做好基礎設施監控,防范意外停機
譯文
【51CTO.com快譯】基礎設施監控是基礎設施管理的一個組成部分。它是IT管理員防范意外停機的***道防線。嚴重的問題可能導致基礎設施出現大量停機時間,有時導致嚴重的經濟損失。
監控系統從你的基礎設施收集時間序列數據,以便對其進行分析,預測基礎設施及底層部件即將出現的問題。這使得IT管理員或支持人員有時間在問題發生之前準備并運用解決方案。
一套良好的監控系統具有以下功能:
1. 長期測量基礎設施的性能
2. 節點級分析和警報
3. 網絡級分析和警報
4. 停機分析和警報
5. 回答事件管理和根本原因分析(RCA)的五個W:
○實際問題是什么?
○什么時候發生的?
○為什么會發生?
○什么系統或部件出現停機?
○需要采取什么措施才能在將來避免?
建立強大的監控系統
有許多工具可以構建可行且強大的監控系統。唯一的決定是使用哪個工具;答案在于你希望通過監控實現的目標以及要考慮的各種財務和業務因素。
雖然一些監控工具是專有的,但許多開源工具(無人管理的軟件或社區管理的軟件)的效果甚至比閉源工具還好。
本文將介紹開源工具以及如何用它們來構建一套強大的監控架構。
日志收集和分析
日志大有幫助。日志不僅有助于調試問題,還提供了大量信息,幫助預測即將發生的問題。遇到軟件組件問題時,應首先分析日志。
Fluentd和Logstash都可用于收集日志;我選擇Fluentd而不是Logstash的唯一原因是因為它獨立于Java進程;它是用C + Ruby編寫的,得到Docker等容器運行時環境和Kubernetes等編排工具的廣泛支持。
日志分析是指分析逐漸收集的日志數據,并生成實時日志度量指標。Elasticsearch是這方面的一款強大工具。
***,你需要一個工具來收集日志度量指標,以便能夠使用易于理解的圖表和圖形直觀地顯示日志趨勢。Kibana是我在這方面所青睞的選擇。
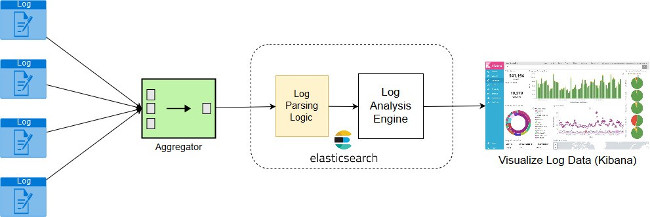
圖1. 日志工作流程
由于日志可能保存敏感信息,因此需要記住幾個安全要點:
•始終通過安全的連接傳輸日志。
•應在受限制的子網內實施日志/監控基礎設施。
•應僅限于利益相關者訪問監控用戶界面(比如Kibana和Grafana)。
節點級度量指標
并非一切都記入日志!
沒錯,日志監控的是軟件或進程,而不是基礎設施中的每個部件。
操作系統磁盤、外部掛載的數據磁盤、Elastic Block Store、CPU、I/O、網絡數據包、入站和出站連接、物理內存、虛擬內存、緩沖區空間和隊列是很少出現在日志中的一些主要部件,除非它們出了故障。
那么,如何收集這類數據呢?
