













Linux問題故障定位,看這一篇就夠了
1. 背景
有時候會遇到一些疑難雜癥,并且監控插件并不能一眼立馬發現問題的根源。這時候就需要登錄服務器進一步深入分析問題的根源。那么分析問題需要有一定的技術經驗積累,并且有些問題涉及到的領域非常廣,才能定位到問題。所以,分析問題和踩坑是非常鍛煉一個人的成長和提升自我能力。如果我們有一套好的分析工具,那將是事半功倍,能夠幫助大家快速定位問題,節省大家很多時間做更深入的事情。
2. 說明
本篇文章主要介紹各種問題定位的工具以及會結合案例分析問題。
3. 分析問題的方法論
套用5W2H方法,可以提出性能分析的幾個問題
- What-現象是什么樣的
- When-什么時候發生
- Why-為什么會發生
- Where-哪個地方發生的問題
- How much-耗費了多少資源
- How to do-怎么解決問題
4. CPU
4.1 說明
針對應用程序,我們通常關注的是內核CPU調度器功能和性能。
線程的狀態分析主要是分析線程的時間用在什么地方,而線程狀態的分類一般分為:
a. on-CPU:執行中,執行中的時間通常又分為用戶態時間user和系統態時間sys。
b. off-CPU:等待下一輪上CPU,或者等待I/O、鎖、換頁等等,其狀態可以細分為可執行、匿名換頁、睡眠、鎖、空閑等狀態。
如果大量時間花在CPU上,對CPU的剖析能夠迅速解釋原因;如果系統時間大量處于off-cpu狀態,定位問題就會費時很多。但是仍然需要清楚一些概念:
- 處理器
- 核
- 硬件線程
- CPU內存緩存
- 時鐘頻率
- 每指令周期數CPI和每周期指令數IPC
- CPU指令
- 使用率
- 用戶時間/內核時間
- 調度器
- 運行隊列
- 搶占
- 多進程
- 多線程
- 字長
4.2 分析工具
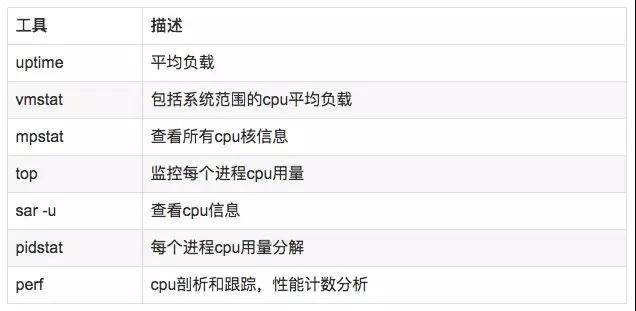
說明:
- uptime,vmstat,mpstat,top,pidstat只能查詢到cpu及負載的的使用情況。
- perf可以跟著到進程內部具體函數耗時情況,并且可以指定內核函數進行統計,指哪打哪。
4.3 使用方式
- //查看系統cpu使用情況
- top
- //查看所有cpu核信息
- mpstat -P ALL 1
- //查看cpu使用情況以及平均負載
- vmstat 1
- //進程cpu的統計信息
- pidstat -u 1 -p pid
- //跟蹤進程內部函數級cpu使用情況
- perf top -p pid -e cpu-clock
5. 內存
5.1 說明
內存是為提高效率而生,實際分析問題的時候,內存出現問題可能不只是影響性能,而是影響服務或者引起其他問題。同樣對于內存有些概念需要清楚:
- 主存
- 虛擬內存
- 常駐內存
- 地址空間
- OOM
- 頁緩存
- 缺頁
- 換頁
- 交換空間
- 交換
- 用戶分配器libc、glibc、libmalloc和mtmalloc
- LINUX內核級SLUB分配器
5.2 分析工具
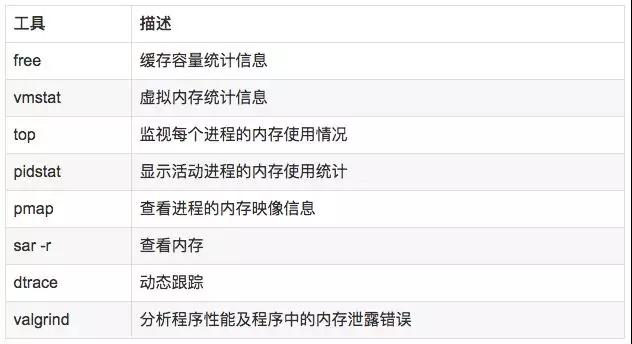
說明:
- free,vmstat,top,pidstat,pmap只能統計內存信息以及進程的內存使用情況。
- valgrind可以分析內存泄漏問題。
- dtrace動態跟蹤。需要對內核函數有很深入的了解,通過D語言編寫腳本完成跟蹤。
5.3 使用方式
- //查看系統內存使用情況
- free -m
- //虛擬內存統計信息
- vmstat 1
- //查看系統內存情況
- top
- //1s采集周期,獲取內存的統計信息
- pidstat -p pid -r 1
- //查看進程的內存映像信息
- pmap -d pid
- //檢測程序內存問題
- valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
6. 磁盤IO
6.1 說明
