經典開源代碼分析——Leveldb高效存儲實現
本文基于leveldb 1.9.0代碼。
整體架構
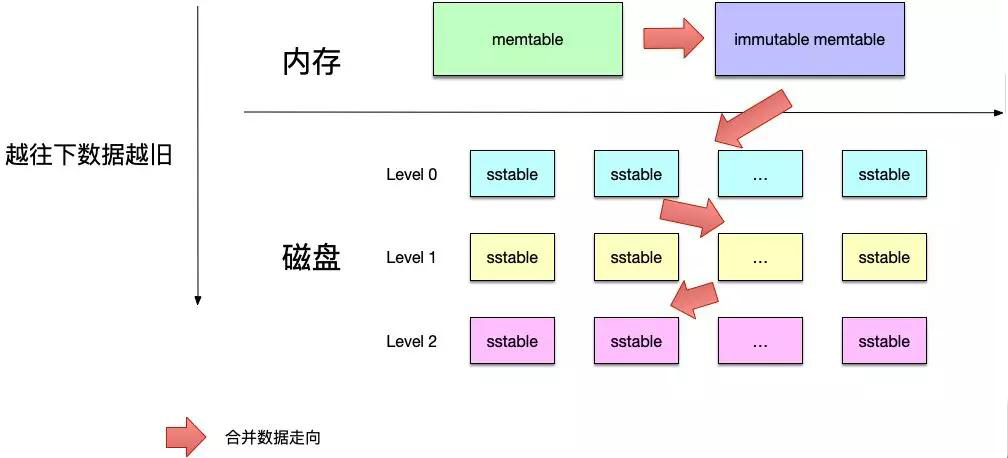
如上圖,leveldb的數據存儲在內存以及磁盤上,其中:
- memtable:存儲在內存中的數據,使用skiplist實現。
- immutable memtable:與memtable一樣,只不過這個memtable不能再進行修改,會將其中的數據落盤到level 0的sstable中。
- 多層sstable:leveldb使用多個層次來存儲sstable文件,這些文件分布在磁盤上,這些文件都是根據鍵值有序排列的,其中0級的sstable的鍵值可能會重疊,而level 1及以上的sstable文件不會重疊。
在上面這個存儲層次中,越靠上的數據越新,即同一個鍵值如果同時存在于memtable和immutable memtable中,則以memtable中的為準。
另外,圖中還使用箭頭來表示了合并數據的走向,即:

以下將針對這幾部分展開討論。
Log文件
寫入數據的時候,最開始會寫入到log文件中,由于是順序寫入文件,所以寫入速度很快,可以馬上返回。
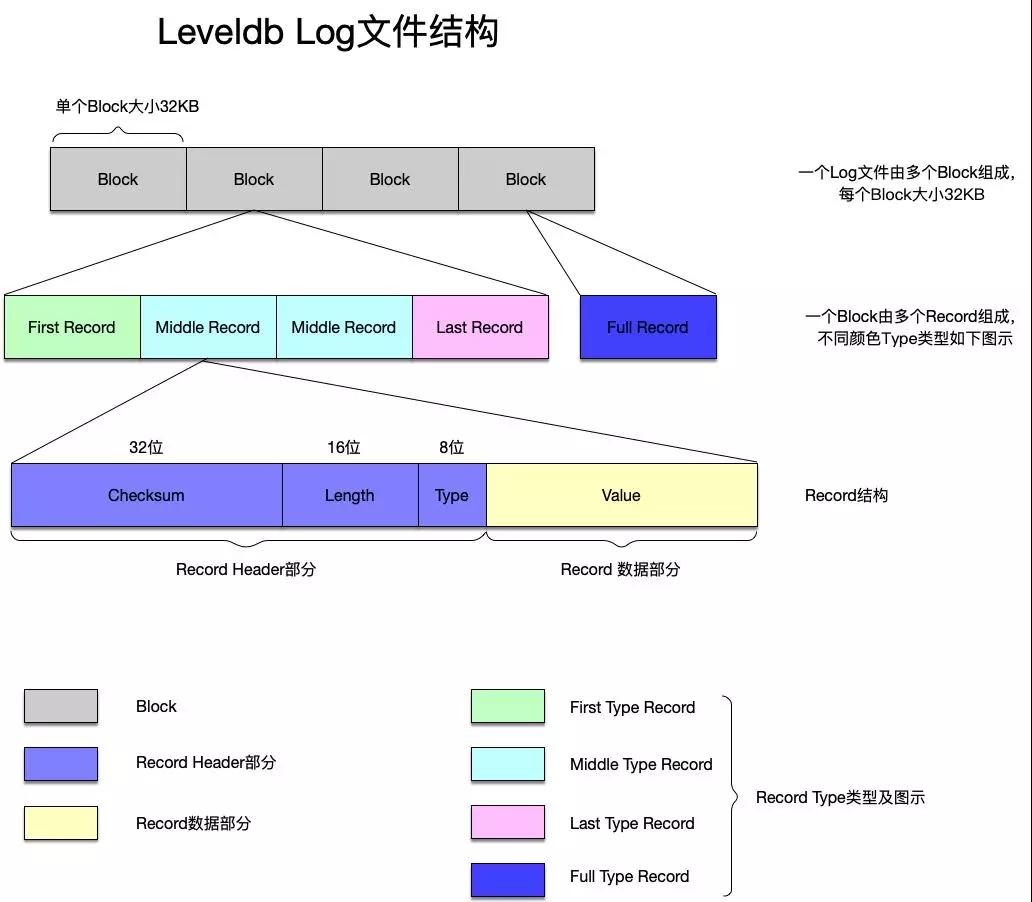
來看Log文件的結構:
- 一個Log文件由多個Block組成,每個Block大小為32KB。
- 一個Block內部又有多個Record組成,Record分為四種類型:
Full:一個Record占滿了整個Block存儲空間。
First:一個Block的***個Record。
Last:一個Block的***一個Record。
Middle:其余的都是Middle類型的Record。
- Record的結構如下:
32位長度的CRC Checksum:存儲這個Record的數據校驗值,用于檢測Record合法性。
16位長度的Length:存儲數據部分長度。
8位長度的Type:存儲Record類型,就是上面說的四種類型。
Header部分
數據部分
memtable
memtable用于存儲在內存中還未落盤到sstable中的數據,這部分使用跳表(skiplist)做為底層的數據結構,這里先簡單描述一下跳表的工作原理。
如果數據存放在一個普通的有序鏈表中,那么查找數據的時間復雜度就是O(n)。跳表的設計思想在于:鏈表中的每個元素,都有多個層次,查找某一個元素時,遍歷該鏈表的時候,根據層次來跳過(skip)中間某些明顯不滿足需求的元素,以達到加快查找速度的目的,如下圖所示:
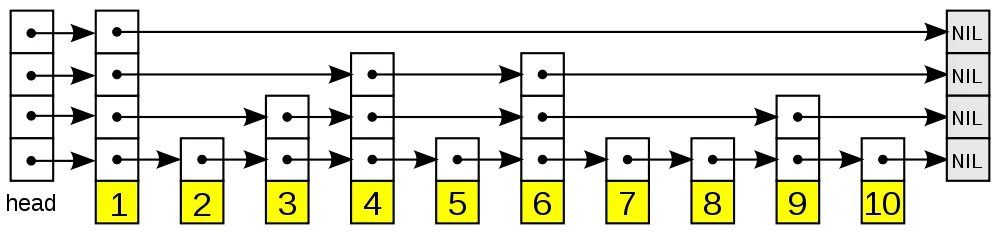
在以上這個跳表中,查找元素6的流程,大體如下:
- 構建一個每個鏈表元素最多有5個元素的跳表。
- 由于6大于鏈表的***個元素1,因此如果存在必然在1之后的元素中,因此進入元素1的指針數組中,從上往下查找元素4:
***層:指向的指針為Nil空指針,不滿足需求,繼續往下查找;
第二層:指向的指針保存的數據為4,小于待查找的元素4,因此如果元素6存在也必然在4之后,因此指針跳轉到元素4所在的位置,繼續從上往下開始查找。
- 到了元素4所在的指針數組,開始從上往下繼續查找:
