NoSQL中負載均衡系統(tǒng)如何解決熱點問題,提高可用性?
一、背景
表格存儲(原名OTS)是一款阿里自研的NoSQL多租戶分布式數(shù)據(jù)庫,本文主要會分享在表格存儲中,負載均衡系統(tǒng)如何解決熱點問題。
1、表格存儲架構(gòu)
下圖是表格存儲系統(tǒng)最基本的一個架構(gòu)圖:
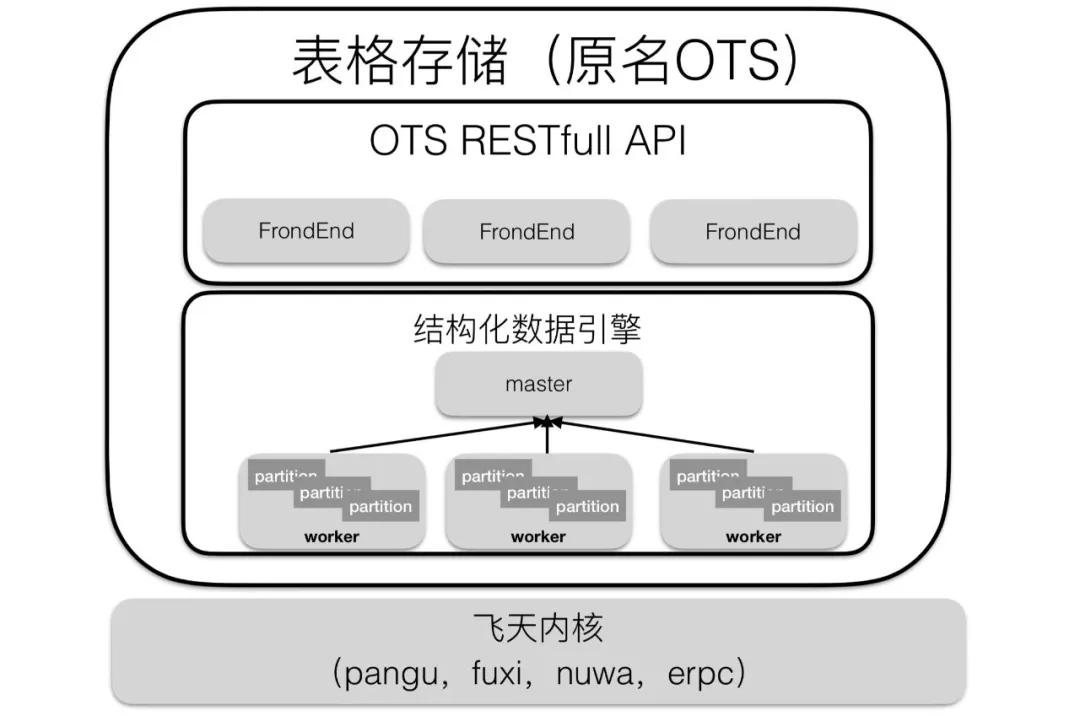
實際上,表格存儲還有很多其他的模塊,這里我們主要看下和本文內(nèi)容相關(guān)的部分,并且也是最核心的一部分。
從下往上看,表格存儲是基于飛天內(nèi)核的產(chǎn)品,飛天內(nèi)核主要提供了分布式共享存儲、分布式鎖服務(wù)、通信組件等基礎(chǔ)功能。
然后上面是表格存儲的引擎部分,主要由worker和master組成,一個集群中有少量的master和大量的worker,master負責管理worker的狀態(tài),并將partition調(diào)度到各個worker上提供對外的服務(wù)。
再上層是前端組件,提供統(tǒng)一的http服務(wù),并把這些請求轉(zhuǎn)發(fā)到worker上。
2、負載均衡相關(guān)的背景
在表格存儲系統(tǒng)中,我們會對用戶數(shù)據(jù)按分片鍵進行切分,切分之后的一個分片,我們叫做partition,它是表格存儲系統(tǒng)里面,調(diào)度的基本單元,所有調(diào)度都是基于partition的。
partition可以做如下操作:
- move:把partition從一臺機器遷移到另外一臺機器上進行服務(wù)。
- split:把一個partition分裂成兩個partition。
- merge:把兩個partition合并成一個partition。
- group:group是隔離partition的主要手段,舉個例子:它一般是先將一批worker加入到指定group中,然后將instance、table或者partition也加入到該group,完成這些操作后,系統(tǒng)會將屬于指定group的instance、table的所有partition和顯示指定group的partition都固定調(diào)度在該group的worker上,達到隔離的目的。說簡單一點就是我給一些用戶分配指定的機器,這些機器專門給這些用戶服務(wù)。