磁盤通常是計算機最慢的子系統,也是最容易出現性能瓶頸的地方,因為磁盤離 CPU 距離最遠而且 CPU 訪問磁盤要涉及到機械操作,比如轉軸、尋軌等。訪問硬盤和訪問內存之間的速度差別是以數量級來計算的,就像1天和1分鐘的差別一樣。要監測 IO 性能,有必要了解一下基本原理和 Linux 是如何處理硬盤和內存之間的 IO 的。
在理解磁盤IO之前,同樣我們需要理解一些概念,例如:
- 文件系統
- VFS
- 文件系統緩存
- 頁緩存page cache
- 緩沖區高速緩存buffer cache
- 目錄緩存
- inode
- inode緩存
- noop調用策略
6.2 分析工具
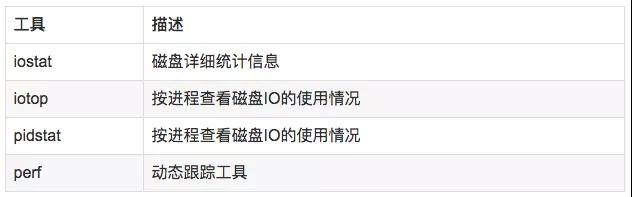
6.3 使用方式
- //查看系統io信息
- iotop
- //統計io詳細信息
- iostat -d -x -k 1 10
- //查看進程級io的信息
- pidstat -d 1 -p pid
- //查看系統IO的請求,比如可以在發現系統IO異常時,可以使用該命令進行調查,就能指定到底是什么原因導致的IO異常
- perf record -e block:block_rq_issue -ag
- ^C
- perf report
7. 網絡
7.1 說明
網絡的監測是所有 Linux 子系統里面最復雜的,有太多的因素在里面,比如:延遲、阻塞、沖突、丟包等,更糟的是與 Linux 主機相連的路由器、交換機、無線信號都會影響到整體網絡并且很難判斷是因為 Linux 網絡子系統的問題還是別的設備的問題,增加了監測和判斷的復雜度。現在我們使用的所有網卡都稱為自適應網卡,意思是說能根據網絡上的不同網絡設備導致的不同網絡速度和工作模式進行自動調整。
7.2 分析工具
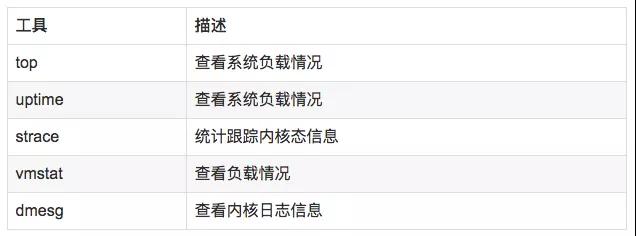
7.3 使用方式
- //顯示網絡統計信息
- netstat -s
- //顯示當前UDP連接狀況
- netstat -nu
- //顯示UDP端口號的使用情況
- netstat -apu
- //統計機器中網絡連接各個狀態個數
- netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
- //顯示TCP連接
- ss -t -a
- //顯示sockets摘要信息
- ss -s
- //顯示所有udp sockets
- ss -u -a
- //tcp,etcp狀態
- sar -n TCP,ETCP 1
- //查看網絡IO
- sar -n DEV 1
- //抓包以包為單位進行輸出
- tcpdump -i eth1 host 192.168.1.1 and port 80
- //抓包以流為單位顯示數據內容
- tcpflow -cp host 192.168.1.1
8. 系統負載
8.1 說明
Load 就是對計算機干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)簡單的說是進程隊列的長度。Load Average 就是一段時間(1分鐘、5分鐘、15分鐘)內平均Load。
8.2 分析工具
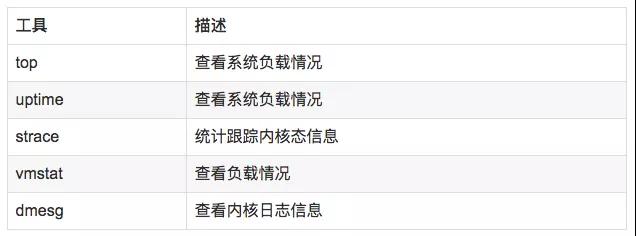
8.3 使用方式
- //查看負載情況
- uptime
- top
- vmstat
- //統計系統調用耗時情況
- strace -c -p pid
- //跟蹤指定的系統操作例如epoll_wait
- strace -T -e epoll_wait -p pid
- //查看內核日志信息
- dmesg
9. 火焰圖
9.1 說明
火焰圖(Flame Graph是 Bredan Gregg 創建的一種性能分析圖表,因為它的樣子近似 ?而得名。
火焰圖主要是用來展示 CPU的調用棧。
y 軸表示調用棧,每一層都是一個函數。調用棧越深,火焰就越高,頂部就是正在執行的函數,下方都是它的父函數。
x 軸表示抽樣數,如果一個函數在 x 軸占據的寬度越寬,就表示它被抽到的次數多,即執行的時間長。注意,x 軸不代表時間,而是所有的調用棧合并后,按字母順序排列的。