***層:指向的指針保存的數據為6,查找完畢。
從上面的分析過程中可以看到:
- 跳表是一種以犧牲更多的存儲空間換取查找速度,即“空間換時間”的數據結構。
- 跳表的每一層也都是一個有序鏈表。
- 如果一個元素出現在第i層的鏈表中,那么也必然會在第i層以下的鏈表中出現。
- 鏈表的每個節點中,垂直方向的數組存儲的數據都是一樣的,水平方向的指針指向鏈表的下一個元素。
- ***層的鏈表包含所有元素,也就是說,在***層數據結構退化為一個普通的有序鏈表。
sstable文件
大體結構
首先來看sstable文件的整體結構,如下圖:
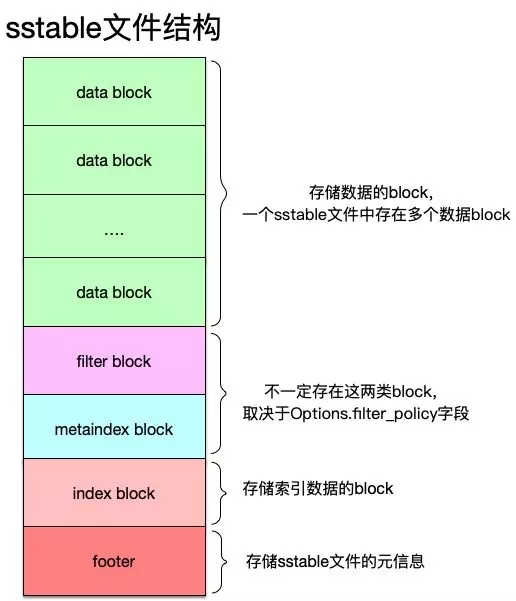
sstable文件中分為以下幾個組成部分:
- data block:存儲數據的block,由于一個block大小固定,因此每個sstable文件中有多個data block。
- filter block以及metaindex block:這兩個block不一定存在于sstable,取決于Options中的filter_policy參數值,后面就不對這兩部分進行講解。
- index block:存儲的是索引數據,即可以根據index block中的數據快速定位到數據處于哪個data block的哪個位置。
- footer:腳注數據,每個footer數據信息大小固定,存儲一個sstable文件的元信息(meta data)。
可以看到,上面這幾部分數據,從文件的組織來看自上而下,先有了數據再有索引數據,***才是文件自身的元信息。原因在于:索引數據是針對數據的索引信息,在數據沒有寫完畢之前,索引信息還會發生改變,所以索引數據要等數據寫完;而元信息就是針對索引數據的索引,同樣要依賴于索引信息寫完畢才可以。
block
上面幾部分數據中,除去footer之外,內部都是以block的形式來組織數據,接著看block的結構,如下圖:
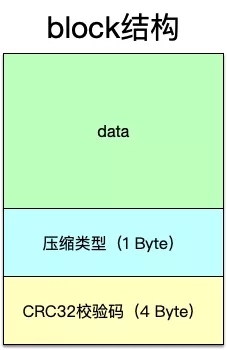
從上面看出,實際上存儲數據的block大同小異:最開始的一部分存儲數據,然后存儲類型,***一部分存儲這個block的校驗碼以做合法性校驗。
以上只是對block大體結構的分析,在數據部分,每一條數據記錄leveldb使用前綴壓縮(prefix-compressed)方式來存儲。這種算法的原理是:針對一組數據,取出一個公共的前綴,而在該組中的其它字符串只保存非公共的字符串做為key即可,由于sstable保存KV數據是嚴格按照key的順序來排序的,所以這樣能節省出保存key數據的空間來。
如下圖所示:一個block內部劃分了多個記錄組(record group),每個記錄組內部又由多條記錄(record)組成。在同一個記錄組內部,以本組的***條數據的鍵值做為公共前綴,后續的記錄數據鍵值部分只存放與公共前綴非共享部分的數據即可。
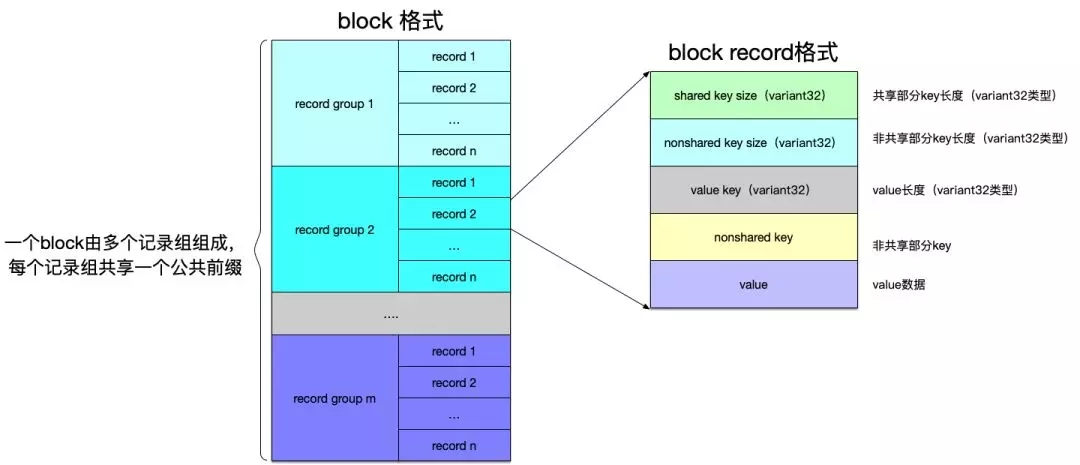
以記錄的三個數據

說明如下:
因為一個block內部有多個記錄組,因此還需要另外的數據來記錄不同記錄組的位置,這部分數據被稱為“重啟點(restart point)”,重啟點首先會以數組的形式保存下來,直到該block數據需要落盤的情況下才會寫到block結尾處。