上述的所有對partition的操作,包括move、split、merge、group,都是秒級別的。
3、熱點問題
在NoSQL多租戶系統(tǒng)中經(jīng)常遇到的熱點問題,主要分為以下兩類:
1)用戶訪問熱點
用戶訪問熱點又分為合理的突發(fā)式訪問熱點,以及不合理的突發(fā)式訪問熱點:
- 合理的突發(fā)式訪問指的是,用戶的表設(shè)計合理,只是業(yè)務(wù)量突然上漲導(dǎo)致的,比如說大促。
- 不合理的訪問熱點指的是,用戶的表設(shè)計不合理,在這個基礎(chǔ)上,業(yè)務(wù)量上漲導(dǎo)致的熱點。
2)機器熱點
機器的熱點問題指的是,該機器的cpu,網(wǎng)絡(luò)流量由于某些原因突然變高,該機器資源成為瓶頸,導(dǎo)致的熱點。
通常,熱點問題很難處理,主要有如下原因:
- 定位難:系統(tǒng)中的信息統(tǒng)計不夠全,導(dǎo)致了出現(xiàn)熱點問題,很難定位,只能靠猜。
- 解決難:即使定位了問題,有可能還很難處理,主要原因是系統(tǒng)中處理熱點的手段不足。
- 人工處理慢:即使能定位,也能解決,但是處理時間太長,嚴重影響服務(wù)的可用性。
在表格存儲系統(tǒng)中,對上述幾個難點,我們都有對應(yīng)的手段來解決。針對信息不全,定位難的問題,我們系統(tǒng)中有詳細的partition級別統(tǒng)計信息,并且秒級別的partition move、split、merge、group功能也能很好地處理問題。
我們開發(fā)了一套負載均衡系統(tǒng),它能收集信息、分析信息、解決問題,做到熱點問題快速自動化解決,不需要人工參與。
二、負載均衡系統(tǒng)
接下來我們來看看表格存儲中的負載均衡系統(tǒng)是如何自動化解決問題的。首先介紹負載均衡系統(tǒng)的架構(gòu),然后分模塊來詳細闡述各個模塊的功能。
1、負載均衡架構(gòu)
下圖是負載均衡系統(tǒng)的架構(gòu)圖:
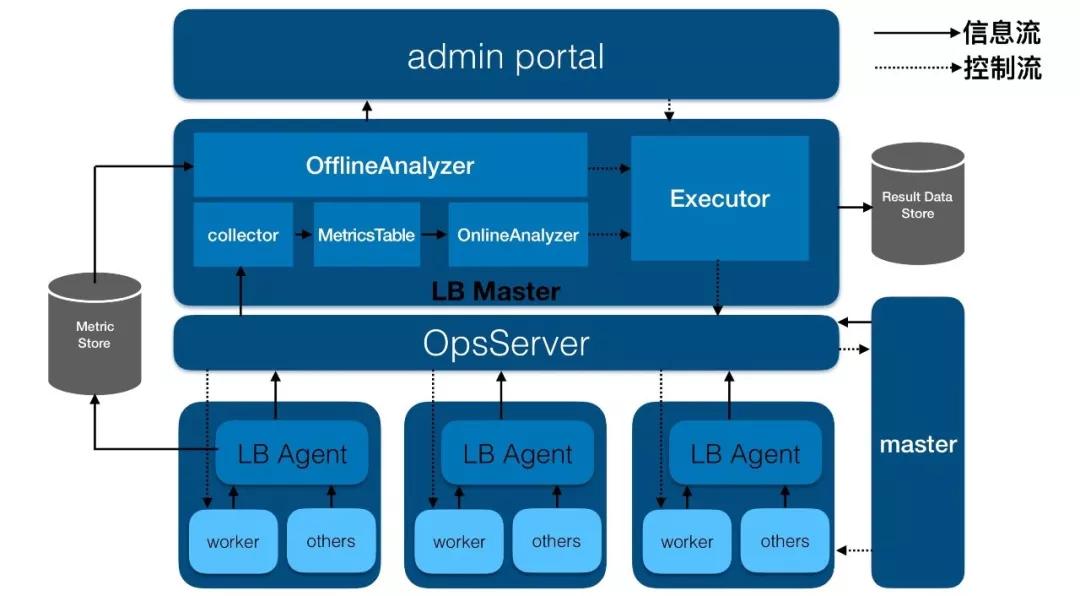
它主要包括LBAgent和LBMaster兩個角色,其中LBAgent和worker進程部署在同一臺機器上,它負責收集這臺機器上的所有信息指標,包括worker進程和其他相關(guān)的進程。收集之后,在內(nèi)存中維護近期的數(shù)據(jù),同時把數(shù)據(jù)異步地寫到外部存儲系統(tǒng)中,在圖中我們叫做MetricStore。
