













熱點 | 大三學生獨自破解逆天AI模型
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
GPT-2,一個逆天的 AI。
今年 2 月,OpenAI 首次對外公布了這個模型的存在。GPT-2 寫起文章來文思泉涌毫無違和感,無需針對性訓練就能橫掃各種特定領域的語言建模任務,還具備閱讀理解、問答、生成文章摘要、翻譯等等能力。
但不同尋常的是,這個模型并沒有真的開源。OpenAI 給的解釋是,它太過強大,我們不敢放出完整模型……盡管因此被外界嘲笑,但 GPT-2 仍然封閉至今。
現在,有人單槍匹馬,破解了 OpenAI 不欲人知的秘密。
而且,是一個大三的學生。
來自慕尼黑工業大學的 Connor Leahy 同學,在兩個月的時間里,付出了 200 個小時的時間,花費了大約 6000 人民幣,復現了 GPT-2 項目。
這件事在推特上引發了眾多關注。稱贊 Awesome 的有之,深入討論的有之,甚至連 OpenAI 的幾位資深研究員,都趕來溝通。
另外讓人佩服的是,Connor Leahy 同學關于機器學習的知識,都是利用空閑時間自學而成。他形容自己是一個充滿好奇心的本科生。
“我只是把別人出去撩妹的時間,用來搞 AI 實驗了而已。”
一氣之下
GPT-2 是 OpenAI 最棒的研究成果。
這個模型是 GPT 的“進化版”,最大區別就在于規模大小。GPT-2 參數達到了 15 億個,使用了包含 800 萬個網頁的數據集來訓練,共有 40GB。
使用語言建模作為訓練信號,以無監督的方式在大型數據集上訓練一個 Transformer,然后在更小的監督數據集上微調這個模型,以幫助它解決特定任務。
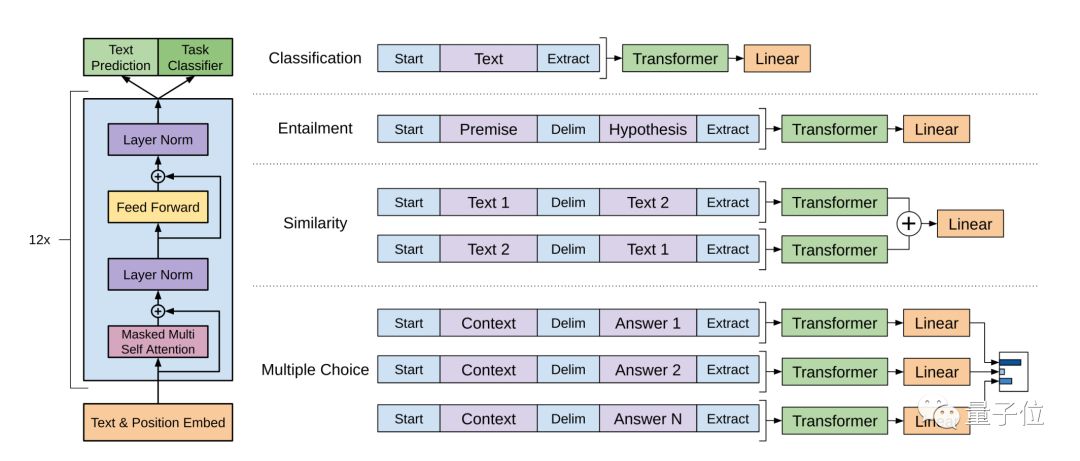
GPT 模型
OpenAI 的研究人員表示,在各種特定領域數據集的語言建模測試中,GPT-2 都取得了優異的分數。作為一個沒有經過任何領域數據專門訓練的模型,它的表現,比那些專為特定領域打造的模型還要好。
