













什么是系統可用性?如何提升可用性?
作者:猿java
可用性是我們在做系統設計時一個重要指標,它確保用戶可以可靠且持續地訪問服務。本文我們將探討什么是可用性、如何計算可用性以及提高可用性的一些常用策略。
日常開發中,我們經常聽到系統的可用性是幾個 9這樣的描述,因此,這篇文章,我們將探討什么是可用性、如何計算可用性以及提高可用性的一些常用策略。

什么是系統可用性?
系統的可用性(Availability)是衡量一個系統在特定時間段內能夠正常運行并提供服務的能力。
可用性計算方式:
Availability = Uptime / (Uptime + Downtime)- Uptime:運行時間,系統正常運行且可訪問的時間段。
- Downtime:停機時間,由于故障、維護或其他問題而導致系統不可用的時期。
舉個例子,假如一年 365天,停機總時間 2天,那么可用性的計算為:
Availability = (365-2) / 365
= 363 / 365
= 0.99452
轉換成百分比 = 99.452 %可用性等級
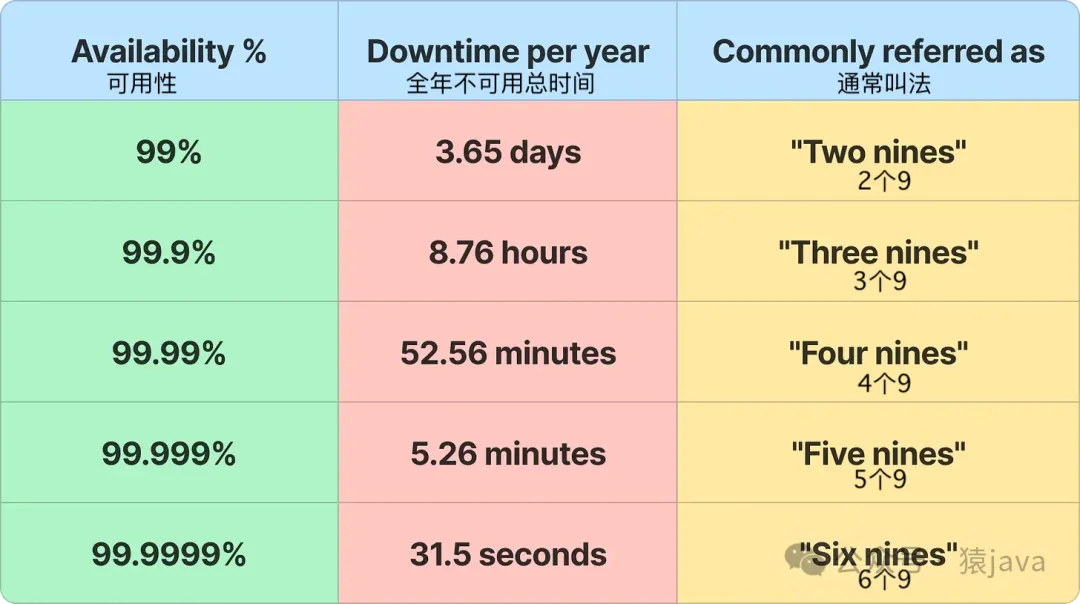
系統可用性,可用性通常用“9”表示,可用性越高,停機時間就越少。如下圖所示:
如何提升系統可用性?
提升系統可用性的方法包括但不限于以下幾種:
1.冗余設計
冗余設計是提升系統可用性常用的方式,比如,分布式部署,異地多活等,冗余設計常見的技術策略主要有以下 3種:
- 服務器冗余:部署多個服務器來處理請求,確保如果一個服務器出現故障,其他服務器可以繼續提供服務。
- 數據庫冗余:創建一個副本數據庫,如果主數據庫發生故障,該數據庫可以接管。
- 地理冗余:將資源分布在多個地理位置,以減輕區域故障的影響。
2.故障檢測與自動恢復
當檢測到故障時,故障切換機制會自動切換到冗余系統。常用的技術策略有:
- 監控系統:使用監控工具(如Nagios、Zabbix)實時監控系統狀態,及時發現問題。
- 自動化恢復:配置自動化腳本或服務(如AWS Auto Scaling)在檢測到故障時自動重啟或替換故障組件。
3.數據備份與恢復
在實際開發中,絕大部署業務都是對數據進行處理,因此數據的重要性不言而喻,對于數據可用性常用的技術點有:
- 定期備份:定期備份重要數據,確保在數據丟失或損壞時能夠快速恢復。
- 災難恢復計劃:制定并測試災難恢復計劃,以確保在重大故障或災難發生時能夠迅速恢復系統運營。
4.負載均衡
負載均衡在多個服務器之間分配傳入的網絡流量,以確保沒有單個服務器成為瓶頸,從而提高性能和可用性。
- 負載均衡器:使用負載均衡器(如Nginx、HAProxy)將請求分發到多個服務器,避免單個服務器過載。
- 分布式系統:設計分布式系統架構,將工作負載分布到多個節點。
5.容錯設計
容錯設計(Fault Tolerance Design),旨在使系統能夠在某些組件發生故障時仍然繼續正常運行,它的核心理念是通過冗余和其他技術手段,避免單點故障導致系統整體失效。
以下是容錯設計的一些具體方法和技術:
- 無狀態服務:設計無狀態服務,使得服務實例可以隨時被替換而不影響整體系統。
- 數據復制:使用數據復制技術(如數據庫的主從復制)保證數據的高可用性。
6.定期維護與更新
在現實生活中,不管是人的健康還是機器或者其他的健康,都需要定期維護,對于系統來說也是一樣的道理,通過定期的維護和更新,可以及時發現和解決潛在問題,防止系統故障,提升系統的整體可用性。
以下是定期維護與更新的主要策略:
- 補丁管理:及時應用安全補丁和系統更新,防止已知漏洞被利用。
- 健康檢查:定期進行系統健康檢查,發現潛在問題并及時修復。
7.使用高可用性云服務
云服務提供商的HA解決方案:利用云服務提供商提供的高可用性解決方案,如多區域部署、自動故障轉移等。
8.網絡優化
- 冗余網絡連接:配置冗余的網絡連接,避免單點網絡故障。
- 優化網絡配置:使用CDN(內容分發網絡)加速內容交付,減少網絡延遲。
總結
可用性是我們在做系統設計時一個重要指標,它確保用戶可以可靠且持續地訪問服務。因此,我們可以結合真實的業務需求,在上面提供的一些技術策略中靈活選擇。
責任編輯:趙寧寧
來源:
猿java