然后往上一層的模塊是OpsServer,它是很薄的一層封裝,主要提供了所有命令的http服務(wù)。
再往上是LBMaster。LBMaster中的collector模塊通過OpsServer實時收集LBAgent的數(shù)據(jù),并把近期的數(shù)據(jù)維護在內(nèi)存中,這個模塊我們叫做MetricsTable,它主要提供各種數(shù)據(jù)聚合和top排序的功能。
在線分析模塊(OnlineAnalyzer)會實時分析MetricsTable中的近期數(shù)據(jù),來檢測是否有熱點等異常的問題。如果有,則對這些信息進行進一步分析,來產(chǎn)生相應(yīng)的解決action,并把這些action交給執(zhí)行模塊(Executor)。執(zhí)行模塊通過OpsServer把相應(yīng)的action發(fā)送給worker或者master,由worker或者master執(zhí)行action,最終解決熱點問題。
同時,LBMaster還有一個離線分析模塊(OfflineAnalyzer),這個模塊主要從外部存儲系統(tǒng)MetricStore中讀取信息,并對這些信息進行分析,以檢測系統(tǒng)中是否有潛在問題,如果有,則對這些問題產(chǎn)生相對應(yīng)的action,同樣通過OpsServer交給worker或者master來執(zhí)行,最終解決潛在的問題,做到防患于未然。
無論是在線分析模塊還是離線分析模塊,分析出的結(jié)果和action都會寫入到一個外部存儲系統(tǒng)中,這里叫做ResultDataStore,主要為了人工或者系統(tǒng)對這些action做進一步的分析。
LBMaster還提供一個白屏化的管控平臺,這個管控平臺能夠?qū)崟r查詢LBMaster中的各種數(shù)據(jù),同時也可以通過它來發(fā)送人工運維命令。
2、信息收集模塊
信息收集模塊有兩個重點:
- 信息盡可能地全。
- 不能影響主路徑的性能。
在表格存儲系統(tǒng)中,任何一個模塊處理請求時,都會順便收集該模塊的相關(guān)信息,這些信息會隨著請求一起流動。如下圖:
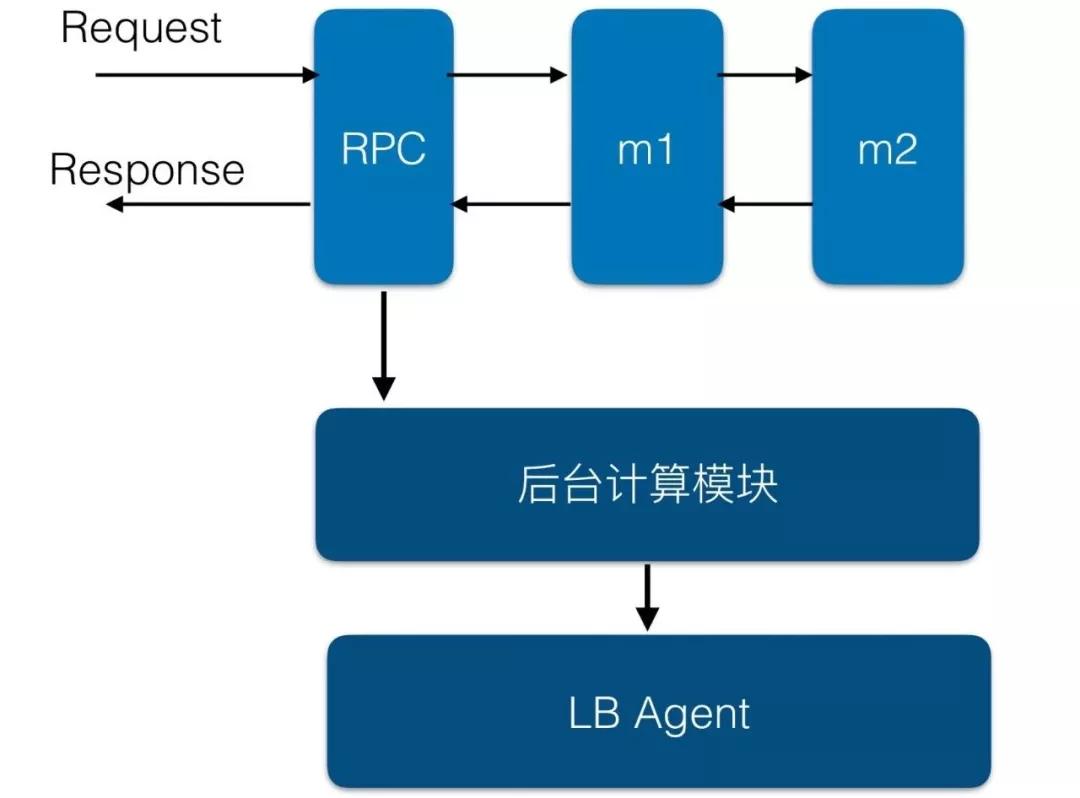
