













直接上手!Redis在海量數據和高并發下的優化實踐
Redis 對于從事互聯網技術工程師來說并不陌生,幾乎所有的大中型企業都在使用 Redis 作為緩存數據庫。
但是對于絕大多數企業來說只會用到它的最基礎的 KV 緩存功能,還有很多 Redis 的高級功能可能都未曾認真實踐過。
來自掌閱的工程師錢文品將為大家帶來:《Redis 在海量數據和高并發下的優化實踐》的主題分享。
他將圍繞 Redis 分享在平時的日常業務開發中遇到的 9 個經典案例,希望通過此次分享可以幫助大家更好的將 Redis 的高級特性應用到日常的業務開發中來。
掌閱電子書閱讀軟件 ireader 的總用戶量大概是 5 億左右,月活 5000 萬,日活近 2000 萬 。服務端有 1000 多個 Redis 實例,100+ 集群,每個實例的內存控制在 20G 以下。
KV 緩存
第一個是最基礎,也是最常用的就是 KV 功能,我們可以用 Redis 來緩存用戶信息、會話信息、商品信息等等。
下面這段代碼就是通用的緩存讀取邏輯:
- def get_user(user_id):
- user = redis.get(user_id)
- if not user:
- user = db.get(user_id)
- redis.setex(user_id, ttl, user) // 設置緩存過期時間
- return user
- def save_user(user):
- redis.setex(user.id, ttl, user) // 設置緩存過期時間
- db.save_async(user) // 異步寫數據庫
這個過期時間非常重要,它通常會和用戶的單次會話長度成正比,保證用戶在單次會話內盡量一直可以使用緩存里面的數據。
當然如果貴公司財力雄厚,又極其注重性能體驗,可以將時間設置的長點甚至干脆就不設置過期時間。當數據量不斷增長時,就使用 Codis 或者 Redis-Cluster 集群來擴容。
除此之外 Redis 還提供了緩存模式,Set 指令不必設置過期時間,它也可以將這些鍵值對按照一定的策略進行淘汰。
打開緩存模式的指令是:config set maxmemory 20gb ,這樣當內存達到 20GB 時,Redis 就會開始執行淘汰策略,給新來的鍵值對騰出空間。
這個策略 Redis 也是提供了很多種,總結起來這個策略分為兩塊:劃定淘汰范圍,選擇淘汰算法。
比如我們線上使用的策略是 Allkeys-lru。這個 Allkeys 表示對 Redis 內部所有的 Key 都有可能被淘汰,不管它有沒有帶過期時間,而 Volatile 只淘汰帶過期時間的。
Redis 的淘汰功能就好比企業遇到經濟寒冬時需要勒緊褲腰帶過冬進行一輪殘酷的人才優化。
它會選擇只優化臨時工呢,還是所有人一律平等都可能被優化。當這個范圍圈定之后,會從中選出若干個名額,怎么選擇呢,這個就是淘汰算法。
最常用的就是 LRU 算法,它有一個弱點,那就是表面功夫做得好的人可以逃過優化。
比如你乘機趕緊在老板面前好好表現一下,然后你就安全了。所以到了 Redis 4.0 里面引入了 LFU 算法,要對平時的成績也進行考核,只做表面功夫就已經不夠用了,還要看你平時勤不勤快。
最后還有一種極不常用的算法:隨機搖號算法。這個算法有可能會把 CEO 也給淘汰了,所以一般不會使用它。
分布式鎖
下面我們看第二個功能:分布式鎖,這個是除了 KV 緩存之外最為常用的另一個特色功能。
比如一個很能干的資深工程師,開發效率很快,代碼質量也很高,是團隊里的明星。所以諸多產品經理都要來煩他,讓他給自己做需求。
如果同一時間來了一堆產品經理都找他,他的思路呢就會陷入混亂,再優秀的程序員,大腦的并發能力也好不到哪里去。
所以他就在自己的辦公室的門把上掛了一個請勿打擾的牌子,當一個產品經理來的時候先看看門把上有沒有這個牌子,如果沒有呢就可以進來找工程師談需求,談之前要把牌子掛起來,談完了再把牌子摘了。
這樣其他產品經理也要來煩他的時候,如果看見這個牌子掛在那里,就可以選擇睡覺等待或者是先去忙別的事。如是這位明星工程師從此獲得了安寧。