除了能用于語言建模,GPT-2 在問答、閱讀理解、摘要生成、翻譯等等任務上,無需微調就能取得非常好的成績。
GPT-2 發布后,深度學習之父 Hinton 獻出了他注冊 Twitter 以來的第三次評論:“這應該能讓硅谷的獨角獸們生成更好的英語了。”
關于這個模型的強大表現,可以參考量子位之前的報道,這里不再贅述。
總之,就是一個字:強。
就是因為強,OpenAI 做了一個艱難的決定:不把完整的模型放出來給大家。他們先是放出了不到十分之一規模、1.17 億個參數的小型版本,被吐槽幾個月后又放出了 3.45 億參數的中型版本。
毫無疑問,GPT-2 激發了 Connor Leahy 同學的好奇心,同時,OpenAI 私藏這個模型的決定,也讓他非常生氣。“信息應該是自由的。”
于是他決定自己動手復現出來。
他不只是因為一時沖動。對于為什么要復現 GPT-2,Connor Leahy 同學在自己的博客里有長長的思考,其中包括與其害怕 AI 編造的假新聞,不如積極行動起來,讓大家意識到這個問題,勇敢面對然后想辦法解決。
當然還有另一個原因,他覺得這么做:
很酷。
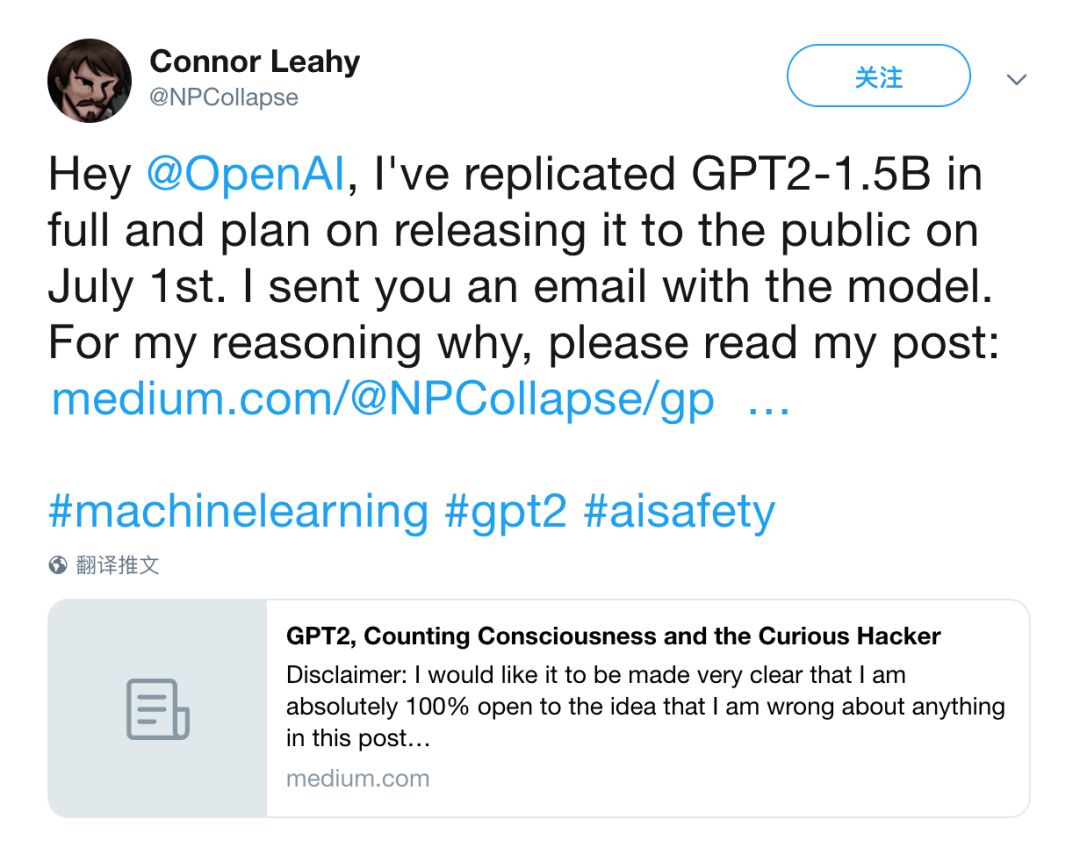
復現版 GPT-2
“你怎么知道自己成功復現了 15 億參數的 GPT-2 模型?”
這個問題,恐怕絕大多數人都想知道答案。
Connor Leahy 同學給出的回應是:兩個模型的大小和參數量相同,基于相似的數據源訓練,使用了類似的計算資源,而且輸出結果質量相仿。
他也給出了兩者的一些明確不同,比方:
1、dropout 和 learning rate 官方沒有披露,所以設置可能不一樣。
2、模型訓練使用了 Adafactor 而不是 Adam。Connor Leahy 同學不知道怎么把 15 億參數 +Adam 塞進 TPU,即便 16bit 精度也不行。
哎?等下……
一個普普通通的大三學生,怎么能用到 TPU 搞這種研究?