在圖中,經(jīng)過rpc模塊,就會收集rpc模塊中的統(tǒng)計信息;經(jīng)過m1、m2模塊時,也會一起收集m1、m2模塊的信息;最終在返回用戶前,異步地把信息推送到一個后臺計算模塊,這個模塊會在后臺用很少量的資源來匯總這些信息,并定期把信息推送給LBAgent。
由于這個后臺計算模塊,不在主路徑上執(zhí)行,是異步執(zhí)行的,并且只占用少量的資源,可能只有一個核的cpu,所以對主路徑的性能影響極小。
通過這種方式,我們既保證了能收集到各個模塊的信息,同時盡可能地減少了對主路徑性能的影響。
3、LBAgent模塊
LBAgent模塊主要有三個功能:
- 收集單機上的所有信息。
- 對這些信息進行預(yù)聚合。
- 異步地持久化所有信息。
如圖所示:
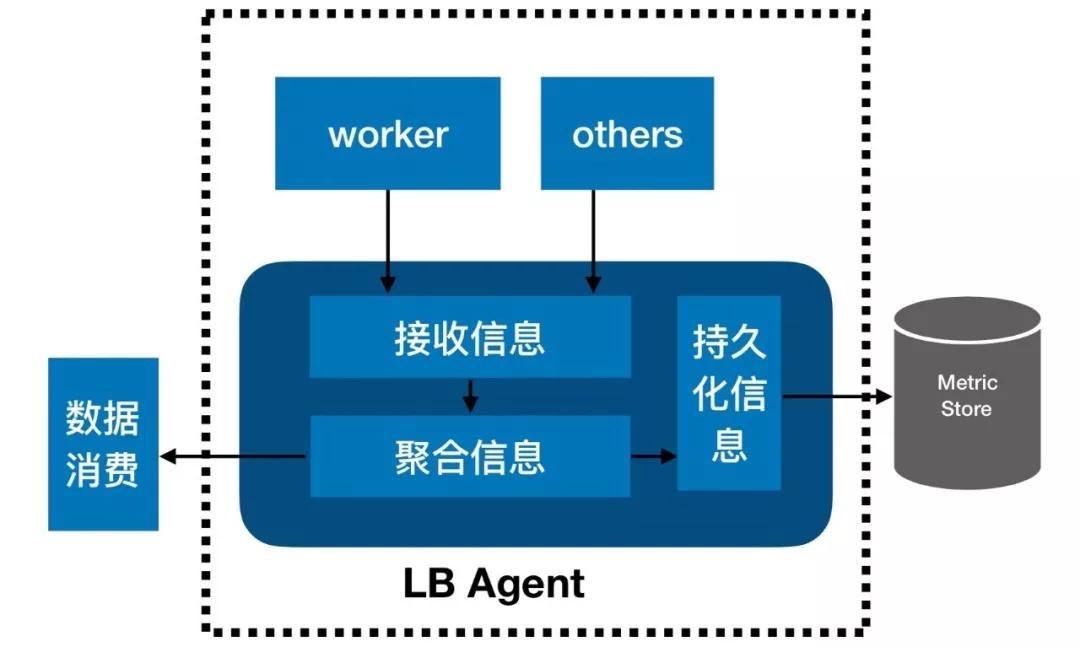
LBAgent端的接收信息模塊不僅會收到worker進程的信息,還會收到系統(tǒng)中其他相關(guān)進程的信息。收到信息之后,LBAgent在內(nèi)存中維護近期收集的信息,同時異步地將信息持久化到外部存儲系統(tǒng)(MetricStore)中,以保存更長時間。LBMaster通過接口周期性地獲取LBAgent內(nèi)存中維護的信息。
4、LBMaster模塊
LBMater模塊是負載均衡系統(tǒng)最核心的模塊。它的主要功能是:
- 收集集群所有信息。
- 多維度信息的top查詢,包括但不限于錯誤率、延時、qps等信息。
- 分析信息、產(chǎn)生action、執(zhí)⾏action。
- 自我反饋策略的有效性。
我們結(jié)合下圖來看:
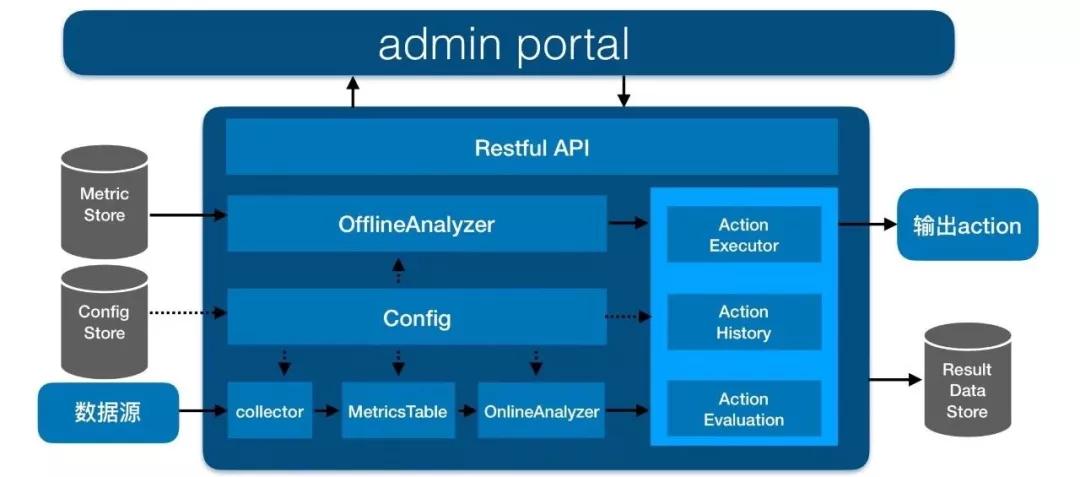
collector負責收集信息,MetricsTable負責多維度信息的top查詢,OnlineAnalyzer和OfflineAnalyzer模塊分別分析在線實時信息和離線信息,ActionExecutor模塊負責執(zhí)行分析模塊產(chǎn)出的action。
在action執(zhí)行完成之后,ActionEvaluation模塊會比較action執(zhí)行前后的信息變化來判斷這個action的效果,通過這種方式來反饋該action是否真正解決了問題。
