容器云平臺物理集群配置實踐
?前言
最初建設容器云平臺的時候,筆者也討論過容器虛擬集群和物理集群的優缺點。在容器云平臺應用實踐過程中,也逐漸部署了虛擬節點和物理節點。隨著實踐的深入,虛擬節點和物理節點的不同資源配置,也帶來了一些問題和思考。起初覺得容器既然是輕量化的,每個節點其實是不需要配置那么高的資源的。不過很快就被現實打臉,不合適的節點資源配置不但增加了管理的復雜度,也帶來了資源的浪費。另外由于容器云平臺自身功能的限制,以及總體架構和總體資源受限,難以實現真正的彈性調度、按需擴展。
比如說經常會出現一臺宿主機上的虛擬機資源爭搶現象,但從容器云平臺看到的卻是容器節點資源使用不高但應用出現請求異常等問題。所以這并不是一個簡單的容器云問題,需要實現各個層次的聯動,比如實現虛擬化平臺與容器云平臺的聯動,基礎設施資源管理平臺與容器云平臺的聯動以實現異構資源調度等。
從虛擬機節點到物理機節點
基于虛擬化平臺來部署容器云則相對容易實現容器節點的擴縮容,但由于缺乏統一的監控平臺和囿于單體豎井系統建設思路,虛擬化層宿主機的信息往往在容器云平臺無法看到,無法及時有效平衡容器節點在虛擬化宿主機上的負載。
筆者一直建議通過多云管理平臺(也管理虛擬化平臺)來實現不同基礎設施資源的管理,但目前市面上的云管平臺基本都是一個大雜燴,沒有真正理解云管的定位和范圍。等等諸多原因,使難以實現基礎設施資源的自動化彈性擴容和平衡調度。
另外,虛擬化層也導致了機器性能損失約20%,造成很大的浪費。比如Java應用對資源的需求相對比較大,基于SpringCloud框架開發的微服務,如果部署在資源配置比較小的虛擬機上,容器經常會因為資源不足而被驅逐,會看到很多Evicted狀態的容器。
再者,隨著容器節點的增多,很多問題就暴露出來了,比如說Master節點配置(隨著節點增多,Master節點資源不足響應變慢)、ETCD配置(pod、service等對象越來越多)、Ingress配置(高可用、負載均衡等不同需求所帶來配置的不同)、Portal配置(Portal組件劃分、組件集中部署或分布式部署、組件資源配額)問題等。
一方面可能國內很多容器平臺的應用都是浮于表面,缺乏真正的實踐經驗,沒有太多可以借鑒的,也導致很多功能不完善;另一方面,傳統單體豎井的建設思路,已經完全不適應云計算和云原生的理念,從而也導致沖突,制約容器云的深度應用和實踐。
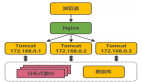
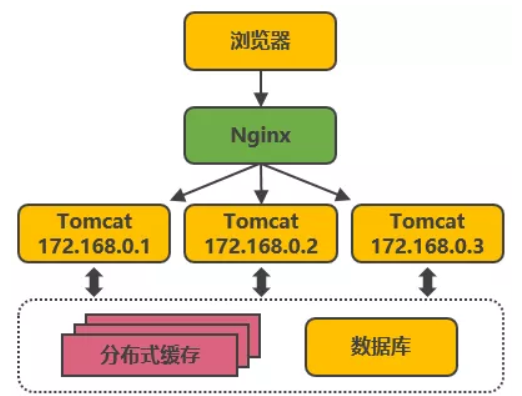
為了更好的實現可見性和可管理性,為了更好的性能和資源節省,經過一段實踐之后,我們將一些物理服務器部署到了容器虛擬集群,用于部署運行重要的業務應用,形成虛實節點混合部署集群。
混合節點集群
私有云環境往往無法充分配置各種類型的資源,所以大都是通用性資源,用于部署各種業務應用。容器云平臺既要考慮節點的敏捷擴容,也要考慮重點業務應用的穩定運行和執行效率。物理服務器的采購往往需要一個周期,需要提前準備相應的資源。物理節點擴容相對于虛擬化來說就沒那么方便,也難以實現資源的復用,這是物理節點不足的地方。但物理節點沒有性能損失,適合運行一些比較重要的業務,或對處理性能要求比較高的業務。因此可以在容器集群中同時部署虛擬節點和物理節點,實現混合節點的集群。在業務應用部署的時候,根據業務應用特點調度到合適的節點上。
節點配置多大的資源是合適的?坦率說到目前為止也沒有一個明確的標準,往往和具體的業務密切相關。筆者所在場景中虛擬機可以配置16C 64G、16C48G或者32C64G,磁盤200G,CPU和內存的比為1:4、1:3、1:2。根據業務運行對資源的消耗需求,經過一段時間的運行觀察,可以根據實際資源使用再調整節點資源配置、容器資源配置。在交易高峰時段,CPU經常是滿負荷的,但其他時段CPU往往用的又比較低。共享分區、獨享分區、節點容量、資源碎片、縱向擴容能力、橫向擴容能力、遷移規則、服務優先級、甚至異構資源的費用等等,都可能會影響到pod的調度。這其實帶來了一個物理節點資源配置的問題。物理機不做虛擬化,就無法從虛擬層來實現復用(不過也減少了虛擬化損耗),另外,物理節點如果出現異常,需要維護重啟,其上面的服務都會受到影響。如果部署的服務比較多,帶來的影響就比較大。所以一個容器節點的資源配置也不是越大越好,需要基于實踐和實際找到一個平衡。