這個分布式鎖的使用方式非常簡單,就是使用 Set 指令的擴展參數如下:
- # 加鎖
- set lock:$user_id owner_id nx ex=5
- # 釋放鎖
- if redis.call("get", KEYS[1]) == ARGV[1] then
- return redis.call("del", KEYS[1])
- else
- return 0
- end
- # 等價于
- del_if_equals lock:$user_id owner_id
一定要設置這個過期時間,因為遇到特殊情況,比如地震(進程被 Kill -9,或者機器宕機),產品經理可能會選擇從窗戶上跳下去,沒機會摘牌,導致了死鎖饑餓,讓這位優秀的工程師成了一位大閑人,造成嚴重的資源浪費。
同時還需要注意這個 owner_id,它代表鎖是誰加的,產品經理的工號。以免你的鎖不小心被別人摘掉了。
釋放鎖時要匹配這個 owner_id,匹配成功了才能釋放鎖。這個 owner_id 通常是一個隨機數,存放在 ThreadLocal 變量里(棧變量)。
官方其實并不推薦這種方式,因為它在集群模式下會產生鎖丟失的問題,在主從發生切換的時候。
官方推薦的分布式鎖叫 RedLock,作者認為這個算法較為安全,推薦我們使用。
不過掌閱這邊一直還使用上面最簡單的分布式鎖,為什么我們不去使用 RedLock 呢?因為它的運維成本會高一些,需要 3 臺以上獨立的 Redis 實例,用起來要繁瑣一些。
另外 Redis 集群發生主從切換的概率也并不高,即使發生了主從切換出現鎖丟失的概率也很低,因為主從切換往往都有一個過程,這個過程的時間通常會超過鎖的過期時間,也就不會發生鎖的異常丟失。
還有就是分布式鎖遇到鎖沖突的機會也不多,這正如一個公司里明星程序員也比較有限一樣,總是遇到鎖排隊那說明結構上需要優化。
延時隊列
下面我們繼續看第三個功能,延時隊列。前面我們提到產品經理在遇到「請勿打擾」的牌子時可以選擇多種策略:
- 干等待
- 睡覺
- 放棄不干了
- 歇一會再干
干等待:就是 Spinlock,這會燒 CPU,飆高 Redis 的 QPS。
睡覺:就是先 Sleep 一會再試,這會浪費線程資源,還會增加響應時長。
放棄不干了:就是告知前端用戶待會再試,現在系統壓力大有點忙,影響用戶體驗。
最后一種就是現在要講的策略待會再來:這是在現實世界里最普遍的策略。
這種策略一般用在消息隊列的消費中,這個時候遇到鎖沖突該怎么辦?不能拋棄不處理,也不適合立即重試(Spinlock),這時就可以將消息扔進延時隊列,過一會再處理。

有很多專業的消息中間件支持延時消息功能,比如 RabbitMQ 和 NSQ。Redis 也可以,我們可以使用 Zset 來實現這個延時隊列。
Zset 里面存儲的是 Value/Score 鍵值對,我們將 Value 存儲為序列化的任務消息,Score 存儲為下一次任務消息運行的時間(Deadline),然后輪詢 Zset 中 Score 值大于 Now 的任務消息進行處理。
- # 生產延時消息
- zadd(queue-key, now_ts+5, task_json)
- # 消費延時消息
- while True:
- task_json = zrevrangebyscore(queue-key, now_ts, 0, 0, 1)
- if task_json:
- grabbed_ok = zrem(queue-key, task_json)
- if grabbed_ok:
- process_task(task_json)
- else:
- sleep(1000) // 歇 1s
當消費者是多線程或者多進程的時候,這里會存在競爭浪費問題。當前線程明明將 task_json 從 Zset 中輪詢出來了,但是通過 Zrem 來爭搶時卻搶不到手。
這時就可以使用 LUA 腳本來解決這個問題,將輪詢和爭搶操作原子化,這樣就可以避免競爭浪費。
- local res = nil
