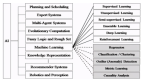
前端人工智能:通過機器學習推導函數方程式--鉑金Ⅲ
什么是tensorflow.js
tensorflow.js是一個能運行在瀏覽器和nodejs的一個機器學習、機器訓練的javascript庫,眾所周知在瀏覽器上用javascript進行計算是很慢的,而tensorflow.js會基于WebGL通過gpu進行運算加速來對高性能的機器學習模塊進行加速運算,從而能讓我們前端開發人員能在瀏覽器中進行機器學習和訓練神經網絡。本文要講解的項目代碼,就是要根據一些規則模擬數據,然后通過機器學習和訓練,根據這些數據去反向推測出生成這些數據的公式函數。
基本概念
接下來我們用五分鐘過一下tensorflow的基本概念,這一部分主要介紹一些概念,筆者會用一些類比方式簡單的講述一些概念,旨在幫助大家快速理解,但是限于精力和篇幅,概念的具體詳細定義讀者們還是多去參照官方文檔。
張量(tensors)
張量其實就是一個數組,可以一維或多維數組。張量在tensorflow.js里就是一個數據單元。
- const tensors = tf.tensor([[1.0, 2.0, 3.0], [10.0, 20.0, 30.0]]);
- tensors.print();
在瀏覽器里將會輸出:
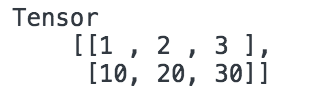
tensorflow還提供了語義化的張量創建函數:tf.scalar(創建零維度的張量), tf.tensor1d(創建一維度的張量), tf.tensor2d(創建二維度的張量), tf.tensor3d(創建三維度的張量)、tf.tensor4d(創建四維度的張量)以及 tf.ones(張量里的值全是1)或者tf.zeros(張量里的值全是0)。
變量(variable)
張量tensor是不可變的,而變量variable是可變的,變量是通過張量初始化而來,代碼如下:
- const initialValues = tf.zeros([5]);//[0, 0, 0, 0, 0]
- const biases = tf.variable(initialValues); //通過張量初始化變量
- biases.print(); //輸出[0, 0, 0, 0, 0]
操作(operations)
張量可以通過操作符進行運算,比如add(加法)、sub(減法)、mul(乘法)、square(求平方)、mean(求平均值) 。
- const e = tf.tensor2d([[1.0, 2.0], [3.0, 4.0]]);
- const f = tf.tensor2d([[5.0, 6.0], [7.0, 8.0]]);
- const ee_plus_f = e.add(f);
- e_plus_f.print();
上面的例子輸出:
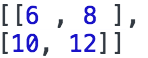
內存管理(dispose和tf.tidy)
dispose和tf.tidy都是用來清空GPU緩存的,就相當于咱們在編寫js代碼的時候,通過給這個變量賦值null來清空緩存的意思。
- var a = {num: 1};
- a = null;//清除緩存
dispose
張量和變量都可以通過dispose來清空GPU緩存:
- const x = tf.tensor2d([[0.0, 2.0], [4.0, 6.0]]);
- const xx_squared = x.square();
- x.dispose();
- x_squared.dispose();
- tf.tidy
當有多個張量和變量的時候,如果挨個調用dispose就太麻煩了,所以有了tf.tidy,將張量或者變量操作放在tf.tidy函數中,就會自動給我們優化和清除緩存。