火焰圖就是看頂層的哪個函數占據的寬度***。只要有”平頂”(plateaus),就表示該函數可能存在性能問題。顏色沒有特殊含義,因為火焰圖表示的是 CPU 的繁忙程度,所以一般選擇暖色調。
常見的火焰圖類型有On-CPU、Off-CPU、Memory、Hot/Cold、Differential等等。
9.2 安裝依賴庫
- //安裝systemtap,默認系統已安裝
- yum install systemtap systemtap-runtime
- //內核調試庫必須跟內核版本對應,例如:uname -r 2.6.18-308.el5
- kernel-debuginfo-2.6.18-308.el5.x86_64.rpm
- kernel-devel-2.6.18-308.el5.x86_64.rpm
- kernel-debuginfo-common-2.6.18-308.el5.x86_64.rpm
- //安裝內核調試庫
- debuginfo-install --enablerepo=debuginfo search kernel
- debuginfo-install --enablerepo=debuginfo search glibc
9.3 安裝
- git clone https://github.com/lidaohang/quick_location.git
- cd quick_location
9.4 CPU級別火焰圖
cpu占用過高,或者使用率提不上來,你能快速定位到代碼的哪塊有問題嗎?
一般的做法可能就是通過日志等方式去確定問題。現在我們有了火焰圖,能夠非常清晰的發現哪個函數占用cpu過高,或者過低導致的問題。
9.4.1 on-CPU
cpu占用過高,執行中的時間通常又分為用戶態時間user和系統態時間sys。
使用方式:
- //on-CPU user
- sh ngx_on_cpu_u.sh pid
- //進入結果目錄
- cd ngx_on_cpu_u
- //on-CPU kernel
- sh ngx_on_cpu_k.sh pid
- //進入結果目錄
- cd ngx_on_cpu_k
- //開一個臨時端口8088
- python -m SimpleHTTPServer 8088
- //打開瀏覽器輸入地址
- 127.0.0.1:8088/pid.svg
DEMO:
- #include <stdio.h>
- #include <stdlib.h>
- void foo3()
- {
- }
- void foo2()
- {
- int i;
- for(i=0 ; i < 10; i++)
- foo3();
- }
- void foo1()
- {
- int i;
- for(i = 0; i< 1000; i++)
- foo3();
- }
- int main(void)
- {
- int i;
- for( i =0; i< 1000000000; i++) {
- foo1();
- foo2();
- }
- }
DEMO火焰圖:

9.4.2 off-CPU
CPU過低,利用率不高。等待下一輪CPU,或者等待I/O、鎖、換頁等等,其狀態可以細分為可執行、匿名換頁、睡眠、鎖、空閑等狀態。
使用方式:
- // off-CPU user
- sh ngx_off_cpu_u.sh pid
- //進入結果目錄
- cd ngx_off_cpu_u
- //off-CPU kernel
- sh ngx_off_cpu_k.sh pid
- //進入結果目錄
- cd ngx_off_cpu_k
- //開一個臨時端口8088
- python -m SimpleHTTPServer 8088
- //打開瀏覽器輸入地址
- 127.0.0.1:8088/pid.svg
官網DEMO:

9.5 內存級別火焰圖
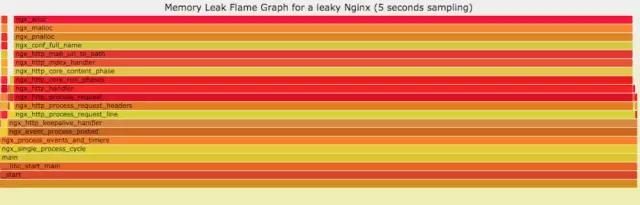