- local tasks = redis.pcall("zrevrangebyscore", KEYS[1], ARGV[1], 0, "LIMIT", 0, 1)
- if #tasks > 0 then
- local ok = redis.pcall("zrem", KEYS[1], tasks[1])
- if ok > 0 then
- res = tasks[1]
- end
- end
- return res
為什么我要將分布式鎖和延時隊列一起講呢,因為很早的時候線上出了一次故障。
故障發生時線上的某個 Redis 隊列長度爆表了,導致很多異步任務得不到執行,業務數據出現了問題。
后來查清楚原因了,就是因為分布式鎖沒有用好導致了死鎖,而且遇到加鎖失敗時就 Sleep 無限重試結果就導致了異步任務徹底進入了睡眠狀態不能處理任務。
那這個分布式鎖當時是怎么用的呢?用的就是 Setnx+Expire,結果在服務升級的時候停止進程直接就導致了個別請求執行了 Setnx,但是 Expire 沒有得到執行,于是就帶來了個別用戶的死鎖。
但是后臺呢又有一個異步任務處理,也需要對用戶加鎖,加鎖失敗就會無限 Sleep 重試,那么一旦撞上了前面的死鎖用戶,這個異步線程就徹底熄火了。
因為這次事故我們才有了今天的正確的分布式鎖形式以及延時隊列的發明,還有就是優雅停機,因為如果存在優雅停機的邏輯,那么服務升級就不會導致請求只執行了一半就被打斷了,除非是進程被 Kill -9 或者是宕機。
定時任務
分布式定時任務有多種實現方式,最常見的一種是 Master-Workers 模型。
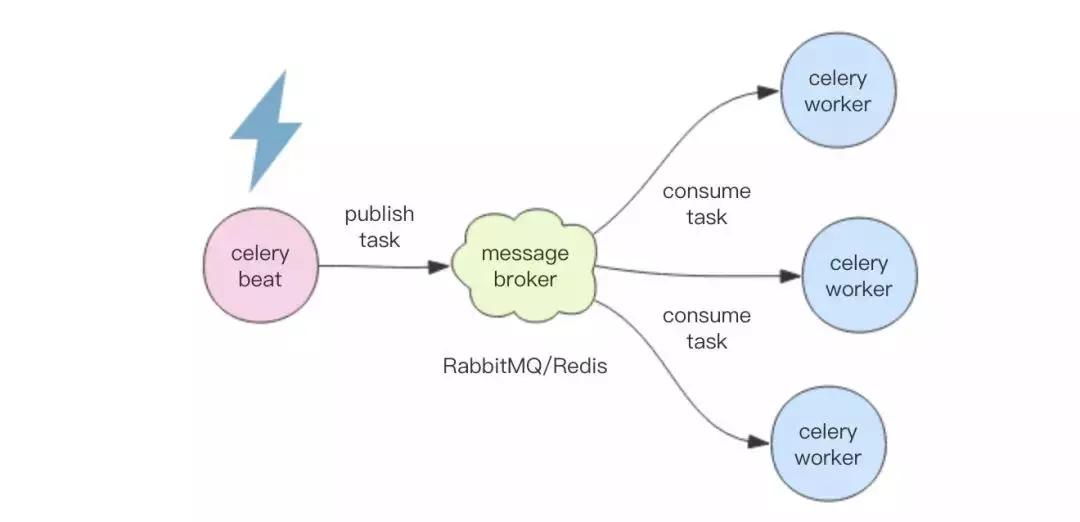
Master 負責管理時間,到點了就將任務消息扔到消息中間件里,然后 Worker 們負責監聽這些消息隊列來消費消息。
著名的 Python 定時任務框架 Celery 就是這么干的。但是 Celery 有一個問題,那就是 Master 是單點的,如果這個 Master 掛了,整個定時任務系統就停止工作了。
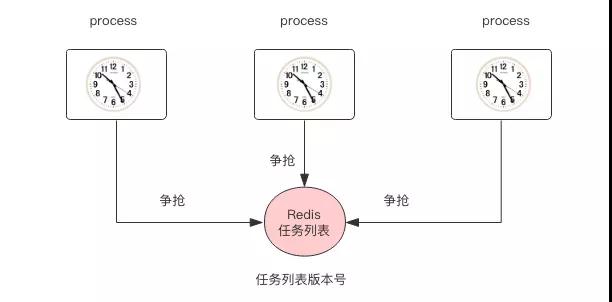
另一種實現方式是 Multi-Master 模型。這個模型什么意思呢,就類似于 Java 里面的 Quartz 框架,采用數據庫鎖來控制任務并發。
會有多個進程,每個進程都會管理時間,時間到了就使用數據庫鎖來爭搶任務執行權,搶到的進程就獲得了任務執行的機會,然后就開始執行任務,這樣就解決了 Master 的單點問題。
這種模型有一個缺點,那就是會造成競爭浪費問題,不過通常大多數業務系統的定時任務并沒有那么多,所以這種競爭浪費并不嚴重。
還有一個問題它依賴于分布式機器時間的一致性,如果多個機器上時間不一致就會造成任務被多次執行,這可以通過增加數據庫鎖的時間來緩解。
現在有了 Redis 分布式鎖,那么我們就可以在 Redis 之上實現一個簡單的定時任務框架:
- # 注冊定時任務
- hset tasks name trigger_rule
- # 獲取定時任務列表
- hgetall tasks
- # 爭搶任務
- set lock:${name} true nx ex=5
- # 任務列表變更(滾動升級)
- # 輪詢版本號,有變化就重加載任務列表,重新調度時間有變化的任務
- set tasks_version $new_version
- get tasks_version
如果你覺得 Quartz 內部的代碼復雜的讓人看不懂,分布式文檔又幾乎沒有,很難折騰,可以試試 Redis,使用它會讓你少掉點頭發。
- Life is Short,I use Redis
- https://github.com/pyloque/taskino
頻率控制
如果你做過社區就知道,不可避免總是會遇到垃圾內容。一覺醒來你會發現首頁突然會被某些莫名其妙的廣告帖刷屏了。如果不采取適當的機制來控制就會導致用戶體驗受到嚴重影響。
控制廣告垃圾貼的策略非常多,高級一點的通過 AI,最簡單的方式是通過關鍵詞掃描。
