“老司機(jī)”劃重點(diǎn)!搞定這120個真實(shí)面試問題,殺進(jìn)數(shù)據(jù)科學(xué)圈
大數(shù)據(jù)文摘出品
來源:Github
編譯:陸震、張秋玥、蔣寶尚
直到今天,在各類媒體口中,數(shù)據(jù)科學(xué)家依然是“21世紀(jì)最性感的職業(yè)”。但事實(shí)上,希望進(jìn)入這個行業(yè)的初級數(shù)據(jù)科學(xué)家已經(jīng)供過于求。
可以預(yù)見的是,各種高校相關(guān)專業(yè)的畢業(yè)生,在完成coursera或者fast.ai的課程后,都希望得到一份跟“數(shù)據(jù)”相關(guān)的崗位。據(jù)統(tǒng)計(jì),部分職位的供求比已經(jīng)達(dá)到了1:200。
那么,如何能在這條獨(dú)木橋上殺出重圍、脫引而出呢?
金三銀四求職季,江湖傳言在三月份和四月份找工作和跳槽成功的概率很大。不同于程序員這樣的純技術(shù)工種,求職成為一名數(shù)據(jù)科學(xué)家似乎需要“上知天文,下知地理”。
畢竟,數(shù)據(jù)科學(xué)領(lǐng)域集成了多種不同元素,包括信號處理,數(shù)學(xué),概率模型技術(shù)和理論,機(jī)器學(xué)習(xí),計(jì)算機(jī)編程,統(tǒng)計(jì)學(xué),數(shù)據(jù)工程,模式識別和學(xué)習(xí),可視化,不確定性建模,數(shù)據(jù)倉庫,以及從數(shù)據(jù)中析取規(guī)律和產(chǎn)品的高性能計(jì)算。
今天文摘菌會給大家推薦一份數(shù)據(jù)科學(xué)面試資料,資料收集了來自技術(shù)公司的訪調(diào)員和數(shù)據(jù)科學(xué)家。從淺入深的囊括了溝通、數(shù)據(jù)分析、模型預(yù)測、編程、概率、產(chǎn)品指標(biāo)等7個部分的共120個面試問題。
根據(jù)官方網(wǎng)站,這份資源由Max、Carl、Henry以及William四位合作編寫,他們都有數(shù)學(xué)科學(xué)以及數(shù)據(jù)分析的背景,也非常互補(bǔ),也因此讓這份資料變得彌足珍貴。
這份資料,在官方網(wǎng)站上需要付19美元可以獲取完整版(包括問題和答案)。
先放上資料官網(wǎng),非常需要的讀者支持正版哦:
https://www.datasciencequestions.com/
當(dāng)然,如果你只是想了解這份資料的大概內(nèi)容,或者測試一下自己是否掌握了數(shù)據(jù)科學(xué)家需要的知識,文摘菌在github上也找到了這份資料的縮略問題版,少部分概念以及定義性的問題有答案,對于開放性的問題,歡迎大家在留言區(qū)給出你的答案哦。
文摘菌精選了這份資料中的部分問題和答案,完整版戳下邊鏈接自取。
github地址:
https://github.com/kojino/120-Data-Science-Interview-Questions
溝通

(1) 向我解釋一個與你正在面試的角色相關(guān)的技術(shù)概念。
(2) 向我介紹你所熱愛的事情。
(3) 你會如何向沒有統(tǒng)計(jì)背景的工程師解釋A/B測試,線性回歸呢?
A/B測試,也就是多變量測試,通過測試用戶的不同體驗(yàn),來確定哪種改變有助于企業(yè)更加有效地實(shí)現(xiàn)其目標(biāo)(如增加轉(zhuǎn)換等)。它可以是網(wǎng)站上的文本信息,按鈕的顏色,不同的用戶界面,不同的電子郵件主題行,號召性用語,優(yōu)惠等。
(4) 你會如何向沒有統(tǒng)計(jì)背景的工程師解釋置信區(qū)間以及95%的置信度的意思?
參考鏈接:https://www.quora.com/What-is-a-confidence-interval-in-laymans-terms
(5) 你會如何向一組高級管理人員解釋為什么數(shù)據(jù)很重要?
數(shù)據(jù)分析
據(jù)分析")
(1) 給定一個數(shù)據(jù)集,分析這個數(shù)據(jù)集并告訴我你可以從中了解到什。
(2) 什么是R2?可能比R2更好的指標(biāo)有哪些,為什么?
答:擬合良好,是由該回歸/總方差解釋的那部分方差;你添加的預(yù)測變量越多,R^2越大;因而使用因自由度調(diào)整的R ^ 2;或著訓(xùn)練誤差指標(biāo)。
(3) 什么是維度災(zāi)難?