有了以上的準備,就可以來具體看添加數據的代碼了,向一個block中添加數據的偽代碼如下。

有了前面的這些準備,再在前面block格式的基礎上展開,得到更加詳細的格式如下:
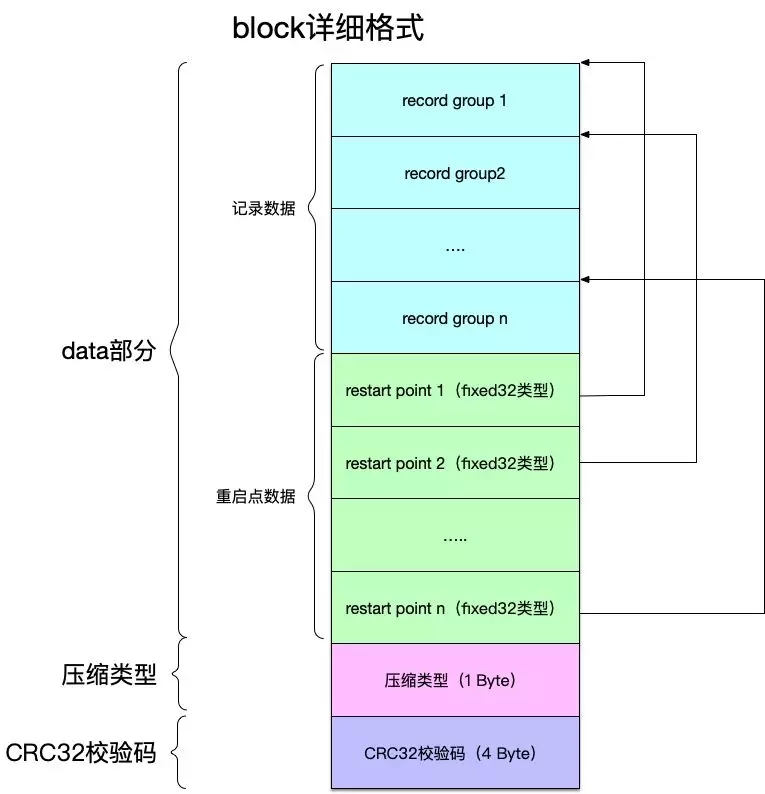
block詳細格式還是劃分為三大部分,其中:
- 數據部分
多個記錄組組成的記錄數據。
多個重啟點數據組成的重啟點數組數據,每個元素記錄對應的記錄組在block中的偏移量,類型為fixed32類型。
- 壓縮類型,大小為1 Byte。
- CRC32校驗數據,大小為4 Byte。
footer
footer做為存儲sstable文件原信息部分的數據,格式相對簡單,如下圖:
Iterator的設計
迭代器的設計是leveldb中的一大亮點,leveldb設計了一個虛擬基類Iterator,其中定義了諸如遍歷、查詢之類的接口,而該基類有多種實現。原因在于:leveldb中存在多種數據結構和多種使用場景,如:
- 保存內存中數據的memtable。
- 保存落盤數據的sstable,而就前面分析而言,一個sstable中還有不同的block,需要根據index block來定位數據處于哪個data block。
- 進行合并的時候,每次最多合并兩個層次的文件,在這個過程中需要對待合并的文件集合進行遍歷。前面分析的DBImpl::DoCompactionWork函數,就是通過iterator來遍歷待合并文件進行合并操作的。
逐個來看不同的iterator實現以及其使用場景。
迭代器大體分為兩類:
- 底層迭代器:處于***層,直接訪問底層數據結構,而不依賴于其他迭代器的迭代器。
- 組合迭代器:組合各種迭代器(包括底層和組合迭代器)完成工作的迭代器。
底層迭代器
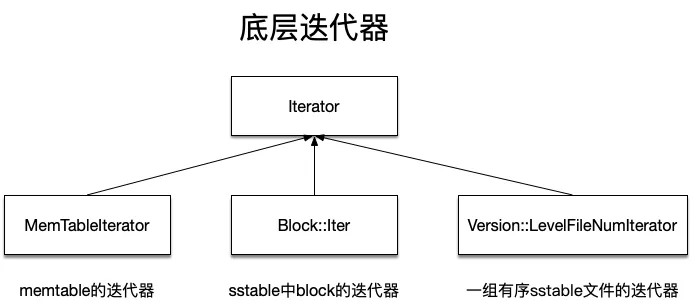
底層迭代器有以下三種:
- MemTableIterator:用于實現對memtable的迭代遍歷,由于memtable由skiplist實現,因此內部封裝了對skiplist的迭代訪問。
- Block::Iter:前面分析sstable的時候,講到一個sstable內部其實有多個block組成,這個迭代器就是按照block的結構進行迭代訪問的迭代器。
- Version::LevelFileNumIterator:每個level都由多個sstable文件組成,說白了就是一個sstable類型的數組。除了level 0之外,其余level的sstable的鍵值之間沒有重疊關系,而LevelFileNumIterator就是用于迭代一組有序sstable文件的迭代器。
組合迭代器
組合迭代器內部都包含至少一個迭代器,組合起來完成迭代工作,有如下幾類。
TwoLevelIterator
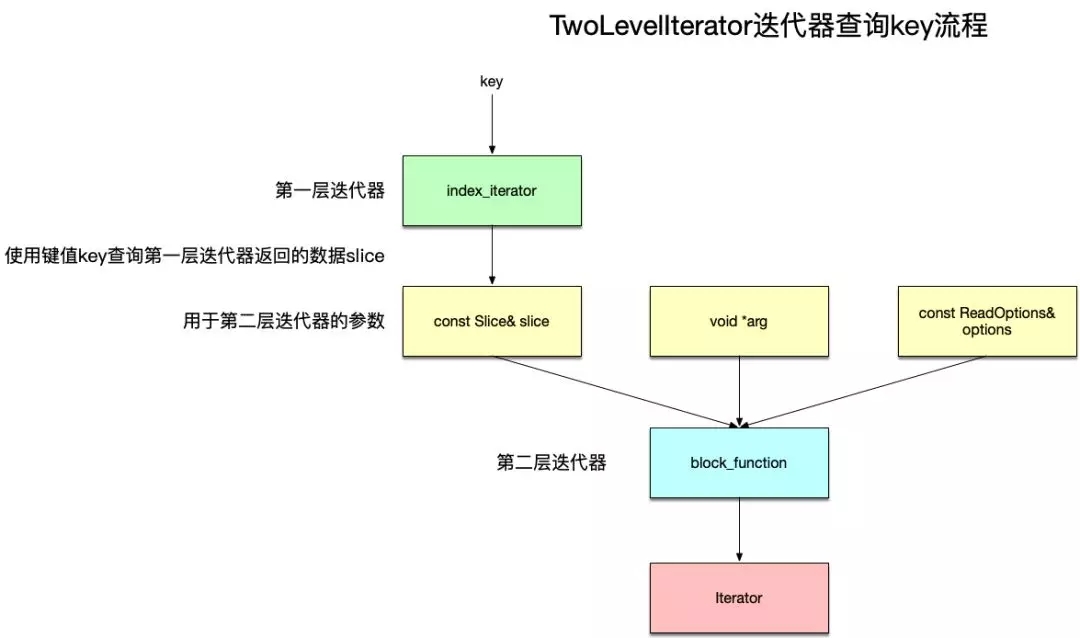
顧名思義,TwoLevelIterator表示兩層迭代器,創建TwoLevelIterator的函數原型為:

參數說明如下:
- Iterator* index_iter:索引迭代器,可以理解為***層的迭代器。
