一篇運維老司機的大數據平臺監控寶典(2)-聯通大數據集群平臺監控體系詳解
在上一篇文章【一篇運維老司機的大數據平臺監控寶典(1)】中,我們介紹了目前聯通大數據監控平臺由Grafana+Influxdb+Prometheus+Alertmanager等組件組成,并且著重詳述了以Grafana為核心的圖形化展示功能。
本文繼續針對運維監控體系的另一重要內容,即告警分析、處理及發送功能進行分享。
一、為什么要選擇Prometheus+Alertmanager
你的監控系統是否曾面臨這些痛點:
- 告警信息推送無法分類,無法針對某部分人進行特定告警
- 重復告警或無用告警過多,重要告警易被埋沒
- 監控系統無法提供可視化展示,或僅能部分展示
- 監控歷史數據不能二次查詢或多維度查詢,故障排查缺少依據
對于業務量、平臺主機量級較大的公司來說,使用以nagios+ganglia為首的傳統的監控平臺往往會遇到以上情況,顯得力不從心。經過大量、豐富的實戰工作后,我們***選擇Prometheus+Alertmanager+釘釘的搭配作為聯通大數據監控平臺的告警分析、處理及發送工具組合。這套組合不僅能夠針對以上痛點一一解決,也可以說是運維人員保障集群平臺穩定運行、故障排查、問題定位的一把利器。
在下面的章節中,筆者會對系統中的Prometheus、Alertmanager等組件逐一進行介紹。
二、Prometheus-數據存儲及分析
1. Prometheus簡介
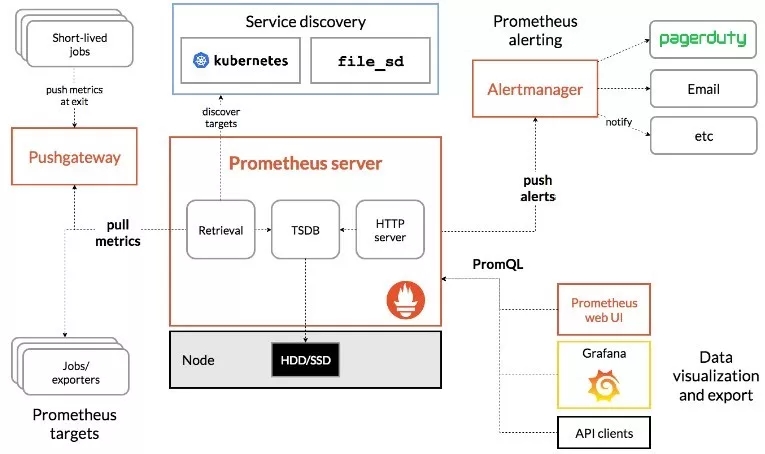
基于上圖,大家可以清晰的看到,Prometheus實際上是一個tsdb型數據庫,所有的采集數據以metric的形式保存在其中,且能夠將數據落到本地磁盤中,供使用人員二次查詢數據。
Prometheus同時附加了強大的計算與分析功能,能夠利用各種labels與promql語句來完成多維度的監控數據查詢,從而為故障排查與問題定位提供可靠的證據。
監控規則方面,Prometheus可以根據promql來獲取數據,并且與固定閾值進行計算比較,若超出正常范圍,則標記為告警信息,并且可以分組分標簽定義告警描述,供后續Alertmanager使用。
在拓展性方面,Prometheus可以輕松的完成服務發現功能,并擁有每秒上萬數據點的監控數據收集與分析的處理能力,完全擺脫了傳統監控系統對監控主機數量的要求。目前聯通大數據平臺機器幾千余臺,監控實例過十萬,監控實例指標過千萬,Prometheus優良的性能可以做到***支撐。
2. Prometheus特點
(1) 監控數據存儲功能及多維度查詢
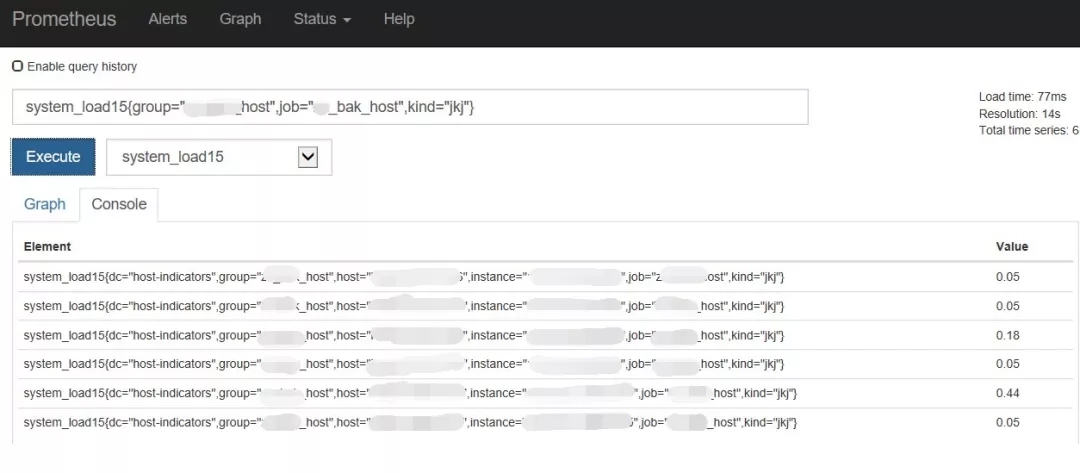
下圖中以一個簡單例子說明:該條查詢可以看到某集群接口機15分鐘內的系統負載,涉及到的標簽維度為集群、主機IP、主機類型等。在實際線上環境中,還可以添加多個標簽來完成查詢,并且可以利用promql特有的查詢語句(sum、count_values、topk等)來完成更加豐富的多維度查詢,提供可靠、便捷、直觀的監控數據供運維人員使用。
(2) 優秀的自定義及第三方監控拓展功能
Pushgateway是Prometheus環境中的一個data_collector。把它定義為采集者的原因很簡單,標準的Prometheus會采用pull模式從target中獲取監控數據,但當由于外力原因(如網絡、硬件等)無法直接從target中拉取數據時,就要依靠Pushgateway了,請看下圖:

大致流程為client上部署的腳本(支持多語言shell、python等)會收集target中的數據,并且以metric形式傳送到Pushgateway中,只要保證client和Pushgateway能夠正常通信即可。Prometheus會按照配置時間,定時到Pushgateway上拉取監控數據,從而達到收集target的目的。
下圖為Pushgetway發送數據的代碼過程:
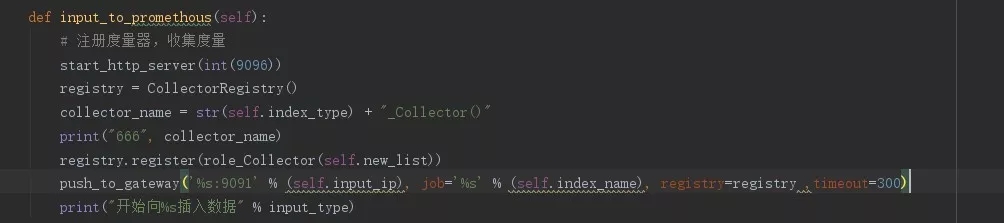
那么是否可以這么理解:對于常見組件(redis、mysql、nginx、haproxy等),我們可以依靠現有的豐富client庫,直接進行監控納管;對于一些特殊組件或自定義業務,可通過多語言腳本采集監控數據或業務埋點方式,把Pushgateway作為一個data_collector來收集各方數據,從而完成監控納管。
(3) 良好的監控生態圈之常見client庫
由于近年Prometheus的興起,開源社區中越來越多的人將自己的代碼貢獻出來,使得Prometheus擁有龐大的client庫(redis、mysql、nginx、haproxy等),運維人員可以利用這些client實現即開即用即監控的功能。
3. 配置
- global:
- scrape_interval: 15s
- evaluation_interval: 15s
- # scrape_timeout is set to the global default (10s).
- # Alertmanager configuration
- alerting:
- alertmanagers:
- - static_configs:
- - targets: ['IP:9093']
- rule_files:
- # - "first_rules.yml"
- # - "second_rules.yml"
- # A scrape configuration containing exactly one endpoint to scrape:
- - job_name: 'prometheus'
- scrape_interval: 15s
- static_configs:
- - targets: ['localdns:9090']
三、Alertmanager-告警的分類搬運工
1. Alertmanager簡介
Alertmanager在監控系統中的定位是接收Prometheus發送來的告警,并逐一按照配置中route進行分類,并且通過silencing、inhibition的規則計算,最終得到有效告警信息,通過郵件、釘釘、微信等方式發送給各類業務人群。
2. Alertmanager特點
(1) 分組
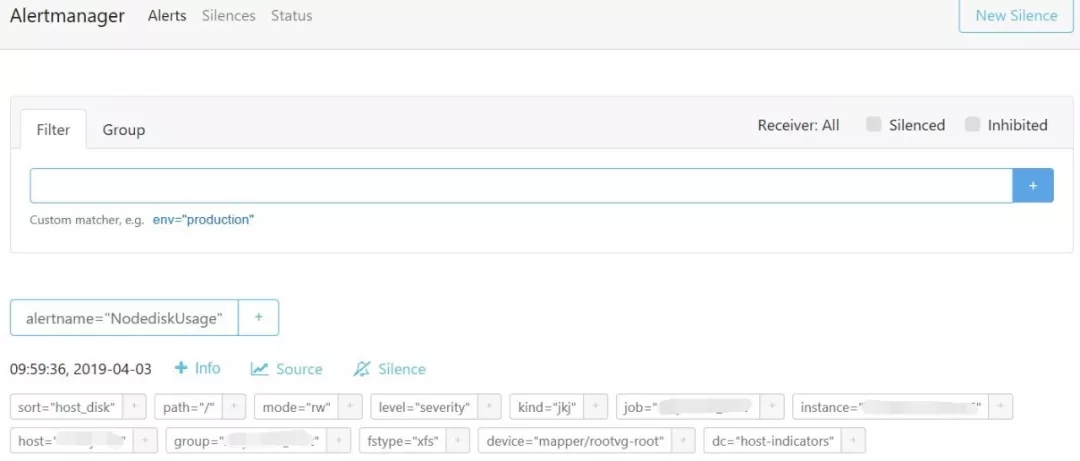
可以用一個業務場景來解釋該特點:某大數據集群由于網絡問題大面積癱瘓,上百個datanode觸發斷開告警,如果按照傳統監控模式的話,收到的將是上百條的告警短信形成短信轟炸。但如果使用分組特性,Alertmanager會將具有共同屬性的告警歸為一條發送到接收端,清晰明了。
(2) 抑制
還是用業務場景來解釋該特點:某主機上運行了一個mysql實例,若該主機宕機,則會收到多條關于mysql各項監控的告警信息,但如果配置了抑制用法,只要觸發該主機的宕機告警,上面mysql所觸發的告警便會被抑制掉。
(3) 沉默
舉例來說,某主機硬件主板損壞,但廠商反饋要2天后才能更換主板,一般情況下在更換主板前,該警報會一直大量重復發送。如果此時利用沉默功能,在頁面上配置沉默選項即可暫停此告警,待修復完成后取消沉默規則即可。