如果線上程序出現了內存泄漏,并且只在特定的場景才會出現。這個時候我們怎么辦呢?有什么好的方式和工具能快速的發現代碼的問題呢?同樣內存級別火焰圖幫你快速分析問題的根源。
使用方式:
- sh ngx_on_memory.sh pid
- //進入結果目錄
- cd ngx_on_memory
- //開一個臨時端口8088
- python -m SimpleHTTPServer 8088
- //打開瀏覽器輸入地址
- 127.0.0.1:8088/pid.svg
官網DEMO:
9.6 性能回退-紅藍差分火焰圖
你能快速定位CPU性能回退的問題么? 如果你的工作環境非常復雜且變化快速,那么使用現有的工具是來定位這類問題是很具有挑戰性的。當你花掉數周時間把根因找到時,代碼已經又變更了好幾輪,新的性能問題又冒了出來。主要可以用到每次構建中,每次上線做對比看,如果損失嚴重可以立馬解決修復。
通過抓取了兩張普通的火焰圖,然后進行對比,并對差異部分進行標色:紅色表示上升,藍色表示下降。 差分火焰圖是以當前(“修改后”)的profile文件作為基準,形狀和大小都保持不變。因此你通過色彩的差異就能夠很直觀的找到差異部分,且可以看出為什么會有這樣的差異。
使用方式:
- cd quick_location
- //抓取代碼修改前的profile 1文件
- perf record -F 99 -p pid -g -- sleep 30
- perf script > out.stacks1
- //抓取代碼修改后的profile 2文件
- perf record -F 99 -p pid -g -- sleep 30
- perf script > out.stacks2
- //生成差分火焰圖:
- ./FlameGraph/stackcollapse-perf.pl ../out.stacks1 > out.folded1
- ./FlameGraph/stackcollapse-perf.pl ../out.stacks2 > out.folded2
- ./FlameGraph/difffolded.pl out.folded1 out.folded2 | ./FlameGraph/flamegraph.pl > diff2.svg
DEMO:
- //test.c
- #include <stdio.h>
- #include <stdlib.h>
- void foo3()
- {
- }
- void foo2()
- {
- int i;
- for(i=0 ; i < 10; i++)
- foo3();
- }
- void foo1()
- {
- int i;
- for(i = 0; i< 1000; i++)
- foo3();
- }
- int main(void)
- {
- int i;
- for( i =0; i< 1000000000; i++) {
- foo1();
- foo2();
- }
- }
- //test1.c
- #include <stdio.h>
- #include <stdlib.h>
- void foo3()
- {
- }
- void foo2()
- {
- int i;
- for(i=0 ; i < 10; i++)
- foo3();
- }
- void foo1()
- {
- int i;
- for(i = 0; i< 1000; i++)
- foo3();
- }
- void add()
- {
- int i;
- for(i = 0; i< 10000; i++)
- foo3();
- }
- int main(void)
- {
- int i;
- for( i =0; i< 1000000000; i++) {
- foo1();
- foo2();
- add();
- }
- }
DEMO紅藍差分火焰圖:

10. 案例分析
10.1 接入層nginx集群異常現象
通過監控插件發現在2017.09.25 19點nginx集群請求流量出現大量的499,5xx狀態碼。并且發現機器CPU使用率升高,目前一直持續中。
