容器云平臺API Server卡頓問題排查
58云計算平臺是58集團架構線基于Kubernetes + Docker技術為集團內部服務開發的一套業務實例管理平臺,它具有簡單,輕量的特點及高效利用物理資源,更快的部署和統一規范的標準化運行環境,通過云平臺,使得服務標準化,上線流程規范化,資源利用合理化。然而云平臺的建設過程不是一帆風順,也不乏出現一些問題挑戰,本文就針對云平臺現實中遇到的一個問題和大家分享。
1、關于問題
1.1 問題概述
近期,很多業務同事反饋使用云平臺上線存在容器部署慢,平臺反應慢的問題。通過詳細的問題排查定位后,最終問題得以解決。
1.2 Kubernetes基本知識
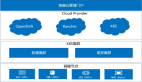
私有云平臺通過Kubernetes對容器進行編排。Kubernetes整體架構如下圖所示:

其中幾個主要的模塊的功能簡要描述如下:
- etcd:用于Kubernetes的后端存儲。
- Pod:Kubernetes最基本的操作單元,包含一個或多個緊密相關的容器。
- Replication Controller:副本控制器,用來保證Deployment或者RC中副本的數量。
- Scheduler:Kubernetes的調度器,Scheduler監聽API Server,當需要創建新的Pod時Scheduler負責選擇該Pod與哪個Node進行綁定。
- Kubelet:每個Node節點上都會有一個Kubelet負責Master下發到該節點的具體任務,管理該節點上的Pod和容器。
- API Server:對于整個Kubernetes集群而言,API Server是通過暴露Kubernetes API的方式提供給內部組件或者外部程序調用去完成對Kubernetes的操作。各個組件之間也是通過API Server作為橋梁進行間接通信,這種方式做到各個組件間充分解耦。
業務同事操作管理平臺發出創建集群請求到集群創建完成的整個流程如下:
- 業務同學操作管理平臺進行升級操作,管理平臺通過http方式向API Server發出請求。
- API Server處理和解析請求參數,將待創建的Pod信息通過API Server存儲到etcd。
- Scheduler通過API Server的watch機制,查看到新的Pod,嘗試為Pod綁定Node。
- 經過預選篩除不合適節點及從待選節點中根據一定規則選出最適合的節點。
- 對選中的節點及Pod進行binding操作,將相關的結果通過API Server存儲到etcd。
- 對應Node的Kubelet進程調用容器運行時創建容器。
2. 定位問題
2.1 問題排查
從1.2可以看到,API Server在創建Pod過程中起到非常關鍵的中間橋梁作用,解析外部請求及讀寫etcd。因此決定首先從API Server進程所在宿主機的各項性能指標及日志方面進行排查,看是否有所發現。
目前線上環境有3臺主機運行API Server,以達到流量負載均衡的目的,異常時間段網卡eth2入流量如下圖所示:

由3臺API Server主機的監控數據,發現服務器A的網卡入流量遠高于另外兩臺,說明絕大部分請求發送到了服務器A。
通過對比三臺服務器API Server 的CPU利用率,發現服務器A的API Server進程CPU使用率一直保持在2000%(20核)上下波動,而另外兩臺服務器的API Server的CPU利用率沒有超過100%(1核)。進一步證實了A的API Server進程處理了絕大多數的請求。
查看A服務器的API Server的相關log,發現正在大量輸出如下的日志:

這個日志顯示有大量請求通過API Server到etcd查詢Pod的狀態。
對于Kubernetes后端的存儲目前采用5個etcd節點組成etcd集群。登陸其中一個節點(E1),發現對E1節點執行etcd操作命令,比如命令:“etcdctl ls /registry/pods/default”,命令執行也會經常超時。如果你想和更多Kubernetes技術專家交流,可以加我微信liyingjiese,備注『加群』。群里每周都有全球各大公司的***實踐以及行業***動態。
同時對比5臺etcd節點的流量,發現有一個節點網卡入流量遠高于其他四個節點,該節點(E1)的etcd進程的CPU利用率在100%左右,明顯高于剩余的4個節點CPU利用率。查看節點E1的etcd進程日志,經常看到如下報錯:

可以推斷節點E1的負載非常高,節點間同步心跳都已經超時,無法正常的響應外部的請求了。
2.2 問題分析
經過上述排查,主要集中在這兩個問題上:
2.2.1負載均衡策略失效
首先可以看到對Kubernetes集群的操作請求大部分都落在某個API Server上,導致其中一個API Server負載很高,那么有可能負載均衡策略有些問題。那就先看看當前負載均衡策略是如何的。
當前我們租賃的是騰訊的機房,負載均衡策略采用的是TGW(Tencent Gateway)系統所自帶支持的負載均衡策略。騰訊云上有關介紹如下:
TGW負載均衡策略保證請求的分攤轉發,也會自動對resource server(RS)進行存活檢測,每分鐘會有心跳包去對接入TGW的IP Port進行探測。
關于TGW相關配置具體如下:
- 做域名解析:我們對需要訪問到API Server的物理機都做了本地DNS,將一個固定域名(D)解析到一個特定的VIP(V),而該VIP就是TGW對外提供的虛擬IP。
- 配置TGW服務的RS列表:將三臺API Server節點對應的物理IP加入到RS列表。
正常情況下,所有需要訪問API Server的請求都先本地域名解析到虛擬IP V,將請求的數據包都發送到V,V相當于是TGW對外的接入點,再通過TGW內部負載均衡策略將請求數據包進行目的網絡地址轉換(DNAT),分發到不同的RS上。
經排查,TGW的監控檢測模塊定期向所有的RS發送心跳包,但是TGW監控檢測模塊只能收到A服務器的回包,因此TGW認為只有A節點是存活狀態,所有的請求數據包最終就由TGW轉發到A服務器上了,這就是負載均衡策略失效的根本原因。
這里還有一個現象是為什么etcd集群中只有一個節點的負載很高呢?
五個節點的etcd集群中只有一個節點負載很高,其他正常,通過查看A服務器的API Server的log,可以看到的大量的讀請求都固定發送到了同一個etcd節點。
對于這個現象,可以看下API Server訪問后端存儲的源碼,目前線上Kubernetes基于v1.7.12的源碼編譯運行,API Server訪問etcd是在內部初始化一個etcd client端,然后通過etcd client端發送請求到etcd server端。etcd client端有v2和v3兩個版本。線上API Server使用的是v2版本客戶端。主要代碼如下:
- //初始化etcd工作
- func New(cfg Config) (Client, error) {
- c := &httpClusterClient{//返回一個http類型的client
- clientFactory: newHTTPClientFactory(cfg.transport(), cfg.checkRedirect(), cfg.HeaderTimeoutPerRequest),
- rand: rand.New(rand.NewSource(int64(time.Now().Nanosecond()))),//傳入一個當前時間的隨機種子
- selectionMode: cfg.SelectionMode,
- }
- if err := c.SetEndpoints(cfg.Endpoints); err != nil {
- return nil, err
- }
- return c, nil
- }
- //對etcd列表進行打亂
- func (c *httpClusterClient) SetEndpoints(eps []string) error {
- ...
- neps, err := c.parseEndpoints(eps)
- c.Lock()
- defer c.Unlock()
- c.endpoints = shuffleEndpoints(c.rand, neps)//打亂etcd列表
- c.pinned = 0
- ...
- return nil
- }
- func shuffleEndpoints(r *rand.Rand, eps []url.URL) []url.URL {
- p := r.Perm(len(eps))//rank庫的Perm方法可以返回[0,n)之間的隨機亂序數組
- neps := make([]url.URL, len(eps))
- for i, k := range p {
- neps[i] = eps[k]
- }
- return neps
- }
可以看到在初始化etcd客戶端時候會傳入一個當前時間的隨機種子去打亂所有Endpoints(etcd節點)的順序。
對于etcd的操作都是通過API Server內部的etcd客戶端發送http請求到etcd Server端,最主要是調用如下方法:
- func (c *httpClusterClient) Do(ctx context.Context, act httpAction) (*http.Response, []byte, error) {
- ...
- for i := pinned; i < leps+pinned; i++ {
- k := i % leps
- hc := c.clientFactory(eps[k])
- resp, body, err = hc.Do(ctx, action)
- ...
- if resp.StatusCode/100 == 5 {
- switch resp.StatusCode {
- case http.StatusInternalServerError, http.StatusServiceUnavailable:
- cerr.Errors = ...
- default:
- cerr.Errors = ...
- }
- ...
- continue
- }
- if k != pinned {
- c.Lock()
- c.pinned = k
- c.Unlock()
- }
- return resp, body, nil
- }
- return nil, nil, cerr
- }
該方法表明每次請求時候,會從pinned節點開始嘗試發送請求,如果發送請求異常,則按照初始化時候打亂順序的下一個節點(pinned++)開始嘗試發送數據。如此看來,如果API Server使用了某個endpoint發送數據,除非用壞了這個節點,否則會一直使用該節點(pinned)發送數據。這就說明了,沒有異常情況下,一個API Server就對應往一個固定的etcd發送請求。
對于etcd集群,如果是寫請求的話,follower節點會把請求先轉發給leader節點處理,然后leader再轉發給follower同步。那么5個節點CPU負載不會這么不均衡,但是根據2.1排查API Server日志看到這里是大量的讀請求,相對于寫請求,讀請求是所有follower節點都能對外提供的。也就是大量請求由于負載均衡策略失效都轉發到A服務器,A再把查詢請求都打到其中一個固定的etcd,導致該節點忙于處理etcd查詢請求,負載就會飆高。
總的來說,TGW做負載均衡時候,由于心跳檢測模塊和其中兩個Resource Server間連接不通,導致誤將所有請求都轉發到其中一個API Server,而一個特定的API Server使用v2版本etcd客戶端就只會往一個固定的etcd服務端發請求,這樣整個負載均衡策略就失效了。
2.2.2 etcd存取數據緩慢
namespace未做劃分:
從2.1中查看API Server 的日志可以看出,很多get請求Pod對象信息,比如:“Get /api/v1/namespaces/default/pods?...” 這些都是從default namespace下獲取Pod信息,這就說明線上并沒有對Pod的namespace做劃分。
Kubernetes是通過namespace對容器資源進行隔離,默認情況下,如果未指定namespace的話,創建的容器都被劃分到default namespace下,因為這個原因也給后面往etcd中存儲容器元數據信息也留下了坑。所有的Kuberentes的元數據都存儲在etcd的/registry目錄下,整體如下圖所示:

Kubernetes中Pod的信息存儲在/registry/pods/#{命名空間}/#{具體實例名}的目錄結構中,正因為如果不指定namespace的話,就會存儲到default的namespace中,也就是/registry/pods/default目錄下保存了線上全部Pod對象信息。
也就是說大量get請求Pod對象信息,由于未做namespace劃分,每次都會去訪問default子目錄,每次請求相當于都要做全局搜索,隨著集群的增多,Pod不斷的存入到該子目錄中,搜索性能也會變得越來越差。
查詢結果未加入緩存:
從2.1中查看API Server 的日志看到很多Get/List操作,那么可以仔細看看相關方法的執行流程,下面是List方法執行過程中調用的中間函數:
- f
- unc (c *Cacher) GetToList(ctx context.Context, key string, resourceVersion string, pred SelectionPredicate, listObj runtime.Object) error {
- if resourceVersion == "" {
- return c.storage.GetToList(ctx, key, resourceVersion, pred, listObj)//直接查詢etcd
- }
- listRV, err := ParseListResourceVersion(resourceVersion)
- ...
- obj, exists, readResourceVersion, err := c.watchCache.WaitUntilFreshAndGet(listRV, key, trace)//從緩存中獲取
- ...
- return nil
- }
可以看到,GetToList方法中傳入的有個resourceVersion 參數,如果設置了就會從緩存中獲取,如果不設置就會去etcd中查詢。這個也是一個關鍵點,有關resourceVersion 的相關使用如下:
- 不設置:通過API Server從etcd讀取。
- 設置成0:從API Server的cache讀取,減輕API Server和etcd壓力。例如Kubelet經常通過此方法Get Node對象,Kubernetes Infomer***次啟動時List也通過此方法獲得對象。
- 大于0:讀取對象指定版本。
線上管理平臺通過http接口去查詢Pod信息時候是沒有設置resourceVersion,所以每次通過Get/List方法獲取資源時候都會查詢etcd,如此一來經常大量高頻率的查詢etcd會導致其壓力較大,開啟緩存策略不僅可以減輕訪問etcd壓力而且還可以加快查詢速度。
總結以上兩點:所有的請求都發往一個固定的API Server,導致該API Server節點負載較高,同時該API Server又會將查詢請求固定的發給某個etcd節點,然而請求結果并沒有在API Server端做緩存,每次都會直接查詢etcd,在從etcd中獲取Pod信息又是從default這個大的子目錄中全局搜索,每次請求都比較費時,這樣導致某一個固定的etcd一直處理大量的費時的請求,最終將該etcd資源耗盡,負載過高,因而查詢結果不能及時返回給API Server,導致創建Pod時候拿不到相關的信息,Pod創建工作無法進行,所以最終表象是集群部署長時間卡頓。
3、解決方案
切換負載均衡方案:臨時切換為DNS輪詢方式,保證每個API Server節點的流量均衡。同時跟進TGW對于某些網段的RS和TGW服務不能探測心跳及后續改進。
將Kubernetes中Pod按多個namespace劃分,目前線上所有的Pod都劃分到默認的default的namespace下,每次讀取Pod信息都是從etcd檢索整個namespace,比較損耗etcd性能,目前已經將Pod的namespace進行細分,加快了讀取Pod信息速度同時減少了etcd性能損耗。
etcd v3版本客戶端會對Endpoints定期打亂,后續我們會升級到v3版本,這樣同一個API Server的請求就不會一直落到某一個etcd上,這樣即使負載均衡策略失效也能做到對etcd請求的分攤。
查詢Kubernetes資源信息時帶入resourceVersion開啟緩存機制,減輕對etcd的訪問壓力。
4、總結
從API Server卡頓問題排查過程來看,潛在的問題是長期存在的,只是積累到一定量后,問題的影響才會凸顯。這就要求我們平時對Kubernetes相關組件的性能指標,日志等要保持時刻敏感,要對Kubernetes各種默認策略及參數非常熟悉,同時對于重要功能模塊做到源碼層面了解,這樣才能規避潛在風險和出問題后能快速定位,保證生產環境穩定健康的運行。