Prometheus是個答案。你只需在虛擬機節點上安裝針對特定軟件的導出器,并配置Prometheus,從這些無人值守的部件收集基于時間的數據。Grafana使用Prometheus收集的數據來實時直觀地顯示節點的當前狀態。
如果你在尋找一個更簡單的解決方案來收集時間序列指標,不妨考慮Etricbeat,這是Elastic.io的內部開源工具,它可以與Kibana一起使用以取代Prometheus和Grafana。
警報和通知
沒有警報和通知,你就無法充分利用監控。除非利益相關者(無論他們人在哪里)接到有關問題的通知,否則他們就無法分析和解決問題、防止客戶受到影響并在將來避免它。
Prometheus使用其內部的Alertmanager和Grafana來創建預定義的警報規則,可以基于配置的規則發送警報。Sensu和Nagios是提供警報和監控服務的其他開源工具。
人們在開源警報工具方面遇到的唯一問題是,配置時間和過程有時看起來很費勁,但是一旦設置好,這些工具的效果比專有工具還好。
然而,開源工具的***優點是我們可以控制它們的行為。
監控工作流程和架構
良好的監控架構是強大而穩定的監控系統的支柱。它可能看起來像這個圖。
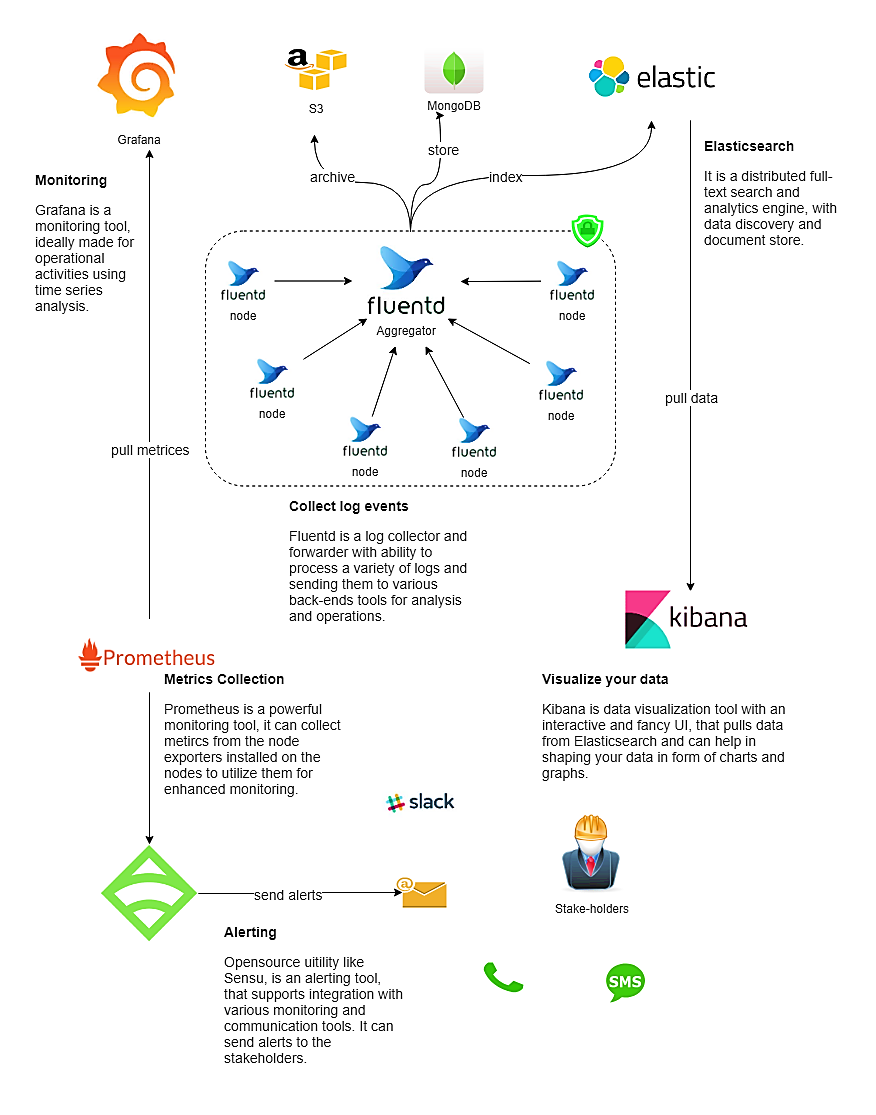
圖2. Devops監控架構
***,你要根據自己的需求和基礎設施來選擇工具。許多企業組織使用本文中討論的開源工具來監控基礎設施并確保正常運行時間很長。
原文標題:Infrastructure monitoring: Defense against surprise downtime,作者:Abhishek Tamrakar
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】