- BlockFunction *block_function:這是一個函數指針,根據index_iter迭代器的返回結果來再創建一個迭代器,即針對查詢索引返回數據的迭代器。其函數參數有三個,其中前面兩個由下面的arg以及options參數指定,而第三個參數slice就是index_iterator返回的索引數據。
- void* arg:傳入BlockFunction函數的***個參數。
- const ReadOptions& options:傳入BlockFunction函數的第二個參數。
綜合以上,TwoLevelIterator的工作流程如下:
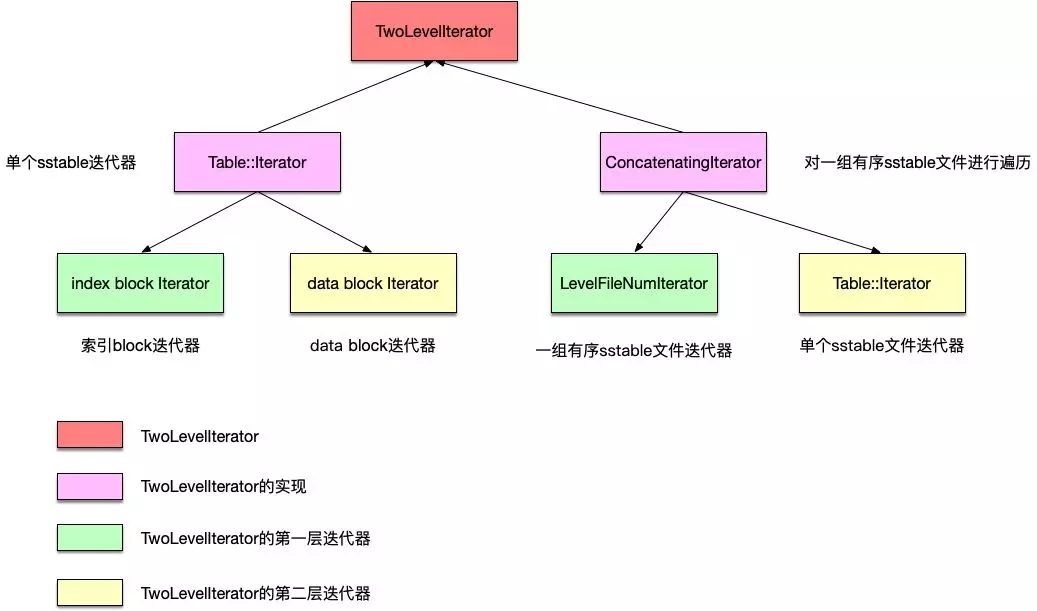
TwoLevelIterator有如下兩類:
- Table::Iterator:實現對于單個sstable文件的迭代。由于一個sstable文件中有多個block,而又劃分為index block和data block,查詢數據時,先根據鍵值到index block中查詢到對應的data block,再進入data block中進行查詢,這個查詢過程實際就是一個兩層的查找過程:先查索引數據,再查數據。因此Table::Iterator類型的TwoLevelIterator,組合了index block的Block::Iter,以及data block的Block::Iter。
- ConcatenatingIterator:組合了LevelFileNumIterator以及Table::Iterator,用于在某一層內的sstable文件中查詢數據。因此它的***層迭代器就是前面的LevelFileNumIterator,用于根據一個鍵值在一組有序的sstable文件中定位到所在的文件,而第二層的迭代器是Table::Iterator,用于在***層迭代器LevelFileNumIterator中查詢到的sstable文件中查詢鍵值。另外,既然ConcatenatingIterator處理的是有序sstable文件,那么level 0的sstable文件就不會使用這種迭代器進行訪問,因為level 0文件之間有重疊鍵值。
MergingIterator
用于合并流程的迭代器。在合并過程中,需要操作memtable、immutable memtable、level 0 sstable以及非level 0的sstable,該迭代器將這些存儲數據結構體的迭代器,統一進行歸并排序:
- memtable以及immutable memtable:使用前面提過的MemtableIterator迭代器。
- level 0 sstable:由于level 0的sstable文件之間鍵值有重疊,所以使用的是level 0的sstable文件各自的Table::Iterator。
- level 1層級及以上的sstable:使用前面介紹過的ConcatenatingIterator,即可以針對一組有序sstable文件進行遍歷的iterator。
由于以上每種類型的iterator,內部遍歷數據都是有序的,所以MergingIterator內部做的事情,就是將對這些iterator的遍歷結果進行“歸并”。MergingIterator內部有如下變量:
