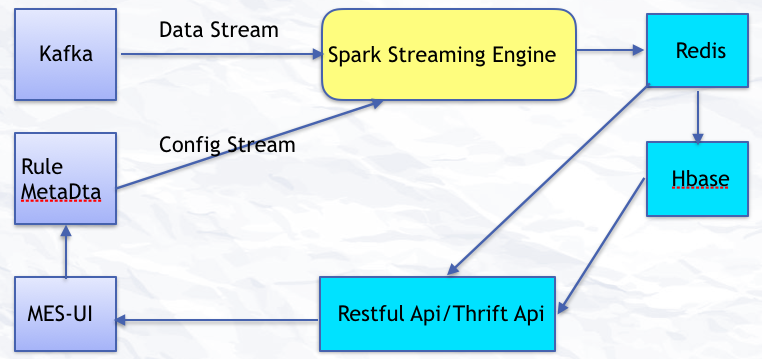
圖 3:MES Streaming
數據從 Kafka 源源不斷地過來形成數據流,用戶通過 UI 配置的一些規則形成實時配置流,數據流和配置流進入到實時計算引擎 Spark Streaming 后進行聚合計算。計算出的實時數據寫入到 Redis,歷史數據入庫到 HBase。UI 目前通過 Restful API 來獲取實時和歷史數據。
3. 演進
關于 MES 實時計算的引擎,我們主要經歷了兩次演進。
***代 :Spark Streaming + Redis + HBase
在設計***代 MES 時,我們希望可以支持秒級的計算,并且精確計算每一個用戶。所以在當時的現狀下,我們綜合考慮選擇了 Spark Streaming。
這個方案計算出來的 UV 是比較精確的。但它有自己的局限性:
首先,這一套架構用到的幾個組件其實對資源都比較依賴, 而且 SparkStreaming 對那種時不時的流量高峰的數據處理不是非常友好。數據先在 Spark Streaming 算好然后再入 Redis,***再入庫到 Hbase,數據鏈路比較長,不好維護。
另外,***代 MES 只支持自助配置規則,有了規則才會實時計算。所以對于比較自由的 OLAP 交叉分析不友好。而且如果由于集群不穩定等原因導致的任務失敗數據少算, 那么不管是用戶自助提交 Presto 還是利用 Spark 批處理全量重算,都是一個消耗集群資源的過程。由于批處理重算需要一定的時間來完成對歷史數據的修復,這對一些需要數據準確并及時提供的用戶不是非常友好。
我們考慮,在數據量大的情況下,我們是不是可以適當犧牲 UV 精準度的計算,來保障整個系統的性能和穩定性。所以就引入了 Flink + Druid。
第二代:引入 Flink + Druid
剛才我們已經簡單了解過 Flink,再來說下 Druid。
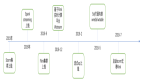
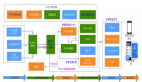
Druid 是一個大數據實時查詢和分析的高容錯、高性能的開源分布式系統,用來快速處理大規模的數據,它能夠實現對大量數據的快速查詢和分析,不足是存在一個 2% 的誤差。但事實上,在數據量非常大的情況下,2% 的誤差是可以接受的。后面我們又通過 Yahoo 提供的 Data Sketch,實現 UV 計算的精確調控,可以實現在 800w 之下的數據量,UV 都是準確的。最終的計算結果通過 restful 接口提供給 MES 獲取數據并展現。
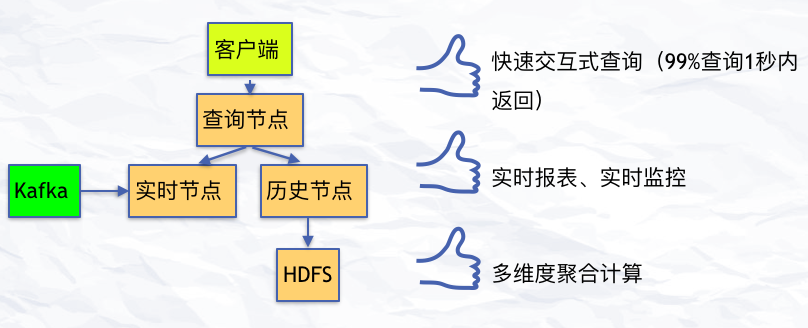
圖 4:關于 Druid
Flink + Druid 部分主要是用來處理數據量大、維度多,且不需要精確到秒級的業務數據,比如 Page logdata、mobile page、以及 Server Push。在最近 15 天的數據是可以精確到分鐘級別查詢的,對于歷史數據,粒度越精確,持久化到 Druid 里面的數據量就越大。