- 高維度使得聚類變得困難,因?yàn)閾碛写罅烤S度意味著彼此相差很大。例如,為了覆蓋一小部分?jǐn)?shù)據(jù),隨著變量數(shù)量的增加,我們需要處理每個范圍廣泛的變量;
- 所有樣本都靠近樣本的邊緣。這非常糟糕,因?yàn)樵谟?xùn)練樣本的邊緣附近做出預(yù)測要更加困難;
- 隨著維度 p的增加,采樣密度呈指數(shù)下降,因此在沒有更多的數(shù)據(jù)量的情況下,該數(shù)據(jù)會變得更加稀疏;我們應(yīng)該進(jìn)行PCA分析以降低維度。
(4) 更多的數(shù)據(jù)就總是更好么?
從統(tǒng)計(jì)來說,它取決于你的數(shù)據(jù)的質(zhì)量,如果您的數(shù)據(jù)有偏差,獲取再多數(shù)據(jù)也毫無用處;它取決于你的模型。如果你的模型能夠承受高偏差,獲取更多數(shù)據(jù)不會太過明顯地提高你的測試結(jié)果。你需要添加更多特征,或者做別的處理。從實(shí)戰(zhàn)來說,也需要在擁有更多數(shù)據(jù)和額外存儲,計(jì)算能力以及所需內(nèi)存之間進(jìn)行權(quán)衡。因此,始終要考慮擁有更多數(shù)據(jù)的成本。
(5) 分析數(shù)據(jù)之前繪制圖表有什么好處?
數(shù)據(jù)集會有錯誤。你不會找到全部的錯誤,但你或許能夠找到其中的一些。比如那個212歲的男人以及那個9英尺高的女;變量會有偏度,異常值等。算術(shù)平均值可能用不了,這也意味著標(biāo)準(zhǔn)差用不了;變量可以是多峰的!如果變量是多峰的,那么任何基于其的均值或著中位數(shù)的都是可疑的。
模型預(yù)測(19個問題)
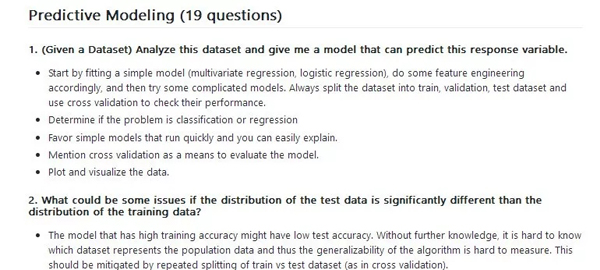
(1) 給定一個數(shù)據(jù)集,分析這個數(shù)據(jù)集并給出一個可以預(yù)測這個響應(yīng)變量的模型。
由擬合簡單的模型(多元回歸,邏輯回歸)開始,相應(yīng)地選取一些特征,然后嘗試一些復(fù)雜的模型。要始終將數(shù)據(jù)集拆分為訓(xùn)練集,驗(yàn)證集和測試集并使用交叉驗(yàn)證來觀察模型的表現(xiàn);確定問題是分類問題還是回歸問題;傾向于選用運(yùn)行快速可以輕松解釋的簡單模型;提及交叉驗(yàn)證作為評估模型的一種方法;繪制圖表且將數(shù)據(jù)可視化。
(2) 如果測試數(shù)據(jù)的分布與訓(xùn)練數(shù)據(jù)的分布明顯不同,可能會出現(xiàn)什么問題?
- 訓(xùn)練時具有高精度的模型在測試時可能具有較低的精度。在沒有進(jìn)一步了解的情況下,很難知道哪個數(shù)據(jù)集代表了總體的數(shù)據(jù),因而很難測量算法的泛化程度;
- 這應(yīng)該可以通過重復(fù)劃分訓(xùn)練集和測試集來緩解(如交叉驗(yàn)證);
- 當(dāng)數(shù)據(jù)分布發(fā)生變化時,稱為數(shù)據(jù)集漂移。 如果訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)的分布不同,分類器可能會過度擬合訓(xùn)練數(shù)據(jù)。
(3) 有什么方法可以讓我的模型對異常值的魯棒性更高?
我們可以使用L1或L2等正則化方法來減少方差(增加偏倚)。
- 算法的改變:1.使用基于樹的方法來代替回歸方法,因?yàn)樗鼈兏苋淌墚惓V怠?.對于統(tǒng)計(jì)檢驗(yàn),使用非參數(shù)檢驗(yàn)來代替參數(shù)檢驗(yàn)。3.使用穩(wěn)健的誤差指標(biāo),如MAE或Huber Loss,來代替MSE。
- 數(shù)據(jù)的改變:1.對數(shù)據(jù)進(jìn)行winsorize處理2.轉(zhuǎn)換數(shù)據(jù)(如進(jìn)行對數(shù)處理)3.只有在你確定它們是不值得預(yù)測的異常值時才刪除它們
(4) 與最小化誤差絕對值的模型相比,在最小化誤差平方的模型中,你認(rèn)為有哪些差異?每個誤差指標(biāo)分別在哪種情況下合適?