還有比較常用的一種方式就是頻率控制,限制單個用戶內容生產速度,不同等級的用戶會有不同的頻率控制參數。
頻率控制就可以使用 Redis 來實現,我們將用戶的行為理解為一個時間序列,我們要保證在一定的時間內限制單個用戶的時間序列的長度,超過了這個長度就禁止用戶的行為。
它可以是用 Redis 的 Zset 來實現:
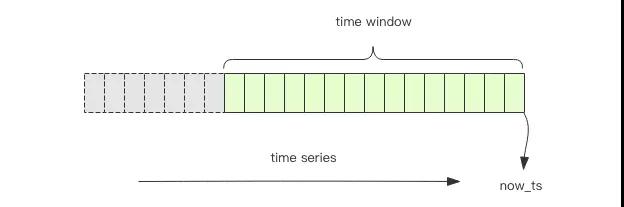
圖中綠色的部分就是我們要保留的一個時間段的時間序列信息,灰色的段會被砍掉。統計綠色段中時間序列記錄的個數就知道是否超過了頻率的閾值。
- # 下面的代碼控制用戶的 ugc 行為為每小時最多 N 次
- hist_key = "ugc:${user_id}"
- with redis.pipeline() as pipe:
- # 記錄當前的行為
- pipe.zadd(hist_key, ts, uuid)
- # 保留1小時內的行為序列
- pipe.zremrangebyscore(hist_key, 0, now_ts - 3600)
- # 獲取這1小時內的行為數量
- pipe.zcard(hist_key)
- # 設置過期時間,節約內存
- pipe.expire(hist_key, 3600)
- # 批量執行
- _, _, count, _ = pipe.exec()
- return count > N
服務發現
技術成熟度稍微高一點的企業都會有服務發現的基礎設施。通常我們都會選用 Zookeeper、Etcd、Consul 等分布式配置數據庫來作為服務列表的存儲。
它們有非常及時的通知機制來通知服務消費者服務列表發生了變更。那我們該如何使用 Redis 來做服務發現呢?
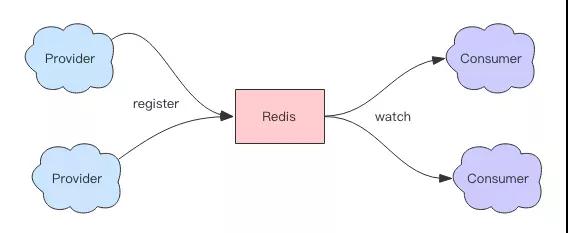
這里我們要再次使用 Zset 數據結構,我們使用 Zset 來保存單個服務列表。多個服務列表就使用多個 Zset 來存儲。
Zset 的 Value 和 Score 分別存儲服務的地址和心跳的時間。服務提供者需要使用心跳來匯報自己的存活,每隔幾秒調用一次 Zadd。
服務提供者停止服務時,使用 Zrem 來移除自己。
- zadd service_key heartbeat_ts addr
- zrem service_key addr
這樣還不夠,因為服務有可能是異常終止,根本沒機會執行鉤子,所以需要使用一個額外的線程來清理服務列表中的過期項:
- zremrangebyscore service_key 0 now_ts - 30 # 30s 都沒來心跳
接下來還有一個重要的問題是如何通知消費者服務列表發生了變更,這里我們同樣使用版本號輪詢機制。
當服務列表變更時,遞增版本號。消費者通過輪詢版本號的變化來重加載服務列表。
- if zadd() > 0 || zrem() > 0 || zremrangebyscore() > 0:
- incr service_version_key
但是還有一個問題,如果消費者依賴了很多的服務列表,那么它就需要輪詢很多的版本號,這樣的 IO 效率會比較低下。
這時我們可以再增加一個全局版本號,當任意的服務列表版本號發生變更時,遞增全局版本號。
這樣在正常情況下消費者只需要輪詢全局版本號就可以了。當全局版本號發生變更時再挨個比對依賴的服務列表的子版本號,然后加載有變更的服務列表:https://github.com/pyloque/captain。

位圖
掌閱的簽到系統做的比較早,當時用戶量還沒有上來,設計上比較簡單,就是將用戶的簽到狀態用 Redis 的 Hash 結構來存儲,簽到一次就在 Hash 結構里記錄一條。
簽到有三種狀態,未簽到、已簽到和補簽,分別是 0、1、2 三個整數值:
- hset sign:${user_id} 2019-01-01 1
- hset sign:${user_id} 2019-01-02 1
- hset sign:${user_id} 2019-01-03 2
- ...