- const Comparator* comparator_:用于鍵值比較的函數operator。
- IteratorWrapper* children_:存儲傳入的iterator的數組。
- int n_:children_數組的大小。
- IteratorWrapper* current_:保存當前查詢到的位置所在的iterator。
- Direction direction_:保存查找的方向,有向前和向后兩種查詢防線。
可以看到,current_以及direction_兩個成員是用于保存當前查找狀態的成員。
構建MergingIterator迭代器傳入的Comparator是InternalKeyComparator,其比較邏輯是:
- 首先比較鍵值是否相等,不相等則直接返回比較結果。
- 如果鍵值相等,那么從鍵值中decode出來sequence值,對比sequence值,對sequence值進行降序比較。由于這個值是單調遞增的,因此越新的數據sequence值越大。換言之,在存儲層次中(依次為memtable->immutable memtable->level 0 sstable->level n sstable)越靠上面的數據,在鍵值相同的情況下越小。
Seek(target)函數的偽代碼:

而FindSmallest函數的實現,是遍歷children_找到最小的child保存到current_指針中。前面分析InternalKeyComparator提到過,相同鍵值的數據,根據sequence值進行降序排列,即數據越新的數據其sequence值越大,在這個排序中查找的結果就越在上面。因此,FindSmallest函數如果在memtable、level 0中都找到了相同鍵值,將優先選擇memtable中的數據。
MergingIterator迭代器的其它實現不再做解釋,簡單理解:針對一組iterator的查詢結果進行歸并排序。對于同樣一個鍵值,只取位置在存儲位置上最靠上面的數據。
這么做的原因在于:一個鍵值的數據可能被寫入多次,而需要以***一次寫入的數據為準,合并時將丟棄掉不在存儲最上面的數據。
以下面的例子來說明MergingIterator迭代器的合并結果。

在上圖的左半邊,是合并前的數據分布情況,依次為:
- memtable:鍵值1的刪除記錄,以及鍵值<2,test>。
- immutable memtable:鍵值<2,tesat2>以及<3,test>。
- level 0 sstable:鍵值<1,test>。
- level 1 sstable:鍵值<3,a>。
合并的結果如上圖的右邊所示:
- 鍵1:因為***條鍵1的記錄是在memtable中的刪除記錄,所以鍵1將被刪除,即不會出現在合并結果中。
- 鍵2:最靠上面的關于鍵2的存儲記錄是<2,test>,這條記錄保存在合并結果中,而immutable memtable的記錄<2,test2>將被丟棄,因為這條記錄不是***的。
- 鍵3:使用了immutable memtable中的記錄<3,test>,丟棄了level 1 sstable中的<3,a>這條記錄。
