說出你的需求,我們AI給你寫代碼
說你想干什么,AI就能自動寫代碼。
現(xiàn)在,我們離這個目標(biāo)又近了一步。
近日,MIT的一個研究團(tuán)隊(duì)放出了新的研究成果。
他們提出了一種靈活組合模式識別和推理的方法,在無監(jiān)督學(xué)習(xí)的情況下, 來解決AI自動編程遇到的問題。
先給你看幾個例子:
任務(wù)要求:
給定一個數(shù)組,計算數(shù)字翻轉(zhuǎn)過來之后的中位數(shù)。
AI會給出代碼:
(reduce(reverse(digits(deref (sort a)(/ (len a) 2)))) 0
(lambda2 (+(* arg1 10) arg2)))
任務(wù)要求:
輸入:
1, [-101, 63, 64, 79, 119, 91, -56, 47, -74, -33]
4, [-6, -96, -45, 17, 26, -38, 17, -18, -112, -48]
輸出:
39
8
AI會給出的代碼:
(MAXIMUM (MAP DIV3 (DROP input0 input1)))
這是怎么做到的?
給人類程序員一個任務(wù),在開始寫代碼之前,會根據(jù)自己的經(jīng)驗(yàn)來判斷代碼架構(gòu)是什么樣的。如果沒有經(jīng)驗(yàn),就要采取推理的方式,來完善代碼架構(gòu)。
這個AI系統(tǒng),就是模仿了人類結(jié)合模式識別和推理寫代碼的方式。
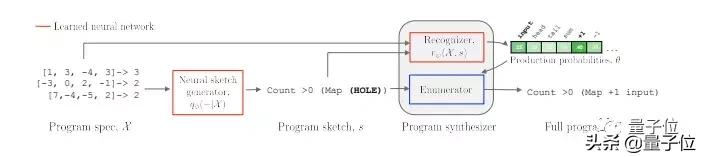
模型分為兩個模塊,分別是概要生成器(sketch generator)和代碼合成器( program synthesizer)。
輸入任務(wù)要求之后,先經(jīng)過概要生成器,生成滿足任務(wù)要求概率比較高的代碼概要,即可能滿足任務(wù)要求的初始代碼,細(xì)節(jié)并不豐富。然后,代碼概要進(jìn)入代碼合成器模塊,找到滿足任務(wù)要求的模塊。
概要生成器,是一個帶有注意力機(jī)制的seq2seq循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN),在給定任務(wù)之后,通過LSTM編碼器對其進(jìn)行編碼,然后再逐token解碼。
代碼合成器,有兩個組成部分:廣度優(yōu)先概率枚舉器和神經(jīng)網(wǎng)絡(luò)識別器。前者根據(jù)可能性從大到小枚舉代碼sketch, 后者根據(jù)任務(wù)要求來指導(dǎo)這一過程。
具體效果怎么樣?
為了驗(yàn)證模型的性能,研究團(tuán)隊(duì)選擇了兩個模型與其進(jìn)行對比。
分別是只有合成器的模型(Synthesizer only)和只有生成器的模型(Generator only)。
只有合成器的模型,相當(dāng)于研究中代碼合成器模塊,進(jìn)行模式識別之后,從頭開始枚舉所有可能的編碼。與微軟研究院研究團(tuán)隊(duì)2016年提出的“Deepcoder”模型媲美。
只有生成器的模型,相當(dāng)于研究中概要生成器模塊,用來預(yù)測完整的代碼。與微軟研究院和MIT團(tuán)隊(duì)在2017年提出的“RobustFill”模型媲美。
進(jìn)行對比的任務(wù)是數(shù)組列表、字符串轉(zhuǎn)換和自然語言要求。
在數(shù)組列表任務(wù)中,與其他兩項(xiàng)研究相比,研究中的模型可以在簡單的程序中呈現(xiàn)很好的性能。
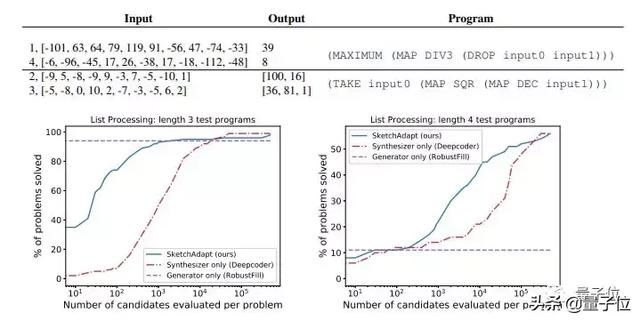
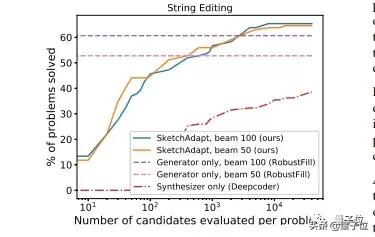
在字符串轉(zhuǎn)換任務(wù)中,表現(xiàn)要比只有合成器的模型要好,并且在一定情況下,會好于只有生成器的模型。
真正展現(xiàn)模型能力的,是在AlgoLisp數(shù)據(jù)集中進(jìn)行的測試,這一數(shù)據(jù)集中,不僅有數(shù)組列表和字符串相關(guān)的輸入輸出示例,還有相應(yīng)的自然語言描述。
在這個數(shù)據(jù)集上,研究者檢驗(yàn)了模型在非結(jié)構(gòu)化數(shù)據(jù)情況下的性能。
測試結(jié)果表明,模型的表現(xiàn)完全超過了先前學(xué)者的研究。
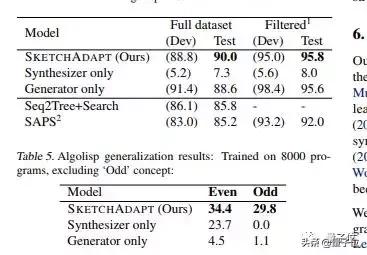
而且,在包含“Even”和“Odd”要求的情況下,性能更加突出了,表明了模型的通用性更強(qiáng)。
如果你對這個研究感興趣,可以閱讀論文,來獲取更多的研究細(xì)節(jié)。

傳送門:
Learning to Infer Program Sketches
https://arxiv.org/abs/1902.06349