MSE對異常值更加嚴(yán)格。在這個意義上MAE魯棒性更好,但也更難以擬合模型,因?yàn)樗鼰o法在數(shù)值上進(jìn)行優(yōu)化。因此,當(dāng)模型的可變性較小且在計(jì)算上容易擬合時,我們應(yīng)該使用MAE,否則應(yīng)該使用MSE。
- MSE:更容易計(jì)算梯度
- MAE:計(jì)算梯度需要線性編程MAE對異常值更加穩(wěn)健。
如果較大錯誤造成的后果很嚴(yán)重,使用MSEMSE相當(dāng)于最大化高斯隨機(jī)變量的可能性。
(5) 你會什么誤差指標(biāo)來評估二分類器的好壞?如果類別不平衡怎么辦?如果超過2組怎么辦?
- 準(zhǔn)確性:你正確預(yù)測的情況的比例。優(yōu)點(diǎn):直觀,易于解釋,缺點(diǎn):當(dāng)類標(biāo)簽不平衡且數(shù)據(jù)信號較弱時效果不。
- AUROC:在x軸上繪制fpr,在y軸上繪制tpr以獲得不同的閾值。給定隨機(jī)正例和隨機(jī)負(fù)例,AUC是你能可以識別類別的概率。優(yōu)點(diǎn):在測試分類能力時效果很好,缺點(diǎn):不能將預(yù)測解釋為概率(因?yàn)锳UC由排名決定),因此無法解釋模型的不確定性。
- logloss/deviance:優(yōu)點(diǎn):基于概率的誤差度量,缺點(diǎn):對假陽性,假陰性非常敏感。當(dāng)有超過2組時,我們可以使用k個二分類并將它們添加到logloss中。 像AUC這樣的一些指標(biāo)僅適用于二分類情況。
概率

(1) 阿米巴蟲波波生0個、1個或2個小阿米巴蟲的概率分別是25%、25%以及50%。這些小阿米巴蟲們的繁殖能力也都一樣。請問波波的后代滅絕的概率是多少?
- p=1/4+1/4p+1/2p^2 => p=1/2
(2) 任何15分鐘時間段內(nèi),你看到至少一顆流星的概率是20%。請問在一小時內(nèi)你看到至少一顆流星的概率是多少?
- l 1-(0.8)^4。 或者我們用泊松過程也可以解。
(3) 僅使用一枚色子,你如何生成一個1-7內(nèi)隨機(jī)數(shù)?
- 丟三次色子:每一次丟的都是結(jié)果的第n位
- 每次丟色子時,如果值為1-3,則記錄0,否則記錄1。結(jié)果會位于0(000)與7(111)之間,均勻分布(因?yàn)檫@三次拋擲互相獨(dú)立)。如果得到0則重復(fù)拋擲:該過程會終止于均勻分布的值。
(4) 有一個數(shù)據(jù)集包含來自兩個正態(tài)分布的數(shù)值。兩個分布的標(biāo)準(zhǔn)差相同。來自兩個分布的數(shù)據(jù)點(diǎn)個數(shù)相同。請問如果想要該數(shù)據(jù)集呈雙峰分布,兩個分布的均值應(yīng)當(dāng)至少差多少?
- 多于兩個標(biāo)準(zhǔn)差
(5) 提供已知正態(tài)分布的樣本值,請問你能如何模擬一個均勻分布的樣本值?
- 將值代入同一隨機(jī)變量的累計(jì)分布函數(shù)
(6) 一對夫妻告訴你他們有兩個小孩,其中至少有一個是女孩。請問他們擁有兩個女兒的概率是多少?
- 1/3
產(chǎn)品指標(biāo)
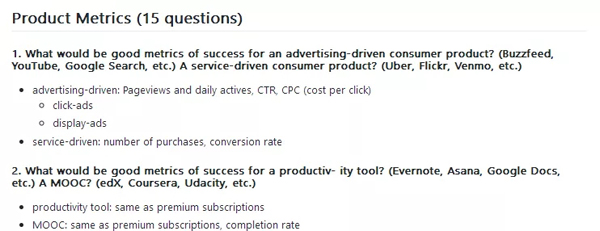
(1) 對于一個廣告驅(qū)動的消費(fèi)者產(chǎn)品(比如Buzzfeed,YouTube,Google搜索等),什么可以稱為好的成功衡量指標(biāo)?服務(wù)驅(qū)動的消費(fèi)者產(chǎn)品(比如優(yōu)步,F(xiàn)lickr,Venmo等)呢?