- const average = tf.tidy(() => {
- const y = tf.tensor1d([4.0, 3.0, 2.0, 1.0]);
- const z = tf.ones([1]);
- return y.sub(z);
- });
- average.print()
以上例子輸出:

模擬數據
首先,我們要模擬一組數據,根據 這個三次方程,以參數a=-0.8, b=-0.2, c=0.9, d=0.5生成[-1, 1]這個區間內一些有誤差的數據,數據可視化后如下:
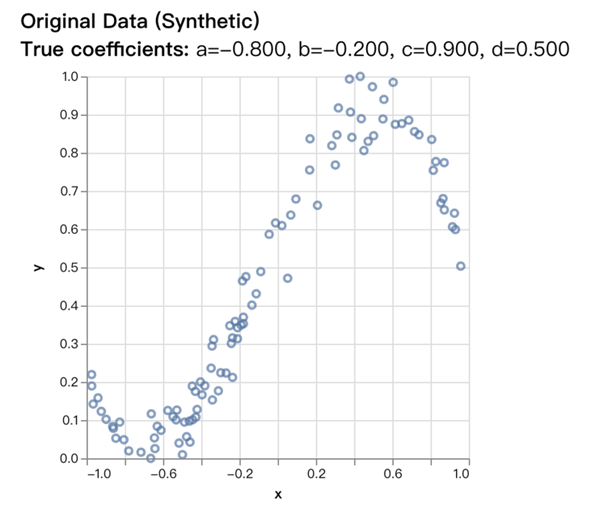
假設我們并不知道a、b、c、d這四個參數的值,我們要通過這一堆數據,用機器學習和機器訓練去反向推導出這個多項式函數方程的和它的a、b、c、d這四個參數值。
設置變量(Set up variables)
因為我們要反向推導出多項式方程的a、b、c、d這四個參數值,所以首先我們要先定義這四個變量,并給他們賦上一些隨機數當做初始值。
- const a = tf.variable(tf.scalar(Math.random()));
- const b = tf.variable(tf.scalar(Math.random()));
- const c = tf.variable(tf.scalar(Math.random()));
- const d = tf.variable(tf.scalar(Math.random()));
上面這四行代碼,tf.scalar就是創建了一個零維度的張量,tf.variable就是將我們的張量轉化并初始化成一個變量variable,如果通俗的用我們平時編寫javascript去理解,上面四行代碼就相當于:
- let a = Math.random();
- let b = Math.random();
- let c = Math.random();
- let d = Math.random();
當我們給a、b、c、d這四個參數值賦上了初始隨機值以后,a=0.513, b=0.261, c=0.259, d=0.504,我們將這些參數放入方程式后得到的曲線圖如下:

我們可以看到,根據隨機生成的a、b、c、d這四個參數并入到多項式后生成的數據跟真正的數據模擬的曲線差別很大,這就是我們接下來要做的,通過機器學習和訓練,不斷的調整a、b、c、d這四個參數來將這根曲線盡可能的接近實際的數據曲線。
創建優化器(Create an optimizer)
- const learningRate = 0.5;
- const optimizer = tf.train.sgd(learningRate);
learningRate這個變量是定義學習率,在進行每一次機器訓練的時候,會根據學習率的大小去進行計算的偏移量調整幅度,學習率越低,后面預測到的值就會越精準,但是響應的會增加程序的運行時間和計算量。高學習率會加快學習過程,但是由于偏移量幅度太大,容易造成在正確值的周邊上下擺動導致運算出的結果沒有那么準確。
tf.train.sgd是我們選用了tensorflow.js里幫我們封裝好的SGD優化器,即隨機梯度下降法。在機器學習算法的時候,通常采用梯度下降法來對我們的算法進行機器訓練,梯度下降法常用有三種形式BGD、SGD以及MBGD。
我們使用的是SGD這個批梯度下降法,因為每當梯度下降而要更新一個訓練參數的時候,機器訓練的速度會隨著樣本的數量增加而變得非常緩慢。隨機梯度下降正是為了解決這個辦法而提出的。假設一般線性回歸函數的函數為:
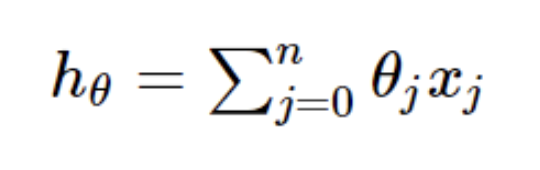
SGD它是利用每個樣本的損失函數對θ求偏導得到對應的梯度,來更新θ:
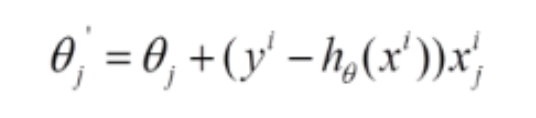
隨機梯度下降是通過每個樣本來迭代更新一次,對比上面的批量梯度下降,迭代一次需要用到所有訓練樣本,SGD迭代的次數較多,在解空間的搜索過程看起來很盲目。但是大體上是往著更優值方向移動。隨機梯度下降收斂圖如下:

預期函數模型(training process functions)
編寫預期函數模型,其實就是用一些列的operations操作去描述我們的函數模型
- function predict(x) {
- // y = a * x ^ 3 + b * x ^ 2 + c * x + d
- return tf.tidy(() => {
- return a.mul(x.pow(tf.scalar(3, 'int32')))
- .add(b.mul(x.square()))
- .add(c.mul(x))
- .add(d);
- });
- }
a.mul(x.pow(tf.scalar(3, 'int32')))就是描述了ax^3(a乘以x的三次方),b.mul(x.square()))描述了b x ^ 2(b乘以x的平方),c.mul(x)這些同理。注意,在predict函數return的時候,用tf.tidy包了起來,這是為了方便內存管理和優化機器訓練過程的內存。
定義損失函數(loss)
接下來我們要定義一個損失函數,使用的是MSE(均方誤差,mean squared error)。數理統計中均方誤差是指參數估計值與參數真值之差平方的期望值,記為MSE。MSE是衡量“平均誤差”的一種較方便的方法,MSE可以評價數據的變化程度,MSE的值越小,說明預測模型描述實驗數據具有更好的精確度。MSE的計算非常簡單,就是先根據給定的x得到實際的y值與預測得到的y值之差 的平方,然后在對這些差的平方求平均數即可。
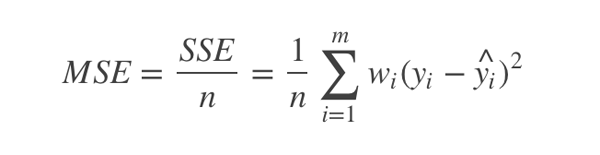
根據如上所述,我們的損失函數代碼如下:
- function loss(prediction, labels) {
- const error = prediction.sub(labels).square().mean();
- return error;
- }
預期值prediction減去實際值labels,然后平方后求平均數即可。
機器訓練(training)
好了,上面說了這么多,做了這么多的鋪墊和準備,終于到了最關鍵的步驟,下面這段代碼和函數就是真正的根據數據然后通過機器學習和訓練計算出我們想要的結果最重要的步驟。我們已經定義好了基于SGD隨機梯度下降的優化器optimizer,然后也定義了基于MSE均方誤差的損失函數,我們應該怎么結合他們兩個裝備去進行機器訓練和機器學習呢,看下面的代碼。
- const numIterations = 75;
- async function train(xs, ys, numIterations) {
- for (let iter = 0; iter < numIterations; iter++) {
- //優化器:SGD隨機梯度下降
- optimizer.minimize(() => {
- const pred = predict(xs);
- //損失函數:MSE均方誤差
- return loss(pred, ys);
- });
- //防止阻塞瀏覽器
- await tf.nextFrame();
- }
- }
我們在外層定義了一個numIterations = 75,意思是我們要進行75次機器訓練。在每一次循環中我們都調用了optimizer.minimize這個函數,它會不斷地調用SGD隨機梯度下降法來不斷地更新和修正我們的a、b、c、d這四個參數,并且每一次return的時候都會調用我們的基于MSE均方誤差loss損失函數來減小損失。經過這75次的機器訓練和機器學習,加上SGD隨機梯度下降優化器和loss損失函數進行校準,然后就會得到非常接近正確數值的a、b、c、d四個參數。
