27場機器學習面試后,來劃個概念重點吧
機器學習面試寶典,有這一本就夠了。
在機器學習和數據科學崗位的面試中,機器學習領域的概念是經常考察的內容。一位近期經過 27 次 AI 領域面試(包括 Google 等大型公司和一些初創公司)的開發者根據自己的面試實戰經驗撰寫了一份機器學習資料。
這份資料適用于機器學習初學者,包含機器學習中經典常用的基礎概念。值得一提的是,每個章節的末尾還附帶教程和練習題,幫助讀者進一步掌握書中講解的概念知識。
下載地址:https://www.confetti.ai/assets/ml-primer/ml_primer.pdf
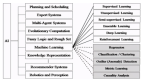
這本書包括監督學習、機器學習實踐、無監督學習和深度學習四章。
第一章:監督學習
該章節介紹了線性回歸、logistic 回歸、樸素貝葉斯、支持向量機、決策樹和 K - 近鄰算法。
線性回歸
線性回歸是最常見且使用范圍最廣的一種機器學習技術。它是一種非常直觀的監督學習算法。顧名思義,線性回歸是一種回歸方法,這意味著它適用于標簽是連續值(如室溫)的情況。此外,線性回歸試圖尋求與線性數據的擬合。
logistic 回歸
現實世界中絕大多數問題都涉及到分類,比如圖像標注、垃圾郵件檢測、預測明天是否為晴天等。這里介紹的第一個分類算法是 logistic 回歸。
樸素貝葉斯
樸素貝葉斯是一種優秀的機器學習模型。它之所以優秀,是因為它的核心假設可以用一句話來描述,但它在許多問題中都很有效。在深入了解樸素貝葉斯之前,這里首先探討了判別模型和生成模型這兩種機器學習模型的區別。
支持向量機
這部分探討了支持向量機這種分類算法。21 世紀初深度學習興起之前,支持向量機是人工智能領域的主流技術。即使在今天,支持向量機依然是用于新分類任務的最佳算法之一。這是因為它具有表示數據中多種類型統計關系的能力,并且易于訓練。
決策樹
決策樹是一種出色的模型,它不僅功能強大,而且易于解釋。實際上,該模型的基礎結構與人類做出決策的方式非常相似。一些機器學習開發者認為決策樹在新的問題域上提供了最佳的開箱即用性能。
K - 近鄰算法
K - 近鄰算法是一種監督學習模型。它沒有正式的訓練程序,因此它在模型中顯得有些異常。正因如此,K - 近鄰算法是一個解釋和實現都相對簡單的模型。
第二章:機器學習實踐
控制模型偏見
構建監督學習模型背后有哪些理論支撐呢?這里探討了偏差 - 方差權衡,這是機器學習中最重要的原則之一。
如何選擇模型
模型選擇過程中有哪些細節?這通常需要評估多個模型的泛化誤差。這里主要關注的是,如何使用現有數據和建立的模型來選擇最佳模型,而不考慮模型的具體細節如何。
你需要什么特征
特征選擇與模型選擇緊密相關。
模型正則化
模型正則化在機器學習中極為重要,也是 AI 從業者最強大的工具之一。
模型集成
顧名思義,集成的核心思想是將一組模型組合在一起,以獲得性能更高的模型,就像在管弦樂隊中組合樂器一樣。這一部分就講述了如何在機器學習中獲得和諧的「聲音」。
模型評估
模型評估對于訓練和交叉驗證尤其重要。
無監督學習
購物籃分析
購物籃分析是無監督學習算法的一個示例,它要解決的問題是分析不同物品組合之間的關系及其在特定籃子中出現的頻率。
K-Means 聚類算法
這一部分從數據聚類的角度進一步介紹了無監督學習。這里介紹了 K-means 聚類算法,這是 AI 從業者最常用的聚類算法之一。
主成分分析
主成分分析是這本資料介紹的首個數據降維技術。聽起來有點復雜,但其核心降維技術是一個相當直觀的想法。
深度學習
前饋神經網絡
從前饋神經網絡開始,作者開始深入探討深度學習。由于深度學習主要是對神經網絡的研究,因此在資料中作者也詳細介紹了神經網絡模型,首先就從前饋神經網絡展開。
神經網絡實踐
上一節介紹了前饋神經網絡的示例,但漏掉了一些細節,如激活函數、權重設置以及神經網絡理論的其他方面。本節將對這些問題進行總結。
卷積神經網絡
2012 年,來自多倫多大學的研究團隊提出世界上第一個完全使用神經網絡構建的圖像識別系統 AlexNet,并在 ImageNet 競賽中脫穎而出。這一里程碑事件對今天的人工智能浪潮起到推動作用,卷積神經網絡架構是這一轉折點的核心。
循環神經網絡
卷積神經網絡與視覺任務相關,而循環神經網絡曾經是語言相關問題的標準模型。實際上,很長一段時間以來,自然語言研究者認為,循環網絡能夠在任何自然語言問題上取得 SOTA 結果。對于單個模型來說,這是很高的要求。但時至今日,循環神經網絡仍然在自然語言任務上表現出色。
作者介紹
這本資料的作者是亞馬遜 Alexa AI 的機器學習科學家 Mihail Eric,其主要研究方向是對話式人工智能。Mihail Eric 此前在斯坦福大學獲得了計算機科學碩士學位。Mihail Eric 花了數年的時間建立面向目標的對話機器人,并從事計算語義和文本推斷方面的研究。