你寫的代碼,是別人的噩夢嗎?
從業這么多年,接觸過銀行的應用,Apple的應用,eBay的應用和現在阿里的應用,雖然分屬于不同的公司,使用了不同的架構,但有一個共同點就是都很復雜。導致復雜性的原因有很多,如果從架構的層面看,主要有兩點,一個是架構設計過于復雜,層次太多能把人繞暈。另一個是根本就沒架構,ServiceImpl作為上帝類包攬一切,一桿捅到DAO(就簡單場景而言,這種Transaction Script也還湊合,至少實現上手都快),這種人為的復雜性導致系統越來越臃腫,越來越難維護,醬缸的老代碼發出一陣陣惡臭,新來的同學,往往要捂著鼻子摳幾天甚至幾個月,才能理清系統和業務脈絡,然后又一頭扎進各種bug fix,業務修補的惡性循環中,暗無天日!
CRM作為阿里最老的應用系統,自然也逃不過這樣的宿命。不甘如此的我們開始反思到底是什么造成了系統復雜性?我們到底能不能通過架構來治理這種復雜性?基于這個出發點,我們團隊開始了一段非常有意義的架構重構之旅(Redefine theArch),期間我們參考了SalesForce,TMF2.0,匯金和盒馬的架構,從他們那里汲取了很多有價值的輸入,再結合我們自己的思考最終形成了我們自己現在的基于擴展點+元數據+CQRS+DDD的應用架構。該架構的特點是可擴展性好,很好的貫徹了OO思想,有一套完整的規范標準,并采用了CQRS和領域建模技術,在很大程度上可以降低應用的復雜度。本文主要闡述了我們的思考過程和架構實現,希望能對在路上的你有所幫助。
復雜性來自哪里?
經過我們分析、討論,發現造成現在系統異常復雜的罪魁禍首主要來自以下四個方面:
可擴展性差
對于只有一個業務的簡單場景,并不需要擴展,問題也不突出,這也是為什么這個點經常被忽略的原因,因為我們大部分的系統都是從單一業務開始的。但是隨著支持的業務越來越多,代碼里面開始出現大量的if-else邏輯,這個時候代碼開始有壞味道,沒聞到的同學就這么繼續往上堆,聞到的同學會重構一下,但因為系統沒有統一的可擴展架構,重構的技法也各不相同,這種代碼的不一致性也是一種理解上的復雜度。久而久之,系統就變得復雜難維護。
像我們CRM應用,有N個業務方,每個業務方又有N個租戶,如果都要用if-else判斷業務差異,那簡直就是慘絕人寰。其實這種擴展點(ExtensionPoint),或者叫插件(Plug-in)的設計在架構設計中是非常普遍的。比較成功的案例有eclipse的plug-in機制,集團的TMF2.0架構。還有一個擴展性需求就是字段擴展,這一點對SaaS應用尤為重要,因為有很多客戶定制化需求,但是我們很多系統也沒有統一的字段擴展方案。
面向過程
是的,不管你承認與否,很多時候,我們都是操著面向對象的語言干著面向過程的勾當。面向對象不僅是一個語言,更是一種思維方式。在我們追逐云計算、深度學習、區塊鏈這些技術熱點的時候,靜下心來問問自己我們是不是真的掌握了OOD;在我們強調工程師要具備業務Sense,產品Sense,數據Sense,算法Sense,XXSense的時候,是不是忽略了對工程能力的要求。
據我觀察大部分工程師(包括我自己)的OO能力還遠沒有達到精通的程度,這種OO思想的缺乏主要體現在兩個方面,一個是很多同學不了解SOLID原則,不懂設計模式,不會畫UML圖,或者只是知道,但從來不會運用到實踐中;另一個是不會進行領域建模,關于領域建模爭論已經很多了,我的觀點是DDD很好,但不是銀彈,用和不用取決于場景。但不管怎樣,請你拋開偏見,好好的研讀一下EricEvans的《領域驅動設計》,如果有認知升級的感悟,恭喜你,你進階了。
我個人認為DDD***的好處是將業務語義顯現化,把原先晦澀難懂的業務算法邏輯,通過領域對象(Domain Object),統一語言(Ubiquitous Language)將領域概念清晰的顯性化表達出來。相信我,這種表達帶來的代碼可讀性的提升,會讓接手你代碼的人對你心懷感恩的。借用Abelson的一句話是
Programs must be written for people to read, and only incidentally for machines to execute.