我們注意到這個函數末尾有一行tf.nextFrame(),這個函數是為了解決在機器訓練和機器學習的過程中會進行大量的機器運算,會阻塞瀏覽器,導致ui沒法更新的問題。
我們調用這個機器訓練的函數train:
- import {generateData} from './data';//這個文件在git倉庫里
- const trainingData = generateData(100, {a: -.8, b: -.2, c: .9, d: .5});
- await train(trainingData.xs, trainingData.ys, 75);
調用了train函數后,我們就可以拿到a、b、c、d四個參數了。
- console.log('a', a.dataSync()[0]);
- console.log('b', b.dataSync()[0]);
- console.log('c', c.dataSync()[0]);
- console.log('d', d.dataSync()[0]);
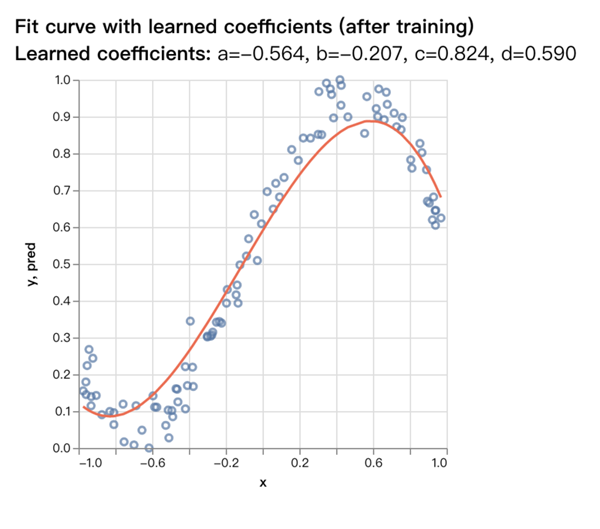
得到的值是a=-0.564, b=-0.207, c=0.824, d=0.590,和原先我們定義的實際值a=-0.8, b=-0.2, c=0.9, d=0.5非常的接近了,對比圖如下:
項目運行和安裝
本文涉及到的代碼安裝和運行步驟如下:
- git clone https://github.com/tensorflow/tfjs-examples
- cd tfjs-examples/polynomial-regression-core
- yarn
- yarn watch
tensorflow.js的官方example里有很多個項目,其中polynomial-regression-core(多項式方程回歸復原)這個例子就是我們本文重點講解的代碼,我在安裝的過程中并不太順利,每一次運行都會報缺少模塊的error,讀者只需要根據報錯,把缺少的模塊挨個安裝上,然后根據error提示信息上google去搜索相應的解決方法,都能運行起來。
結語
說了這么多,本來不想寫結語的,但是想想,還是想表達一下本人內心的一個搞笑荒謬的想法。我為什么會對這個人工智能的例子感興趣呢,是因為,在我廣西老家(一個偏遠的山村),那邊比較封建迷信,經常拿一個人的生辰八字就去計算并說出這個人一生的命運,balabala說一堆,本人對這些風氣一貫都是嗤之以鼻。但是,但是,但是。。。。荒謬的東西來了,我老丈人十早年前因為車禍而斷了一條腿,幾年前帶媳婦和老丈人回老家見親戚,老丈人覺得南方人這些封建迷信很好玩,就拿他自己的生辰八字去給鄉下的老者算了一下,結果那個老人說了很多,并說出了我老丈人出車禍的那一天的準確的日期,精確到那一天的下午大致時間。。。。。這。。。。這就好玩了。。。當年整個空氣突然安靜的場景至今歷歷在目,這件事一直記在心里,畢竟我從來不相信這些鬼鬼乖乖的東西,一直信奉科學是至高無上帶我們飛的真理。
咦?這跟人工智能有什么關系?我只是在思考,是不是我們每個人的生辰八字,就是笛卡爾平面坐標系上的維度,或者說生辰八字就是多項式函數的a、b、c、d、e系數,是不是真的有一個多項式函數方程能把這些生辰八字系數串聯起來得到一個公式,這個公式可以描述你的一生,記錄你的過去,并預測你的將來。。。。。。我們能不能找到自己對應的維度和發生過的事情聯系起來,然后用人工智能去機器學習并訓練出一個屬于我們自己一生命運軌跡的函數。。。。行 不說了 ,各位讀者能看到這里我也是覺得對不起你們,好好讀書并忘掉我說的話。
上述觀點純屬個人見解。!^_^!