這非常浪費用戶空間,到后來簽到日活過千萬的時候,Redis 存儲問題開始凸顯,直接將內存飚到了 30G+,我們線上實例通常過了 20G 就開始報警,30G 已經屬于嚴重超標了。
這時候我們就開始著手解決這個問題,去優化存儲。我們選擇了使用位圖來記錄簽到信息,一個簽到狀態需要兩個位來記錄,一個月的存儲空間只需要 8 個字節。
這樣就可以使用一個很短的字符串來存儲用戶一個月的簽到記錄。優化后的效果非常明顯,內存直接降到了 10 個 G。
因為查詢整個月的簽到狀態 API 調用的很頻繁,所以接口的通信量也跟著小了很多。

但是位圖也有一個缺點,它的底層是字符串,字符串是連續存儲空間,位圖會自動擴展,比如一個很大的位圖 8M 個位,只有最后一個位是 1,其他位都是零,這也會占用 1M 的存儲空間,這樣的浪費非常嚴重。
所以呢就有了咆哮位圖這個數據結構,它對大位圖進行了分段存儲,全位零的段可以不用存。
另外還對每個段設計了稀疏存儲結構,如果這個段上置 1 的位不多,可以只存儲它們的偏移量整數。這樣位圖的存儲空間就得到了非常顯著的壓縮。
這個咆哮位圖在大數據精準計數領域非常有價值,感興趣的同學可以了解一下:https://juejin.im/post/5cf5c817e51d454fbf5409b0
模糊計數
前面提到這個簽到系統,如果產品經理需要知道這個簽到的日活月活怎么辦呢?通常我們會直接甩鍋,請找數據部門。
但是數據部門的數據往往不是很實時,經常前一天的數據需要第二天才能跑出來,離線計算通常是定時的一天一次。那如何實現一個實時的活躍計數?
最簡單的方案就是在 Redis 里面維護一個 Set 集合,來一個用戶,就 Sadd 一下,最終集合的大小就是我們需要的 UV 數字。
但是這個空間浪費很嚴重,僅僅為了一個數字要存儲這樣一個龐大的集合似乎非常不值當。那該怎么辦?