10.2 分析nginx相關指標
a) **分析nginx請求流量:
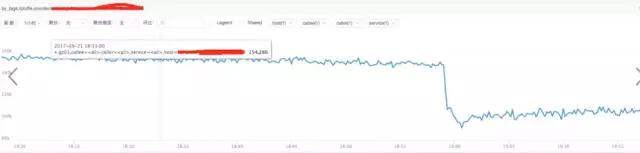
結論:
通過上圖發現流量并沒有突增,反而下降了,跟請求流量突增沒關系。
b) **分析nginx響應時間
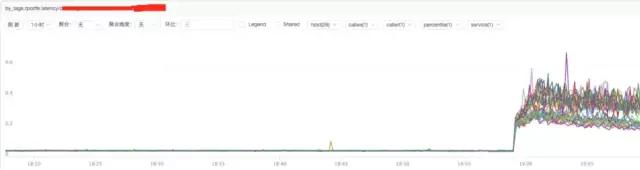
結論:
通過上圖發現nginx的響應時間有增加可能跟nginx自身有關系或者跟后端upstream響應時間有關系。
c) **分析nginx upstream響應時間
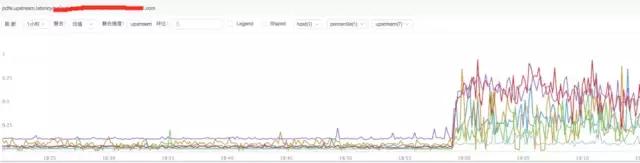
結論:
通過上圖發現nginx upstream 響應時間有增加,目前猜測可能后端upstream響應時間拖住nginx,導致nginx出現請求流量異常。
10.3 分析系統CPU情況
a) **通過top觀察系統指標
- top
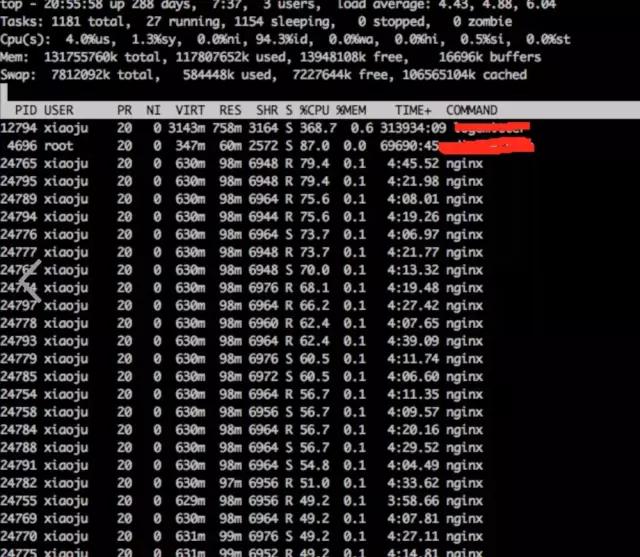
結論:
發現nginx worker cpu比較高
b) **分析nginx進程內部cpu情況
- perf top -p pid
結論:
發現主要開銷在free,malloc,json解析上面
10.4 火焰圖分析CPU
a) **生成用戶態CPU火焰圖
- //on-CPU user
- sh ngx_on_cpu_u.sh pid
- //進入結果目錄
- cd ngx_on_cpu_u
- //開一個臨時端口8088
- python -m SimpleHTTPServer 8088
- //打開瀏覽器輸入地址
- 127.0.0.1:8088/pid.svg
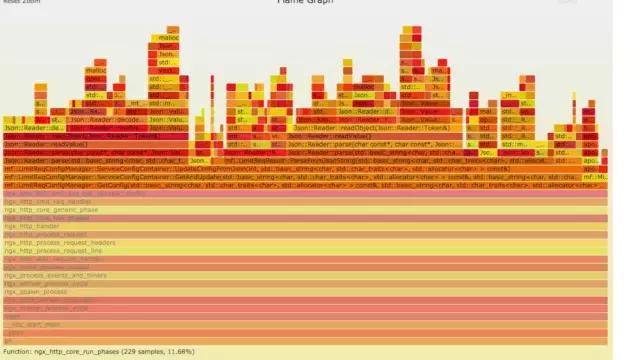
結論:
發現代碼里面有頻繁的解析json操作,并且發現這個json庫性能不高,占用CPU挺高。
10.5 案例總結
a) 分析請求流量異常,得出nginx upstream后端機器響應時間拉長。
b) 分析nginx進程cpu高,得出nginx內部模塊代碼有耗時的json解析以及內存分配回收操作。
10.5.1 深入分析
根據以上兩點問題分析的結論,我們進一步深入分析。
后端upstream響應拉長,最多可能影響nginx的處理能力。但是不可能會影響nginx內部模塊占用過多的cpu操作。并且當時占用cpu高的模塊,是在請求的時候才會走的邏輯。不太可能是upstram后端拖住nginx,從而觸發這個cpu的耗時操作。
10.5.2 解決方式
遇到這種問題,我們優先解決已知的,并且非常明確的問題。那就是cpu高的問題。解決方式先降級關閉占用cpu過高的模塊,然后進行觀察。經過降級關閉該模塊cpu降下來了,并且nginx請求流量也正常了。之所以會影響upstream時間拉長,因為upstream后端的服務調用的接口可能是個環路再次走回到nginx。
11.參考資料
http://www.brendangregg.com/index.html
http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
http://www.brendangregg.com/FlameGraphs/memoryflamegraphs.html
http://www.brendangregg.com/FlameGraphs/offcpuflamegraphs.html
http://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html
https://github.com/openresty/openresty-systemtap-toolkit
https://github.com/brendangregg/FlameGraph
https://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs






