3. 配置
- global:
- resolve_timeout: 5m
- templates:
- - 'template/*.tmpl'
- route:
- group_by: ['cluster']
- group_wait: 10s
- group_interval: 20s
- repeat_interval: 30m
- receiver: 'host'
- routes:
- ###############example####################
- - receiver: 'example'
- match:
- cluster: example
- continue: true
- - name: 'example'
- webhook_configs:
- - url: 'http://localhost:8180/dingtalk/ops_dingding/send'
- inhibit_rules:
- - source_match:
- - source_match_re:
- target_match_re:
- equal: ['ipAddress']
四、釘釘-最終告警接收查閱
運維人員常用的發送告警工具有短信、郵件、企業微信和釘釘,之所以選擇釘釘的原因如下:
- 短信:一般是通過往oracle插入告警信息走短信網關發送;優點是及時高效,但缺點是oracle支持的并發量有限。
- 郵件:郵件告警的及時性是一個很大的問題,并且如果沒有合理設置閾值,郵件轟炸會影響其他工作郵件的閱讀。
- 企業微信:企業微信不存在短信網關的并發限制,但弊端在于告警條數有限。
- 釘釘:有強大的分組功能且不限制告警條數;可按項目創建告警群,也方便解除。
使用釘釘作為告警接收工具,簡單來說就是在釘釘群聊中配置機器人,每個機器人會有一條唯一的webhook,當接收到來自Alertmanager的告警后就可以發送到手機端。本文不再詳述釘釘機器人的配置,感興趣的同學可以自行到網上查閱資料。
五、補充知識點
作為運維人員,做得最多的工作就是日常巡檢、故障恢復。公司集群規模越龐大,故障發生率和故障實例數也會成倍增加,相信每個運維人都體會過節假日被臨時召喚修復故障的經歷。這里,筆者額外貢獻一條“自動化恢復”小貼士,解放隨時等待召喚的運維er,你值得擁有:
自動化簡易流程:通過采集分析Prometheus里的告警數據,利用fabric或ansible等多線程安全并發遠程連接工具,執行相關角色實例的恢復工作。
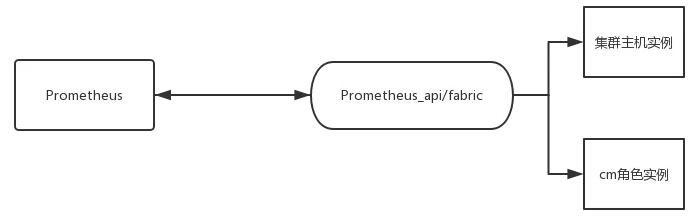
Fabric建立連接執行恢復命令。

目前自動化恢復涉及的集群日常運維操作有:
- 計算節點檢測出使用swap交換分區,將會自動清理swap分區,并關閉swap分區。
- 計算節點檢測出時鐘偏差,將會自動糾偏時鐘偏差。
- cloudera manager代理掛掉,將會自動重啟。
- 主機檢測出有壞盤,壞盤更換完成后,自動恢復。
- 角色實例檢測出異常掉線,自動恢復上線。
- 集群存在多個節點多塊磁盤存儲剩余空間不足,自動進行磁盤級別的數據balancer。
- 集群存儲達到閾值,自動進行節點級別的數據balancer。
需要提示的是,自動化恢復的適用場景很多,但并不適用于罕見故障且該故障有一定概率會影響到平臺部分功能性能的情況,建議大家使用前嚴謹權衡、對癥下藥。
【本文是51CTO專欄機構中國聯通大數據的原創文章,微信公眾號“中國聯通大數據( id: unibigdata)”】