詳解JVM運行原理及Stack和Heap的實現過程
概述
因為線上系統遇到CPU100%的問題,這種問題在流量較大時比較常見,因為JDK自身有很多JVM調試工具,如jps、jstack、jmap、jhat、jstat等使用工具,在實際工作中使用這些工具進行調試是十分必要的,一般通過上面工具就能定位并解決CPU100%的問題。
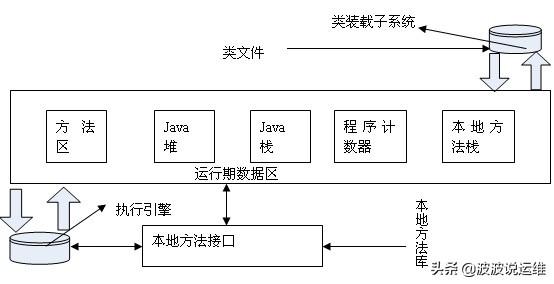
實際上Java語言寫的源程序是通過Java編譯器,編譯成與平臺無關的‘字節碼程序’(.class文件,也就是0,1二進制程序),然后在OS之上的Java解釋器中解釋執行,而JVM是java的核心和基礎,在java編譯器和os平臺之間的虛擬處理器。所以理解JVM運行原理是很有必要的。
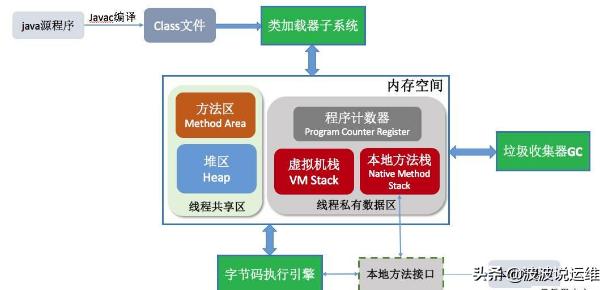
JVM原理
1. JVM簡介
JVM是java的核心和基礎,在java編譯器和os平臺之間的虛擬處理器。它是一種利用軟件方法實現的抽象的計算機基于下層的操作系統和硬件平臺,可以在上面執行java的字節碼程序。
java編譯器只要面向JVM,生成JVM能理解的代碼或字節碼文件。Java源文件經編譯成字節碼程序,通過JVM將每一條指令翻譯成不同平臺機器碼,通過特定平臺運行。
2. Java語言運行的過程
Java語言寫的源程序通過Java編譯器,編譯成與平臺無關的‘字節碼程序’(.class文件,也就是0,1二進制程序),然后在OS之上的Java解釋器中解釋執行。

3. JVM執行程序的過程
- I. 加載class文件。
- II. 管理并分配內存。
- III. 執行垃圾收集。
JRE(java運行時環境)由JVM構造的java程序的運行環境
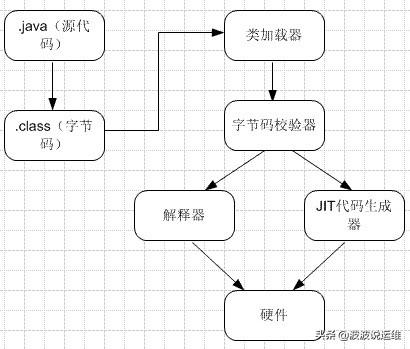
JVM中的Stack和Heap
在JVM中,內存分為兩個部分,Stack(棧)和Heap(堆),這里,我們從JVM的內存管理原理的角度來認識Stack和Heap,并通過這些原理認清Java中靜態方法和靜態屬性的問題。
1. 簡介
Stack(棧)是JVM的內存指令區。Stack管理很簡單,push一定長度字節的數據或者指令,Stack指針壓棧相應的字節位移;pop一定字節長度數據或者指令,Stack指針彈棧。Stack的速度很快,管理很簡單,并且每次操作的數據或者指令字節長度是已知的。所以Java基本數據類型,Java指令代碼,常量都保存在Stack中。
Heap(堆)是JVM的內存數據區。Heap的管理很復雜,每次分配不定長的內存空間,專門用來保存對象的實例。在Heap中分配一定的內存來保存對象實例,實際上也只是保存對象實例的屬性值,屬性的類型和對象本身的類型標記等,并不保存對象的方法(方法是指令,保存在Stack中),在Heap中分配一定的內存保存對象實例和對象的序列化比較類似。而對象實例在Heap中分配好以后,需要在Stack中保存一個4字節的Heap內存地址,用來定位該對象實例在Heap中的位置,便于找到該對象實例。
下圖為JVM的體系結構:
2. 什么是數據、什么是指令,對象的方法和對象的屬性又是什么?