所以強烈譴責那些不顧他人感受的編碼行為。
分層不合理
俗話說的好,All problemsin computer science can be solved by another level of indirection(計算機科學領域的任何問題都可以通過增加一個間接的中間層來解決),怎樣?是不是感受到間接層的強大了。分層***的好處就是分離關注點,讓每一層只解決該層關注的問題,從而將復雜的問題簡化,起到分而治之的作用。我們平時看到的MVC,pipeline,以及各種valve的模式,都是這個道理。
好吧,那是不是層次越多越好,越靈活呢。當然不是,就像我開篇說的,過多的層次不僅不能帶來好處,反而會增加系統的復雜性和降低系統性能。就拿ISO的網絡七層協議來說,你這個七層分的很清楚,很好,但也很繁瑣,四層就夠了嘛。再比如我前面提到的過度設計的例子,如果沒記錯的話應該是Apple的Directory Service應用,整個系統有7層之多,把什么validator,assembler都當成一個層次來對待,能不復雜么。所以分層太多和沒有分層都會導致系統復雜度的上升,因此我們的原則是不可以沒有分層,但是只分有必要的層。
隨心所欲
隨心所欲是因為缺少規范和約束。這個規范非常非常非常的重要(重要事情說三遍),但也是最容易被無視的點,其結果就是架構的consistency被嚴重破壞,代碼的可維護性將急劇下降,國將不國,架構將形同虛設。有同學會說不就是個naming的問題么,不就是個分包的問題么,不就是2個module還是3個module的問題么,只要功能能跑起來,這些問題都是小問題。是的,對于這些同學,我再丟給你一句名言“Just because you can, doesn't mean you should"。就拿package來說,它不僅僅是一個放一堆類的地方,更是一種表達機制,當你將一些類放到Package中時,相當于告訴下一位看到你設計的開發人員要把這些類放在一起考慮。
理想很豐滿,現實很骨感,規范的執行是個大問題,***能在架構層面進行約束,例如在我們架構中,擴展點必須以ExtPt結尾,擴展實現必須以Ext結尾,你不這么寫就會給你拋異常。但是架構的約束畢竟有限,更多的還是要靠Code Review,暫時沒想到什么更好的辦法。這種對架構約束的近似嚴苛follow,確保了系統的consistency,最終形成了一個規整的收納箱(如下圖所示),就像我和團隊說的,我們在評估代碼改動點時,應該可以像Hash查找一樣,直接定位到對應的module,對應的package里面對應的class。而不是到“一鍋粥”里去慢慢摳。

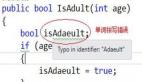
本章節***,上一張我們老系統中比較典型的代碼,也許你可以從中看到你自己應用的影子。
復雜性應對之道
知道了問題所在,接下來看下我們是如何一個個解決這些問題的。回頭站在山頂再看這些解決方案時,每個都不足為奇,但當你還“身在此山中”的時候,這個撥開層層迷霧,看到山的全貌的過程,并不是想象的那么容易。慶幸的是我團隊在艱難跋涉之后,終有所收獲。
1、擴展點設計
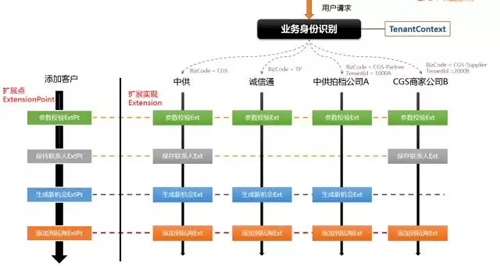
擴展點的設計思想主要得益于TMF2.0的啟發,其實這種設計思想也一直在用,但都是在局部的代碼重構和優化,比如基于Strategy Pattern的擴展,但是一直沒有找到一個很好的固化到框架中的方法。直到毗盧到團隊分享,給了我們兩個關鍵的提示,一個是業務身份識別,用他的話說,如果當時TMF1.0如果有身份識別的話,就沒有TMF2.0什么事了;另一個是抽象的擴展點機制。