這時你就可以使用 Redis 提供的 HyperLogLog 模糊計數功能,它是一種概率計數,有一定的誤差,誤差大約是 0.81%。
但是空間占用很小,其底層是一個位圖,它最多只會占用 12K 的存儲空間。而且在計數值比較小的時候,位圖使用稀疏存儲,空間占用就更小了。
- # 記錄用戶
- pfadd sign_uv_${day} user_id
- # 獲取記錄數量
- pfcount sign_uv_${day}
微信公眾號文章的閱讀數可以使用它,網頁的 UV 統計它都可以完成。但是如果產品經理非常在乎數字的準確性,比如某個統計需求和金錢直接掛鉤,那么你可以考慮一下前面提到的咆哮位圖。
它使用起來會復雜一些,需要提前將用戶 ID 進行整數序列化。Redis 沒有原生提供咆哮位圖的功能,但是有一個開源的 Redis Module 可以拿來即用:https://github.com/aviggiano/redis-roaring。
布隆過濾器
最后我們要講一下布隆過濾器,如果一個系統即將會有大量的新用戶涌入時,它就會非常有價值,可以顯著降低緩存的穿透率,降低數據庫的壓力。
這個新用戶的涌入不一定是業務系統的大規模鋪開,也可能是因為來自外部的緩存穿透攻擊。
- def get_user_state0(user_id):
- state = cache.get(user_id)
- if not state:
- state = db.get(user_id) or {}
- cache.set(user_id, state)
- return state
- def save_user_state0(user_id, state):
- cache.set(user_id, state)
- db.set_async(user_id, state)
比如上面就是這個業務系統的用戶狀態查詢接口代碼,現在一個新用戶過來了,它會先去緩存里查詢有沒有這個用戶的狀態數據,因為是新用戶,所以肯定緩存里沒有。
然后它就要去查數據庫,結果數據庫也沒有。如果這樣的新用戶大批量瞬間涌入,那么可以預見數據庫的壓力會比較大,會存在大量的空查詢。
我們非常希望 Redis 里面有這樣的一個 Set,它存放了所有用戶的 ID,這樣通過查詢這個 Set 集合就知道是不是新用戶來了。
當用戶量非常龐大的時候,維護這樣的一個集合需要的存儲空間是很大的。
這時候就可以使用布隆過濾器,它相當于一個 Set,但是呢又不同于 Set,它需要的存儲空間要小的多。
比如你存儲一個用戶 ID 需要 64 個字節,而布隆過濾器存儲一個用戶 ID 只需要 1 個字節多點。
但是呢它存的不是用戶 ID,而是用戶 ID 的指紋,所以會存在一定的小概率誤判,它是一個具備模糊過濾能力的容器。
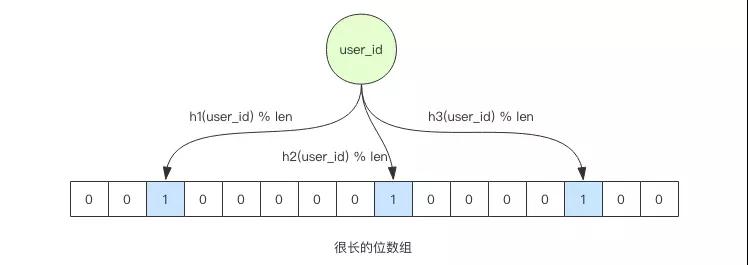
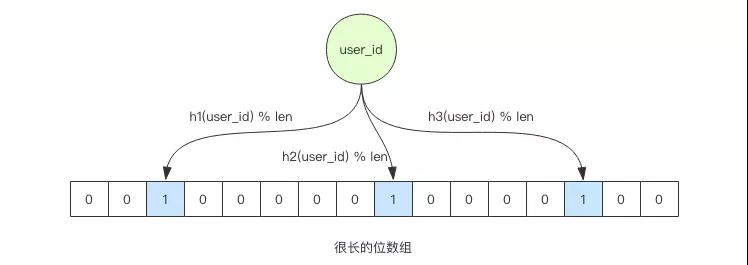
當它說用戶 ID 不在容器中時,那么就肯定不在。當它說用戶 ID 在容器里時,99% 的概率下它是正確的,還有 1% 的概率它產生了誤判。
不過在這個案例中,這個誤判并不會產生問題,誤判的代價只是緩存穿透而已。
相當于有 1% 的新用戶沒有得到布隆過濾器的保護直接穿透到數據庫查詢,而剩下的 99% 的新用戶都可以被布隆過濾器有效的擋住,避免了緩存穿透。
- def get_user_state(user_id):
- exists = bloomfilter.is_user_exists(user_id)
- if not exists:
- return {}
- return get_user_state0(user_id)
- def save_user_state(user_id, state):
- bloomfilter.set_user_exists(user_id)
- save_user_state0(user_id, state)
布隆過濾器的原理有一個很好的比喻,那就是在冬天一片白雪覆蓋的地面上,如果你從上面走過,就會留下你的腳印。
如果地面上有你的腳印,那么就可以大概率斷定你來過這個地方,但是也不一定,也許別人的鞋正好和你穿的一模一樣。
可是如果地面上沒有你的腳印,那么就可以 100% 斷定你沒來過這個地方。
作者:錢文品(老錢)
簡介:互聯網分布式高并發技術十年老兵,目前任掌閱服務端技術專家。熟練使用 Java、Python、Golang 等多種計算機語言,開發過游戲,制作過網站,寫過消息推送系統和 MySQL 中間件,實現過開源的 ORM 框架、Web 框架、RPC 框架等。