1)方法本身是指令的操作碼部分,保存在Stack中;
2)方法內部變量作為指令的操作數部分,跟在指令的操作碼之后,保存在Stack中(實際上是簡單類型保存在Stack中,對象類型在Stack中保存地址,在Heap 中保存值);上述的指令操作碼和指令操作數構成了完整的Java指令。
3)對象實例包括其屬性值作為數據,保存在數據區Heap中。
非靜態的對象屬性作為對象實例的一部分保存在Heap中,而對象實例必須通過Stack中保存的地址指針才能訪問到。因此能否訪問到對象實例以及它的非靜態屬性值完全取決于能否獲得對象實例在Stack中的地址指針。
在JVM中,靜態屬性保存在Stack指令內存區,動態屬性保存在Heap數據內存區。
總結:
1)棧是運行時的單位,而堆是存儲的單位。
2)棧解決程序的運行問題,即程序如何執行,或者說如何處理數據;堆解決的是數據存儲的問題,即數據怎么放、放在哪兒。
4. 為什么要把堆和棧區分出來呢?
***,從軟件設計的角度看,棧代表了處理邏輯,而堆代表了數據。這樣分開,使得處理邏輯更為清晰。分而治之的思想。這種隔離、模塊化的思想在軟件設計的方方面面都有體現。
第二,堆與棧的分離,使得堆中的內容可以被多個棧共享(也可以理解為多個線程訪問同一個對象)。這種共享的收益是很多的。一方面這種共享提供了一種有效的數據交互方式(如:共享內存),另一方面,堆中的共享常量和緩存可以被所有棧訪問,節省了空間。
第三,棧因為運行時的需要,比如保存系統運行的上下文,需要進行地址段的劃分。由于棧只能向上增長,因此就會限制住棧存儲內容的能力。而堆不同,堆中的對象是可以根據需要動態增長的,因此棧和堆的拆分,使得動態增長成為可能,相應棧中只需記錄堆中的一個地址即可。
第四,面向對象就是堆和棧的***結合。其實,面向對象方式的程序與以前結構化的程序在執行上沒有任何區別。但是,面向對象的引入,使得對待問題的思考方式發生了改變,而更接近于自然方式的思考。當我們把對象拆開,你會發現,對象的屬性其實就是數據,存放在堆中;而對象的行為(方法),就是運行邏輯,放在棧中。我們在編寫對象的時候,其實即編寫了數據結構,也編寫的處理數據的邏輯。
程序要運行總是有一個起點的。同C語言一樣,java中的Main就是那個起點。無論什么java程序,找到main就找到了程序執行的入口
5. 堆中存什么?棧中存什么?
1)堆中存的是對象。棧中存的是基本數據類型和堆中對象的引用。一個對象的大小是不可估計的,或者說是可以動態變化的,但是在棧中,一個對象只對應了一個4btye的引用。
2)為什么不把基本類型放堆中呢?因為其占用的空間一般是1~8個字節——需要空間比較少,而且因為是基本類型,所以不會出現動態增長的情況——長度固定,因此棧中存儲就夠了,如果把他存在堆中是沒有什么意義的(還會浪費空間,后面說明)。可以這么說,基本類型和對象的引用都是存放在棧中,而且都是幾個字節的一個數,因此在程序運行時,他們的處理方式是統一的。但是基本類型、對象引用和對象本身就有所區別了,因為一個是棧中的數據一個是堆中的數據。最常見的一個問題就是,Java中參數傳遞時的問題。
3)Java中的參數傳遞時傳值呢?還是傳引用?程序運行永遠都是在棧中進行的,因而參數傳遞時,只存在傳遞基本類型和對象引用的問題。不會直接傳對象本身。
Java在方法調用傳遞參數時,因為沒有指針,所以它都是進行傳值調用
PS:堆和棧中,棧是程序運行最根本的東西。程序運行可以沒有堆,但是不能沒有棧。而堆是為棧進行數據存儲服務,說白了堆就是一塊共享的內存。不過,正是因為堆和棧的分離的思想,才使得Java的垃圾回收成為可能。
深入理解JVM原理對于我們平時調試問題還是很有幫助的,運維不僅僅是學一些Linux命令就可以的,如果要往深方面研究的話很多時候開發的東西要需要會一點的。