此外,LBMaster還有一個配置相關(guān)的模塊,各個模塊都有靈活的配置,配置存儲在外部存儲系統(tǒng)中,配置模塊會讀取這些信息,然后同步給所有模塊。所有模塊的配置都支持實時地動態(tài)更新。
總結(jié)下,LBMaster的有如下特點:
- 冷熱數(shù)據(jù)存儲分離:其中熱數(shù)據(jù)存儲在內(nèi)存中,保留最近小時級別的數(shù)據(jù),冷數(shù)據(jù)存儲在外部存儲系統(tǒng)中,可以按需保留數(shù)月甚至幾年。
- 離線在線模塊分離:從架構(gòu)圖中可以看到,離線模塊和在線模塊的路徑不會相互影響。
- 配置靈活、動態(tài)加載:LBMaster支持靈活的配置,并且能夠不升級動態(tài)加載。
- 白屏化操作及信息展示:LBMaster中的所有信息都支持白屏化的展示,并且還可以白屏化發(fā)送運維命令給LBMaster,LBMaster會執(zhí)行這些運維命令。
- 高可用:由于LBMaster在整個負載均衡系統(tǒng)中起著核心的作用,所以它還要做到高可用。
接下來,我們從在線和離線兩方面來看下負載均衡處理問題的情況。
5、在線分析路徑
首先看在線分析路徑。在線分析主要是分析短期信息,發(fā)現(xiàn)問題,最終解決問題,它主要有如下特點:
- 數(shù)據(jù)實時性要求極高,分析頻率高,秒級別發(fā)現(xiàn)并處理問題。
- 數(shù)據(jù)量小、全部維護在內(nèi)存表中。
- 主路徑不依賴任何外部系統(tǒng)。
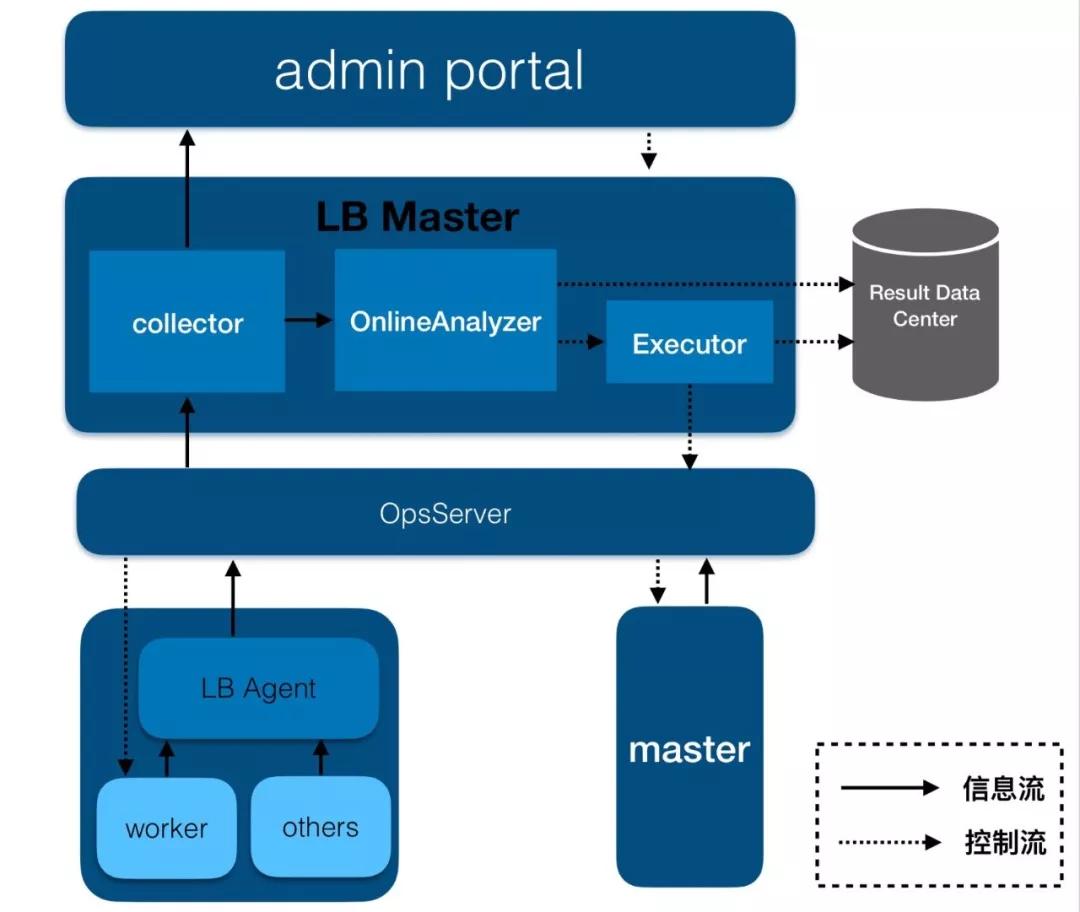
我們從架構(gòu)圖來看在線分析路徑,可以發(fā)現(xiàn):
- 整個數(shù)據(jù)流路徑,從worker到LBAgent再到LBMaster,以及控制流路徑從LBMaster到worker、master,除了分析的結(jié)果會異步地寫外部存儲系統(tǒng)外,不涉及任何外部系統(tǒng)。
- 并且分析結(jié)果寫外部存儲系統(tǒng)的失敗也不影響主路徑的執(zhí)行,它是一個異步的操作。所有這些設(shè)計都是為了滿足實時性的要求。
在表格存儲系統(tǒng)中有很多在分析的策略,下面舉兩個例子:
例1:熱點問題導(dǎo)致讀寫隊列滿報錯

- 首先,負載均衡系統(tǒng)分析信息會發(fā)現(xiàn)worker1的隊列被打滿,報錯,到達了單partition的服務(wù)瓶頸。