身份識別
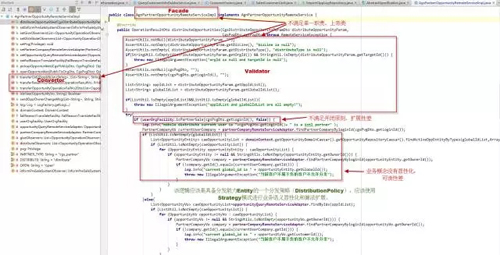
業務身份識別在我們的應用中非常重要,因為我們的CRM系統要服務不同的業務方,而且每個業務方又有多個租戶。比如中供銷售,中供拍檔,中供商家都是不同的業務方,而拍檔下的每個公司,中供商家下的每個供應商又是不同的租戶。所以傳統的基于多租戶(TenantId)的業務身份識別還不能滿足我們的要求,于是在此基礎上我們又引入了業務碼(BizCode)來標識業務。
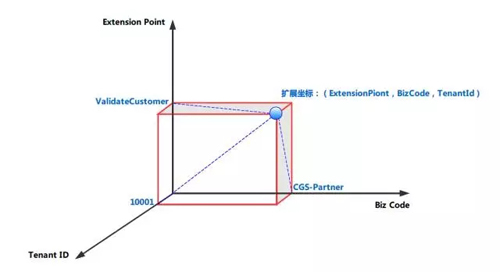
所以我們的業務身份實際上是(BizCode,TenantId)二元組。在每一個業務身份下面,又可以有多個擴展點(ExtensionPoint),所以一個擴展點實現(Extension)實際上是一個三維空間中的向量。借鑒Maven Coordinate的概念我給它起了個名字叫擴展坐標(Extension Coordinate),這個坐標可以用(ExtensionPoint,BizCode,TenantId)來唯一標識。
擴展點
擴展點的設計是這樣的,所有的擴展點(ExtensionPoint)必須通過接口申明,擴展實現(Extension)是通過Annotation的方式標注的,Extension里面使用BizCode和TenantId兩個屬性用來標識身份,框架的Bootstrap類會在Spring啟動的時候做類掃描,進行Extension注冊,在Runtime的時候,通過TenantContext來選擇要使用的Extension。TenantContext是通過Interceptor在調用業務邏輯之前進行初始化的。整個過程如下圖所示:
2、面向對象
領域建模
準確的說DDD不是一個架構,而是思想和方法論。所以在架構層面我們并沒有強制約束要使用DDD,但對于像我們這樣的復雜業務場景,我們強烈建議使用DDD代替事務腳本(TS: Transaction Script)。因為TS的貧血模式,里面只有數據結構,完全沒有對象(數據+行為)的概念,這也是為什么我們叫它是面向過程的原因。然而DDD是面向對象的,是一種知識豐富的設計(Knowledge Rich Design),怎么理解?,就是通過領域對象(Domain Object),領域語言(Ubiquitous Language)將核心的領域概念通過代碼的形式表達出來,從而增加代碼的可理解性。這里的領域核心不僅僅是業務里的“名詞”,所有的業務活動和規則如同實體一樣,都需要明確的表達出來。
例如前面典型代碼圖中所展示的,分配策略(DistributionPolicy)你把它隱藏在一堆業務邏輯中,沒有人知道它是干什么的,也不會把它當成一個重要的領域概念去重視。但是你把它抽出來,凸顯出來,給它一個合理的命名叫DistributionPolicy,后面的人一看就明白了,哦,這是一個分配策略,這樣理解和使用起來就容易的多了,添加新的策略也更方便,不需要改原來的代碼了。
所以說好的代碼不僅要讓程序員能讀懂,還要能讓領域專家也能讀懂。再比如在CRM領域中,公海和私海是非常重要領域概念,是用來做領地(Territory)劃分的,每個銷售人員只能銷售私海(自己領地)內的客戶,不能越界。但是在我們的代碼中卻沒有這兩個實體(Entity),也沒有相應的語言和其對應,這就導致了領域專家描述的,和我們日常溝通的,以及我們模型和代碼呈現的都是相互割裂的,沒有關聯性。這就給后面系統維護的同學造成了極大的困擾,因為所有關于公海私海的操作,都是散落著各處的repeat itself的邏輯代碼,導致看不懂也沒辦法維護。