核心流程
有了前面幾種核心數據結構的了解,下面談leveldb中的幾個核心流程。
修改流程
修改數據,分為兩類:正常的寫入數據操作以及刪除數據操作。
先看正常的寫入數據操作:
- append一條記錄到log文件中,雖然這是一次寫磁盤操作,但是由于是在文件末尾做的順序寫操作,所以效率并不低。
- 向當前的memtable中寫入一條數據。這個動作看似簡單,但是如果在來不及合并的時候,可能會出現阻塞,在后面合并操作中再展開解釋。
完成以上兩步之后,就可以認為完成了更新數據的操作。實際上只有一次文件末尾的順序寫操作,以及一次寫內存操作,如果不考慮會被合并操作阻塞的情況,實際上還是很快的。
再來看刪除數據操作。leveldb中,刪除一個數據,其實也是添加一條新的記錄,只不過記錄類型是刪除類型,代碼中通過枚舉變量定義了這兩種操作類型:

這樣看起來,leveldb刪除數據時,并不會真的去刪除一條數據,而是打上了一個標記,那么問題就來了:如果寫入數據操作與刪除數據操作,只是類型不同,在查詢數據的時候又如何知道數據是否存在?看下面的讀數據流程。
讀流程
向leveldb中查詢一個數據,也是從上而下,先查內存然后到磁盤上的sstable文件查詢,如下圖所示:
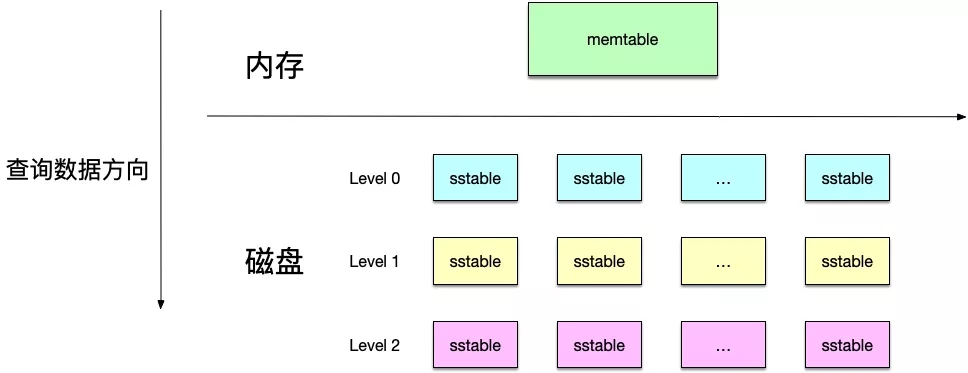
- 先在內存中的memtable中查詢數據,查到則返回;
- 否則在磁盤中的sstable文件中查詢數據,從0級開始往下查詢,查到則返回;
這樣自上而下的原因就在于leveldb的設計:越是在上層的數據越新,距離當前時間越短。
舉例而言,對于鍵值key而言,首先寫入kv對
那么,前面寫入的數據實際上已經沒有用了,但是又占用了空間,這部分數據就等待著后面的合并流程來合并數據***刪除掉。
合并流程
核心數據結構
首先來看與合并相關的核心數據結構。
每一次合并過程以及將memtable中的數據落盤到sstable的過程,都涉及到sstable文件的增刪,而這每一次操作,都對應到一個版本。
在leveldb中,使用Version類來存儲一個版本的元信息,主要包括:
- std::vector
- files_[config::kNumLevels]:用于存儲所有級別sstable文件的FileMetaData數組,可以看到這個成員是一個數組,而數組的每個元素又是一個vector,這其中數組部分使用level級別來進行索引,同級別的sstable信息存儲在vector中。
- FileMetaData* file_to_compact_和int file_to_compact_level_:下一次進行合并時的文件和級別。
double compaction_score_和int compaction_level_:當前***compact分數和對應的級別,在Finalize函數中進行計算,具體計算的規則會在下面介紹。
可以看到,Version保存的主要是兩類數據:當前sstable文件的信息,以及下一次合并時的信息。
所有的級別,也就是Version類,使用雙向鏈表串聯起來,保存到VersionSet中,而VersionSet中有一個current指針,用于指向當前的Version。