- 然后進一步分析發(fā)現(xiàn)可以做split來解決這個問題,因此負載均衡系統(tǒng)發(fā)出split partition1的action,action通過worker和master執(zhí)行后,partition1被切分為partition11和partition12,并調(diào)度到兩臺機器上服務(wù)。通過這種方式解決了熱點問題。
例2:機器資源滿導(dǎo)致的問題

負載均衡系統(tǒng)分析信息發(fā)現(xiàn)worker1的資源被打滿,然后開始分析原因,發(fā)現(xiàn)是partition2導(dǎo)致的,進一步分析發(fā)現(xiàn)partition2的訪問模式有問題。
比如說是單partitionkey的訪問,或者順序?qū)懺L問,這種訪問模式,split不能解決問題,所以負載均衡系統(tǒng)發(fā)出隔離partition2的action,action執(zhí)行后,partition2被單獨隔離到一臺機器上服務(wù)。
此時,partition2不影響其他任何用戶,并且也獨享整體機器的資源,系統(tǒng)給它提供了強服務(wù)能力。
6、離線分析路徑
與在線分析路徑恰好相反的是,離線分析主要是分析長期信息,發(fā)現(xiàn)潛在的問題,并最終消除這些潛在問題,做到防患于未然。和在線路徑相比,它的特點是:
- 數(shù)據(jù)實時性要求低,分析頻率低,小時級別發(fā)現(xiàn)并處理問題。
- 由于數(shù)據(jù)量大,信息維護在外部存儲系統(tǒng)中。
- 計算量大,所以分析的時候可以依賴外部分析系統(tǒng)。
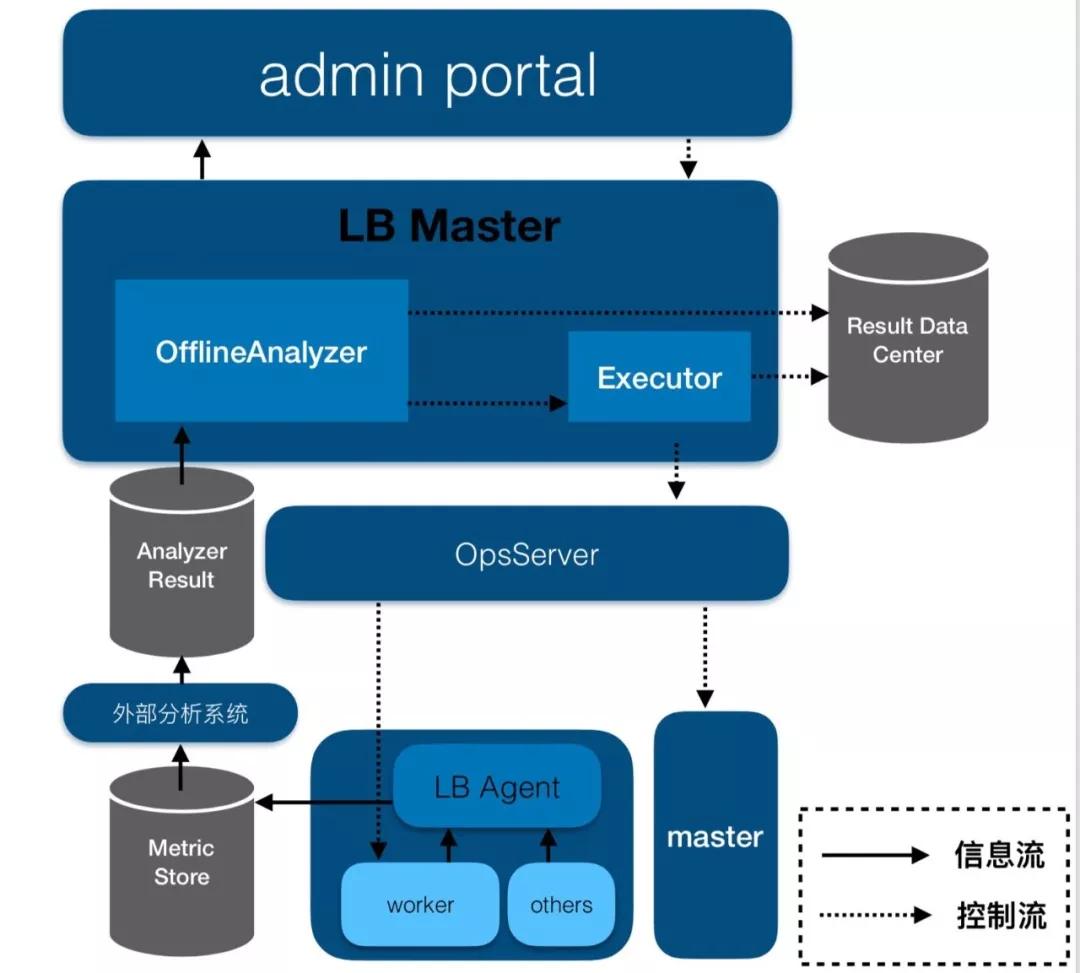
從架構(gòu)圖來看,離線分析路徑的數(shù)據(jù)來源于外部存儲系統(tǒng),并且由于分析的數(shù)據(jù)量很大,它會先借助外部分析系統(tǒng)做初步的分析,然后把分析結(jié)果寫入到一張結(jié)果表中。
LBMaster的離線分析模塊,對結(jié)果表中的信息做進一步的分析,然后發(fā)現(xiàn)問題,產(chǎn)生action。借助外部分析系統(tǒng),大大減少了LBMaster的資源消耗,也大大增加了分析的能力。
接下來簡單介紹兩個離線分析策略的例子:
首先是auto merge,在NoSQL系統(tǒng)中,有部分的partition剛開始訪問量很大,所以被切分成很多partition,隨后這些partition的訪問量可能會很低,甚至幾乎沒有,那么我們就可以將這些partition進行merge,來節(jié)約系統(tǒng)資源。
但是,不能通過短期統(tǒng)計數(shù)據(jù)判斷一個partition訪問量低就對它做merge,因為有些partition的訪問模式是周期性的,所以要通過長期統(tǒng)計數(shù)據(jù)來判斷一個partition能否做merge。
另外一個例子是,我們可以通過對長期數(shù)據(jù)的分析來預(yù)測某些用戶的訪問峰值,提前做好資源的調(diào)整。
7、效果展示
接下來,展示一些負載均衡系統(tǒng)上線后的效果。選取的都是有明顯熱點的業(yè)務(wù),所以效果都非常明顯。
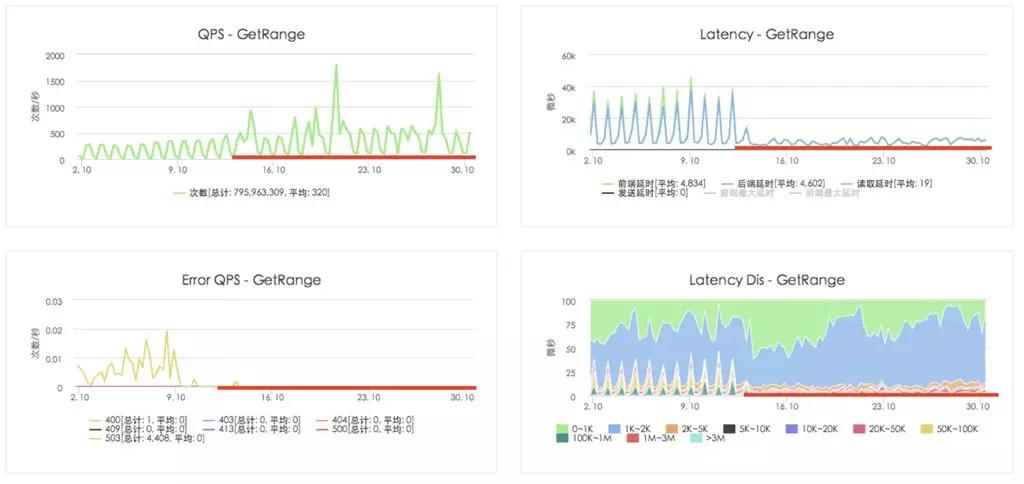
如下圖所示,負載均衡系統(tǒng)上線后,讀操作的錯誤率和延時明顯降低,吞吐量明顯提高:
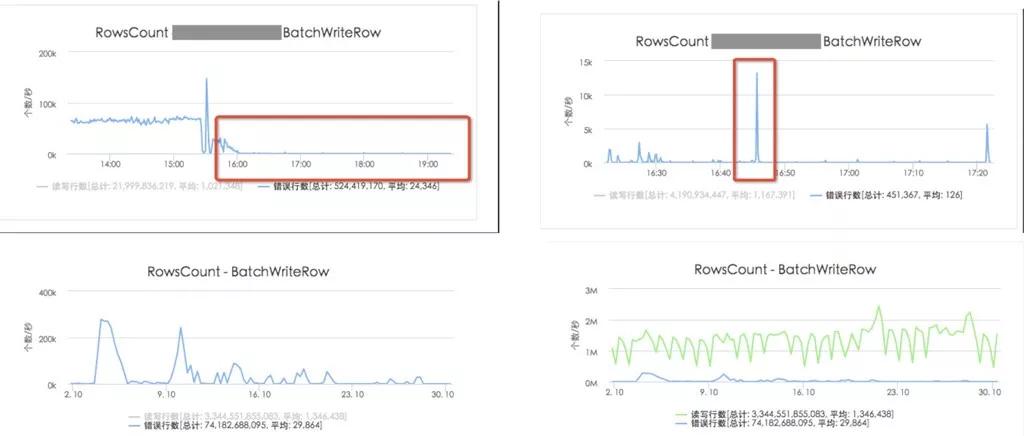
如下圖所示,負載均衡系統(tǒng)上線后,寫操作的錯誤率明顯降低,并且在發(fā)現(xiàn)熱點的時候,即錯誤率突然升高時,能立刻處理掉:
三、總結(jié)
從我自己做負載均衡系統(tǒng)的實踐中總結(jié)了幾點經(jīng)驗:
每個模塊的信息統(tǒng)計是根本
如果沒有信息統(tǒng)計,或者信息統(tǒng)計不全,都會導(dǎo)致問題定位不出來或是定位錯誤,整個負載均衡系統(tǒng)都無從談起。并且這部分的工作量絕對不小,不是很簡單就能做到信息全,并且也幾乎不影響性能的。
把人工處理自動化是高效的策略
很多人剛開始都會覺得負載均衡要用到非常多的機器學(xué)習(xí)算法,這個可能是對的。
但是對于前期來說,我們把人工處理方式來進行自動化處理,可能就能解決90%以上的線上問題,并不需要高大上的機器學(xué)習(xí)算法。在經(jīng)過這個階段之后,一些難點問題,或者預(yù)測性的策略方面,再去考慮機器學(xué)習(xí)的東西。
策略配置豐富,控制靈活