- 廣告驅(qū)動:頁面瀏覽量與每日活躍量,點(diǎn)擊率,每次點(diǎn)擊成本
- 服務(wù)驅(qū)動:購買量,轉(zhuǎn)化率
(2) 對于一個效率工具(比如印象筆記,Asana,Google文檔等),什么可以稱為好的成功衡量指標(biāo)?線上課程平臺(比如edX,Coursera,Udacity等)呢?
- 效率工具:付費(fèi)訂閱用戶數(shù)
- 線上課程平臺:付費(fèi)訂閱用戶數(shù),課程完成率
(3) 對于一個電商產(chǎn)品(比如Etsy,Groupon,Birchbox等),什么可以稱為好的成功衡量指標(biāo)?訂閱產(chǎn)品(比如Netflix,Birchbox,Hulu等)呢?高級付費(fèi)訂閱(比如OKCupid,領(lǐng)英,Spotify等)呢?
- 電商產(chǎn)品:購買量,轉(zhuǎn)化率,時/日/周/月/季/年銷售額,售出產(chǎn)品成本,存貨量,網(wǎng)站流量,凈回頭客量,客服電話量,平均解決問題時長
- 訂閱產(chǎn)品:流失量,(不知道接下來這幾個都是啥)
- 高級付費(fèi)訂閱:(無解答)
(4) 對于高度依賴于用戶投入與交互的消費(fèi)者產(chǎn)品(比如Snapchat,Pinterest,F(xiàn)acebook等),什么可以稱為好的成功衡量指標(biāo)?通訊產(chǎn)品(比如GroupMe,Hangouts,Snapchat等)呢?
- 高度依賴于用戶投入與交互的消費(fèi)者產(chǎn)品:user AU ratios,分類型郵件匯總,分類型推送通知匯總,復(fù)活率。
- 通訊產(chǎn)品:(無解答)
(5) 對于擁有app內(nèi)購服務(wù)的產(chǎn)品(比如Zynga,憤怒的小鳥以及許多其他游戲),什么可以稱為好的成功衡量指標(biāo)?
- 用戶/付費(fèi)用戶平均營收
編程(14題)

(1) 編寫一個函數(shù),計(jì)算2n個用戶所有可能分配向量,其中n個用戶為控制組,n個用戶為治療組。
- 遞歸編程
(2) 提供一個包含Twitter消息的列表,求十個最常用的的標(biāo)簽。
- 在字典中存儲所有標(biāo)簽然后求前十值
(3) 在給定時間內(nèi)寫出算法求解背包問題的理想近似解。
- 貪婪算法
(4) 在給定時間內(nèi)寫出算法求解旅行商問題的理想近似解。
- 貪婪算法
(5) 你將得到一個大小為n的數(shù)據(jù)集,但你無法提前知道n具體有多大。寫出一個占據(jù)O(k)的算法來隨機(jī)抽取k個元素。
- 水塘抽樣
統(tǒng)計(jì)推論(15題)
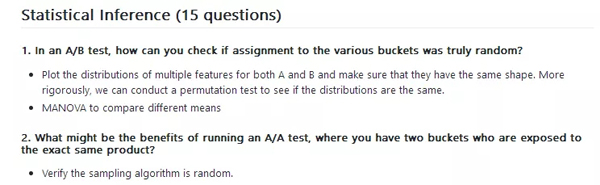
(1) AB測試中你如何確認(rèn)客戶流分組完全隨機(jī)?
- 畫出多個A組與B組變量的分布,確保他們都擁有一致的形狀。再保險一點(diǎn),我們可以做一個排列檢驗(yàn)來看分布是否相同。
- MANOVA來比較不同的均值。
(2) AA測試(兩組完全一致)的好處有什么?
- 檢查抽樣算法隨機(jī)性
(3) 在AB測試中,允許一組用戶知道另一組是什么樣子有什么危害?
- 用戶可能無法與未知其他選項(xiàng)時行為一致。實(shí)際上你是在添加一個關(guān)于是否允許用戶窺探其它選項(xiàng)的變量——該變量并不隨機(jī)。
(4) 如果某個博客報道了你的實(shí)驗(yàn)組會有什么影響呢?
- 與前問相同。這一問題可能會在更大范圍內(nèi)發(fā)生。
(5) 你如何設(shè)計(jì)一個允許用戶自行選擇是否加入的AB測試。
github地址:https://github.com/kojino/120-Data-Science-Interview-Questions
【本文是51CTO專欄機(jī)構(gòu)大數(shù)據(jù)文摘的原創(chuàng)譯文,微信公眾號“大數(shù)據(jù)文摘( id: BigDataDigest)”】