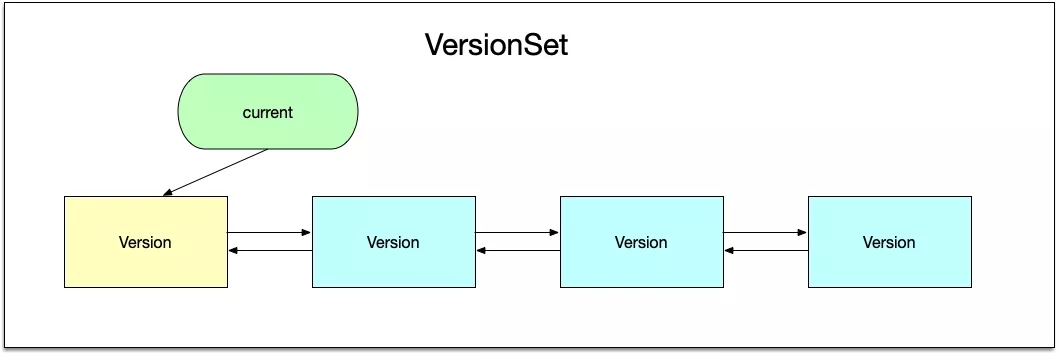
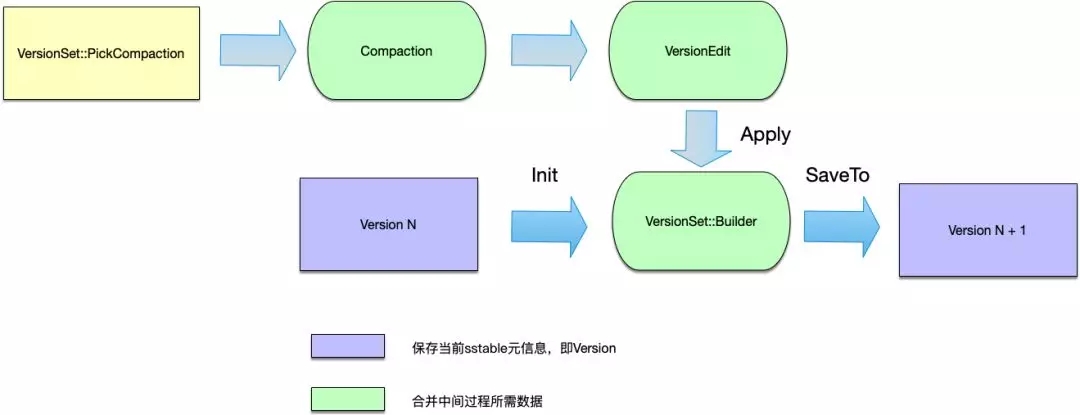
當進行合并時,首先需要挑選出需要進行合并的文件,這個操作的入口函數是VersionSet::PickCompaction,該函數的返回值是一個Compaction結構體,該結構體內部保存合并相關的信息,Compaction結構體中最重要的成員是VersionEdit類成員,這個成員用于保存合并過程中有刪減的sstable文件:
- DeletedFileSet deleted_files_:合并后待刪除的sstable文件。
- std::vector< std::pair
> new_files_:合并后新增的sstable文件。
可以認為:version N + version N edit = version N + 1,即:第N版本的sstable信息,在經過該版本合并的VersionEdit之后,形成了Version N+1版本。
另外還有一個VersionSet::Builder,用于保存合并中間過程的數據,其本質是將所有VersoinEdit內容存儲到VersionSet::Builder中,***一次產生新版本的Version。
合并條件及原理
leveldb會不斷產生新的sstable文件,這時候需要對這些文件進行合并,否則磁盤會一直增大,查詢速度也會下降。
這部分講解合并觸發的條件以及進行合并的原理。
leveldb大致在以下兩種條件下會觸發合并操作:
- 需要新生成memtable的情況下,此時必然會把原來的memtable切換為immutable memtable,后者又需要及時落盤成為新的sstable文件,將immutable memtable數據落盤為sstable文件的流程稱為”minor compaction“,因為有新的sstable文件產生,所以需要合并文件減少sstable文件的數量。
- 查詢數據時,某些sstable總是查找不到數據,此時可能是因為數據太過分散了,也需要將文件合并。
以上兩種情況,對應到leveldb代碼中就是以下幾個地方:
- 調用DB::Open文件打開數據庫文件時,由于之前可能已經存在了一些文件,這時會做檢查,滿足條件的情況下會進行合并操作。
- 調用DB::Write函數寫入數據時,調用MakeRoomForWrite函數分配空間,此時如果需要新分配一個memtable,也會觸發合并操作。
- 調用DB::Get函數查詢數據時,某些文件查詢的次數超過了閾值,此時也會進行合并操作。
另外還需要提一下合并的兩種類型:
- minor compaction:將內存的數據落地到磁盤上的遷移過程,對應于leveldb就是將immutable memtable數據落盤為sstable文件的流程。
- major compaction:sstable之間的文件進行合并的流程。
選擇進行合并的文件
函數VersionSet::PickCompaction用于構建出一次合并對應的Compaction結構體。來看這個函數主要的流程。
在挑選哪些文件需要合并時,依賴于兩個原則:
- 首先考慮每一層文件的數量:這個數量的計數,對應到Version的compaction_score_中,在每次VersionSet::Finalize函數中,都會首先進行預計算這個值,那個級別的分數高,下一次就優先選擇該層次來做合并。對于不同的層次,計算的規則也不同:
level 0:0級文件的數量除以kL0_CompactionTrigger來計算分數。
非0級:該層次的所有文件大小/MaxBytesForLevel(level)來計算分數。
- 如果上面的計算中,compaction_score_為0,那么就需要具體針對一個文件來進行合并。leveldb中,在FileMetaData結構體里有一個成員allowed_seeks,表示在該文件中查詢某個鍵值時最多允許的定位次數,當這個值為0時,意味這個文件多次查詢都沒有查詢到數據,因此這個文件就需要進行合并了。
文件的allowed_seeks在VersionSet::Builder::Apply函數中進行計算:

如果是***種情況,即compaction_score_ >= 1的情況來選擇合并文件,還涉及到一個合并點的問題(compact point),即leveldb會保存上一次進行合并的鍵值,這一次會從這個鍵值以后開始尋找需要進行合并的文件。
而如果合并層次是0級,因為0級文件中的鍵值有重疊的情況,因此還需要遍歷0級文件中鍵值范圍與這次合并文件由重疊的一起加入進來。
在這之后,調用VersionSet::SetupOtherInputs函數,用于獲取同級別以及更上一層也就是level + 1級別中滿足合并范圍條件的文件,這就構成了待合并的文件集合。
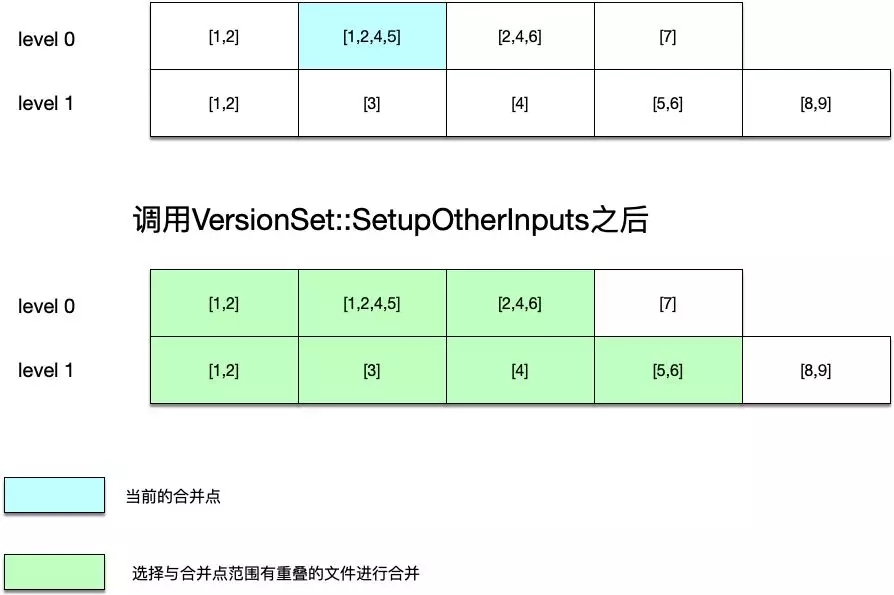
如上圖所示:
- 此時選擇進行合并的文件,其鍵值是[1,2,4,5]。
- 由于該文件在level 0級別,sstable文件的鍵值有重疊,同時還在在其上面一層選擇同樣鍵值范圍有重疊的sstable文件,選擇的結果就是綠色的sstable文件,這些將做為這次合并進行歸并排序的文件。
合并流程
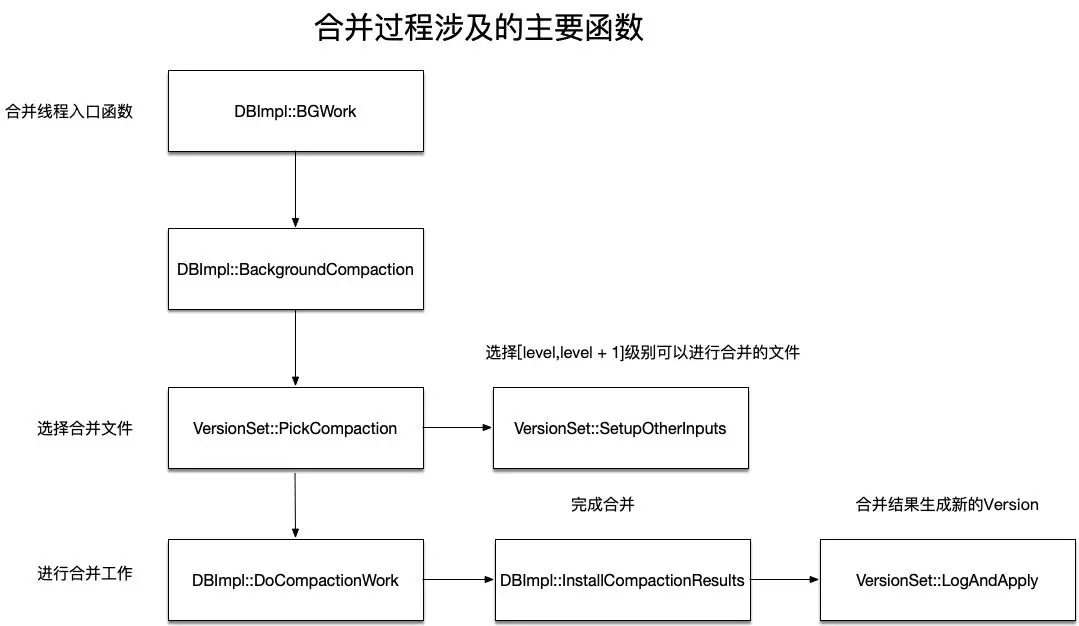
以上調用VersionSet::PickCompaction函數選擇完畢了待合并的文件及層次之后,就來到DBImpl::DoCompactionWork函數中進行實際的合并工作。
該函數的原理不算復雜,就是遍歷文件集合進行合并:

合并操作對讀寫流程的影響
leveldb將用戶的讀寫操作,與合并工作放在不同的線程中處理。當用戶需要寫入數據進行分配空間時,會首先調用DBImpl::MakeRoomForWrite函數進行空間的分配,該函數有可能因為合并流程被阻塞,有以下幾種可能性:

參考資料
數據分析與處理之二(Leveldb 實現原理):https://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
Leveldb之Iterator總結:http://kernelmaker.github.io/Leveldb_Iterator

本文轉載自微信公眾號「高可用架構」,可以通過以下二維碼關注。轉載本文請聯系高可用架構公眾號。