每個策略都要有一些閾值或者條件,這些條件都不能寫死在系統(tǒng)中,都要由配置的方式來傳入,因為線上的情況差異非常大,只有這樣才能有機會針對不同的業(yè)務(wù)、不同的場景進行配置定制。
系統(tǒng)快速迭代,支持差異化配置
負載均衡系統(tǒng)是一個要求快速迭代的系統(tǒng),比如今天發(fā)現(xiàn)線上一類問題,就需要盡快寫出策略上線,來解決線上的問題。
再者,由于每個業(yè)務(wù)的特點不同,訪問模式的差異非常大,對可用性的要求也會有很大區(qū)別。
所以這里就需要非常靈活的配置,對于不同的業(yè)務(wù),也許是同一個策略都會需要不同的配置才能達對這個業(yè)務(wù)而言的理想效果。
Q & A
Q1:請問表的統(tǒng)計信息都統(tǒng)計些什么?既然有工作者隊列,為什么還需要擔心處理熱點問題?
A1:在系統(tǒng)中,有部分隊列不是獨享的,可能是整個進程所有partition都共享的,如果一個partition出現(xiàn)了熱點訪問,占用了所有的資源,可能會導(dǎo)致這臺機器上所有partition的訪問都受到影響。
Q2:那么不采用hash環(huán)的分布式策略,比起明確分區(qū)鍵值有什么壞處?為什么要選用后者?
A2:hash分片主要的問題是,一旦確定之后動態(tài)調(diào)整比較困難,基于分片鍵的方式,能比較容易做到動態(tài)調(diào)整,比如split。而hash分片,如果剛開始分片有問題,后續(xù)再調(diào)整就比較困難。
Q3:我們這邊用的是RabbitMQ,沒有想過要另找一套的思路。當時自己創(chuàng)建這個的時候有沒有參考別的解決方案?然后如何抉擇的?
A3:你這里的隊列服務(wù)可能和我說的不太一樣。如果你們是基于隊列服務(wù)做得系統(tǒng),那么隊列服務(wù)相關(guān)的負載均衡你們基本上就無能為力,要看隊列服務(wù)這個產(chǎn)品來做,如果你們自己的系統(tǒng)本身也有熱點問題,那么本次分享應(yīng)該對你有所幫助。
直播回放
https://m.qlchat.com/topic/details?topicId=2000003638109687
陳新進 阿里云技術(shù)專家
參與阿里云自研NoSQL存儲系統(tǒng)(表格存儲)六年以上研發(fā);
主要負責產(chǎn)品的master模塊和負載均衡系統(tǒng),在系統(tǒng)穩(wěn)定性和可用性方面有一定的積累。