所以當尚學把這兩個領域概念抽象成實體之后,整個模型和代碼都一下子變清晰很多。在加上上面介紹的把業務規則顯現化,極大的提升了代碼的可讀性和可擴展性。用尚學的話說,用DDD寫代碼,他找到了創作的感覺,而不僅僅是碼農式Coding。下圖是銷售域的簡要領域模型,但基本上能表達出銷售域的核心領域概念。
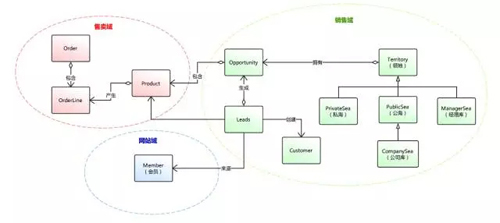
關于CQRS簡要說一下,我們只使用了Command,Query分離的概念,并沒有使用Event Sourcing,原因很簡單---不需要。關于Command的實現我們使用了命令模式,因此以前的ServiceImpl的職責就只是一個Facade,所有的處理邏輯都在CommandExecutor里面。
SOLID
SOLID是單一職責原則(SRP),開閉原則(OCP),里氏替換原則(LSP),接口隔離原則(ISP)和依賴倒置原則(DIP)的縮寫,原則是要比模式(Design Pattern)更基礎更重要的指導準則,是面向對象設計的Bible。深入理解后,會極大的提升我們的OOD能力和代碼質量。比如我在開篇提到的ServiceImpl上帝類的例子,很明顯就是違背了單一職責,你一個類把所有事情都做了,把不是你的功能也往自己身上攬,所以你的內聚性就會很差,內聚性差將導致代碼很難被復用,不能復用,只能復制(Repeat Yourself),其結果就是一團亂麻。

再比如在java應用中使用logger框架有很多選擇,什么log4j,logback,common logging等,每個logger的API和用法都稍有不同,有的需要用isLoggable()來進行預判斷以便提高性能,有的則不需要。對于要切換不同的logger框架的情形,就更是頭疼了,有可能要改動很多地方。產生這些不便的原因是我們直接依賴了logger框架,應用和框架的耦合性很高。
怎么破? 遵循下依賴倒置原則就能很容易解決,依賴倒置就是你不要直接依賴我,你和我都同時依賴一個接口(所以有時候也叫面向接口的編程),這樣我們之間就解耦了,依賴和被依賴方都可以自由改動了。
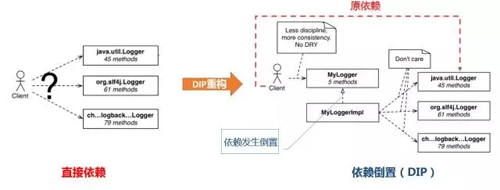
在我們的框架設計中,這種對SOLID的遵循也是隨處可見,Service Facade設計思想來自于單一職責SRP;擴展點設計符合關閉原則OCP;日志設計,以及Repository和Tunnel的交互就用到了依賴倒置DIP原則,這樣的點還有很多,就不一一枚舉了。當然了,SOLID不是OO的全部。抽象能力,設計模式,架構模式,UML,以及閱讀優秀框架源碼(我們的Command設計就是參考了Activiti的Command)也都很重要。只是SOLID更基礎,更重要,所以我在這里重點拿出來講一下,希望能得到大家的重視。
3、分層設計
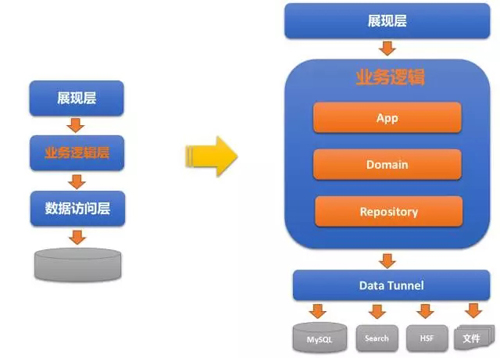
這一塊的設計比較直觀,整個應用層劃分為三個大的層次,分別是App層,Domain層和Repostiory層。
1.App層主要負責獲取輸入,組裝context,做輸入校驗,發送消息給領域層做業務處理,監聽確認消息,如果需要的話使用MetaQ進行消息通知;