感謝 Google。
Google 有一個 Tensorflow Research Cloud(TFRC)計劃。這個計劃面向研究人員,提供 1000 個 Cloud TPU 組成的集群,完全免費。這個計劃用于支持多種需要大量計算并且無法通過其他途徑實現的研究項目。

當時 Connor Leahy 同學在研究 GPT-2 復現的時候,遇到了計算資源的瓶頸,然后隨口跟 TFRC 團隊提了一嘴,結果卻得到了 Google 慷慨的支持。
實際上,在推進這個項目之前,Connor Leahy 同學從來沒有使用過 TPU。所以,他在博客中熱情的對 Google 團隊表達了感謝。
不過,他還是在云端花費了大約 600-800 歐元(人民幣 6000 元左右),用于創建數據集、測試代碼和運行實驗。
他用的筆記本是一臺舊的 ThinkPad。
Connor Leahy 同學還對降噪耳機表達了感謝:讓我保持寧靜。
目前,復現版的 GPT-2 已經放在 GitHub 上開源,代碼可以在 GPU、TPU 以及 CPU 上跑(不建議)。現在作者放出了兩個版本,一個是 1.17 億參數的小型版本,一個是稱為 PrettyBig 的版本,比 3.45 億參數的官方中型版稍大一點,也是目前公開的最大 GPT-2 模型。
至于 15 億參數的完整版,作者計劃 7 月 1 日發布。
現階段,Connor Leahy 同學邀請大家下載試用,跟他一起討論復現版 GPT-2 到底還有什改進空間。在關于這件的博客文章里,他說:我 100% 能接受大家指出的任何錯誤,如果你發現問題請與我聯系。
關于作者和傳送門
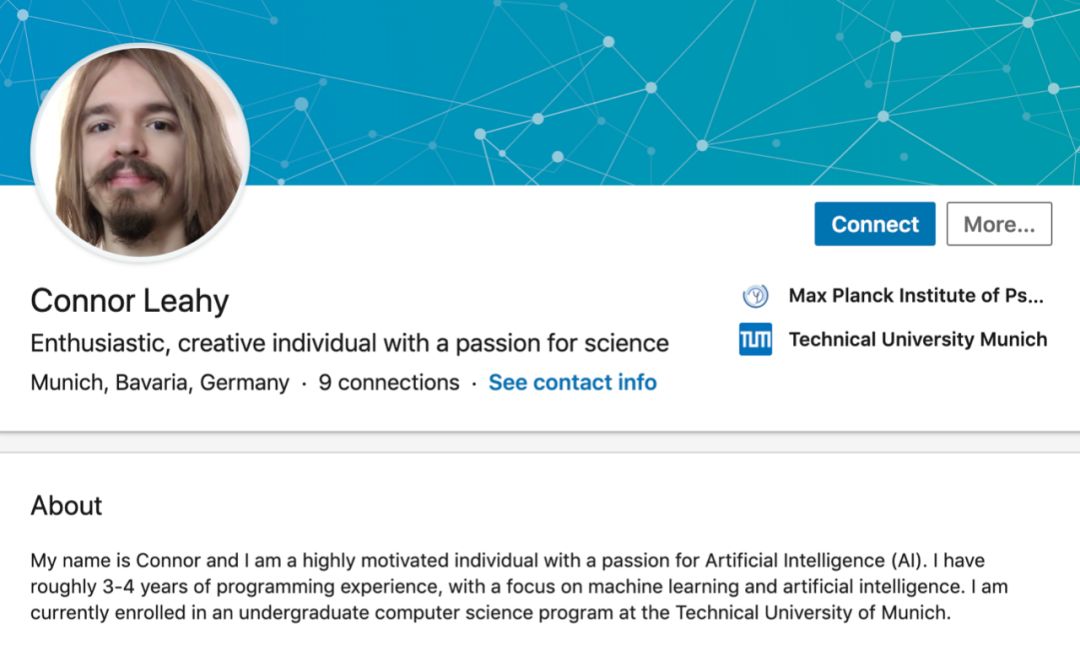
Connor Leahy 同學 2017 年考入德國慕尼黑工業大學,目前是一名大三的計算機本科學生。在 LinkedIn 上,他說自己對人工智能充滿熱情。
從 2018 年 9 月迄今,他還在馬克思普朗克研究所實習,也在用來自 Google 的 TPU,研究正經的 AI 課題。
最后,放一下傳送門。
Connor Leahy 同學充滿思考的博客:
https://medium.com/@NPCollapse/gpt2-counting-consciousness-and-the-curious-hacker-323c6639a3a8
與他在 GitHub 相見吧:
https://github.com/ConnorJL/GPT2


