在離線批量導入部分,目前 Druid 支持小時級以及 T+1 天級的數據校正。因為如果在 Flink +Tranquility 實時攝取數據這一階段 task 有異常的話,會導致實時數據到 Druid 有丟失的情況出現。因此根據 Lambda 架構的思想,我們可以用小時級或者天級離線數據對丟失的數據進行重算補全。
對比一下兩代計算引擎,Flink + Druid 的引入很好地解決了因為大量數據的 UV 計算帶來的壓力:
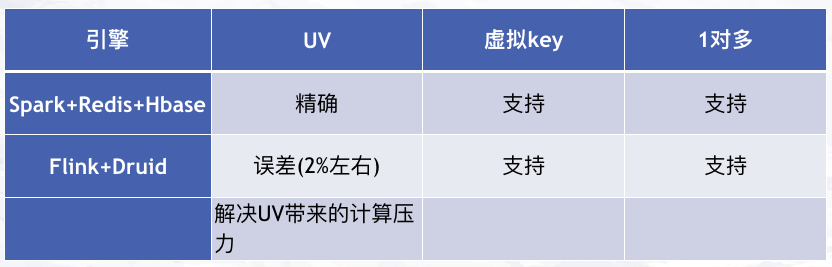
圖 5:兩代實時計算引擎
MES 優化歷程
為了更好地滿足業務需求,提升整個系統的性能,我們也在不斷對 MES 進行優化,主要包括實時計算集群、計算引擎、查詢接口和監控方面。這里主要和大家分享兩點。
1. 實時計算集群優化
- Spark,Druid,Flink 集群框架版本升級及相關參數優化;
- Redis,Hbase 節點擴容和參數優化;
- 集群網絡,Yarn,Mesos 等資源管理框架調整和優化
2. 實時計算引擎優化
數據結構和計算邏輯
對于 Spark 來講,Prefer 原生數據類型以及數組結構,對于指針類型以及嵌套的結構處理起來性能不是非常友好。因此要注意這一點,妥善優化自己的數據結構。
計算邏輯的部分也要考慮好。比如寫 Redis 的時候是事先規劃好要存入 Redis 中的數據結構來利用 Akka 并發每條來寫入,還是在 Streaming 中算好一批結果***來一次性寫入 Redis,這 2 種方式在性能上還是有很大區別的。
參數優化
(1) 序列化方式首先是 Kyro 的方式,其次才是 Java,序列化的方式不同對網絡的傳輸以及處理起來的性能是有影響的。
(2)Spark 推測執行機制。根據我們集群目前的現狀,有各種各樣的任務同時在跑,如果遇到集群資源使用高峰期,那么一個 Spark 任務落在比較慢的節點上就會拖累整個 Job 的執行進度。開啟推測執行之后,系統會把進程慢的任務主動殺死,然后重新產生一個相同的任務分配到資源充沛的節點上去快速完成它。
(3) 數據本地化。分布式計算有一個經典的理念是:移動數據不如移動計算。比如說我把一個任務分成很多并行的任務,有可能獲得的任務剛好需要處理的數據就在處理的節點上,也有可能不是。所以這里有一個本地化等待時間的參數可以控制數據本地化的處理等級并對性能產生很大影響。
另外還用一些關于并行度控制、JVM GC 方面的調優就比較細節了,如果大家感興趣可以留言給我們交流。
未來規劃
馬蜂窩實時計算平臺的發展還需要不斷探索,未來我們主要會在以下幾個方面重點推進:
1. 實時計算任務統一資源管理和任務調度
2. 支持復雜的實時 SQL OLAP 計算
3. 實時數據血緣關系及監控預警
4. 復雜實時 CEP 規則系統
本文作者:董良,馬蜂窩大數據平臺研發技術專家。2017 年加入馬蜂窩,現負責馬蜂窩實時計算平臺和數據中臺服務。2008 年畢業于西安郵電大學,曾在 Talend、神州專車等公司工作,先后從事數據集成中間件,數據倉庫,實時計算平臺等方向的研發工作。
感謝關注,歡迎大家掃描下方二維碼訂閱「馬蜂窩技術」內容并推薦給更多熱愛技術的朋友,希望有更多機會和大家交流。

【本文是51CTO專欄作者馬蜂窩技術的原創文章,作者微信公眾號馬蜂窩技術(ID:mfwtech)】