2.Domain層主要是通過領域服務(Domain Service),領域對象(Domain Object)的交互,對上層提供業務邏輯的處理,然后調用下層Repository做持久化處理;
3.Repository層主要負責數據的CRUD操作,這里我們借用了盒馬的數據通道(Tunnel)的概念,通過Tunnel的抽象概念來屏蔽具體的數據來源,來源可以是MySQL,NoSql,Search,甚至是HSF等。
這里需要注意的是從其他系統獲取的數據是有界上下文(Bounded Context)下的數據,為了彌合Bounded Context下的語義Gap,通常有兩種方式,一個是用大領域(Big Domain)把兩邊的差異都合起來,另一個是增加防腐層(Anticorruption Layer)做轉換。什么是Bounded Context? 簡單闡述一下,就是我們的領域概念是有作用范圍的(Context)的,例如搖頭這個動作,在中國的Context下表示NO,但是在印度的Context下卻是YES。
4、規范設計
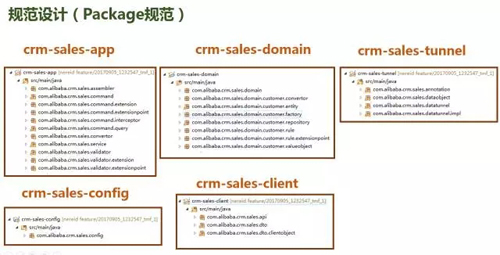
我們規范設計主要是要滿足收納原則的兩個約束:放對位置東西不要亂放,我們的每一個組件(Module),每一個包(Package)都有明確的職責定義和范圍,不可以放錯,例如extension包就只是用來放擴展實現的,不允許放其他東西,而Interceptor包就只是放攔截器的,validator包就只是放校驗器的。我們的主要構件如下圖所示:
貼好標簽
東西放在合適位置后還要貼上合適的標簽,也就是要按照規范合理命名,例如我們架構里面和數據有關的Object,主要有Client Object,Domain Object和Data Object,Client Object是放在二方庫中和外部交互使用的DTO,其命名必須以CO結尾,相應的Data Object主要是持久層使用的,命名必須以DO結尾。這個類名應該是自明的(self-evident),也就是看到類名就知道里面是干了什么事,這也就反向要求我們的類也必須是單一職責的(Single Responsibility)的,如果你做的事情不單純,自然也就很難自明了。如果我們Class Name是自明的,Package Name是自明的,Module Name也是自明的,那么我們整個應用系統就會很容易被理解,看起來就會很舒服,維護效率會提高很多。我們的命名規則如下圖所示:

GTS應用架構
經過上面的長篇大論,我希望我把我們的架構理念闡述清楚了,***再從整體上看下我們的架構吧。如果覺得不錯,也可以把framework code拉下來自己玩一下。
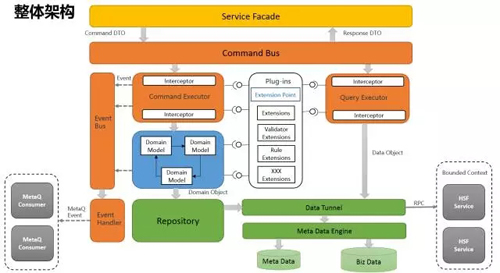
整體架構
我們的架構原則很簡單,即在高內聚,低耦合,可擴展,易理解大的指導思想下,盡可能的貫徹OO的設計思想和原則。我們最終形成的架構是集成了擴展點+元數據+CQRS+DDD的思想,關于元數據前面沒怎么提到,這里稍微說一下,對于字段擴展,簡單一點的解決方案就是預留擴展字段,復雜一點的就是使用元數據引擎。
使用元數據的好處是不僅能支持字段擴展,還提供了豐富的字段描述,等于是為以后的SaaS化配置提供了可能性,所以我們選擇了使用元數據引擎。和DDD一樣,元數據也是可選的,如果對沒有字段擴展的需求,就不要用。***的整體架構圖如下:
阿里高級技術專家Frank
【本文為51CTO專欄作者“阿里巴巴官方技術”原創稿件,轉載請聯系原作者】