容器物理集群配置
物理集群中節點什么樣的配置比較合適?可能需要從幾個方面來考慮。最初筆者也想當然覺得可以用很多低配PC機,不過從機房的使用效率來說,低配PC明顯不是很合適,畢竟需要占據很多機房機位的,這個成本其實很高的。但如果配置過高,一個容器節點通常也不適合部署很多個容器,k8s建議不超過110個pod。另外,配置過高,節點數量相對就比較少,彈性調度的范圍就比較小。特別多個重要的容器部署到同一個節點上,一旦節點出現異常,影響可能會非常大。不過物理節點相對有效的減少了資源碎片和資源虛擬化損失,資源利用率相對更高。
基于前期的實踐和實際的情況,采購了一批96C 512G 4T的服務器,用于搭建容器物理集群,部署一些重要的業務應用。采用物理節點,對應用資源的調度能力要求反而更高了。資源調度可以有不同的規則,比如說是平衡調度?還是單節點優先調度?或是預留部分資源平衡調度等等;還有大的pod和小的pod的均衡調度、服務親和性和非親和性調度等需求。在節點量相對少的情況下,可能需要重點考慮應用pod的均衡調度問題。
深入認識容器使用場景
我們都知道容器輕量、無狀態、生命周期短。不過實際應用可能會發現,一個業務應用容器可能并不輕量、有眾多的數據需要持久化、往往需要長期持續穩定運行等等。可能也會經常遇到幾個G、十幾個G的鏡像,把容器直接當虛擬機用。雖然說這是一些不好的習慣,不過問題確實是存在的。理論上,容器要盡可能刪除無用的組件和文件,使容器盡可能輕量,但實際項目中,很多廠商都不會去做這些工作,因為這需要很多的時間來清理,需要遵循很多的規則,需要額外很多測試;另外在業務異常處理過程中可能會用到一些工具或組件,安裝這些工具和組件到容器就會導致這些容器比較重,同時也增加了安全的接觸面,帶來了更多的安全漏洞或潛在安全漏洞和安全風險。比如說,打包Java服務時用JDK鏡像還是用JRE鏡像?運行java,JRE就夠了,用JDK其實就額外浪費了很多資源。
筆者就一直強調像數據庫、Kafka、Redis、ES等不適合部署在容器中,當然,測試環境中為了敏捷構建業務測試環境,快速回歸初始狀態以便于執行回歸測試等,是很便利的。不過生產環境追求的是穩定、可靠(這就是Google SRE的價值所在),和測試環境的敏捷需求是不一樣的。不同的場景所采取的方案可能是不同的,因此在實現容器內小環境一致性的之外,企業內生產和測試環境可能還是會有差別的。在生產環境,穩定性和可靠性比彈性更重要,因此,生產環境除了數據庫、中間件等適合部署在物理機上外,一些重要的業務也可用容器物理節點更好的滿足性能等需求。
筆者曾經嘗試配置不同的容器節點以滿足不同業務應用的需求,但資源分配出去之后無法控制各團隊的使用,特別有眾多的廠商和外包人員,對容器和相關的技術理解不深,不知道怎么設置資源配置、調度配置等參數,對業務服務的資源需求不知道怎么預估,因此往往會不自覺地配置很大的資源以此來避免資源所帶來的問題,但這樣造成了很大的資源浪費(分出去的資源被獨占,無法與其他服務共享)。因此也需要及時的監控提醒和培訓,調整不合理的資源配置。
容器在遷移、重啟、被驅逐等都會導致Pod重建,造成短時間的中斷;業務服務如果無法啟動比如初始化連接不上kafka或數據庫可能會導致Pod頻繁重建,k8s自身的一些bug也會導致系統某些資源耗盡,帶來節點異常。實際運行種也曾發現有容器服務創建了數百個到數千個進程。由于容器POD的封裝,不去檢查這些指標的話可能無法發現問題,導致環境經常出現異常,特別生產環境,業務不穩定不止體驗不好,更會帶來資金損失,所以容器的短生命周期自恢復特性,如果不注意其內封裝的業務應用和運行環境,依然會帶來很多問題。
一點建議
大家往往都喜歡最佳實踐,其實不同環境不同場景不同需求等所應采取的方案可能也不同的,所以筆者也一直建議基于實際來考慮。經驗可以作為參考,但不能照搬。容器云平臺在使用虛擬節點和物理節點時各有優缺點,不過隨著管理手段的增強,以及政策的支持,物理集群可能會越來越多。物理集群的配置也需要基于具體的業務需求來確定。
如果每個服務對資源的需求都不大,可以配置稍微低點的物理節點;如果部署的容器對資源需求比較大,比如部署Kafka、ES等中間件容器,可能一個Pod就需要32C64G甚至更多的資源,可能需要配置高些。隨著應用資源調度能力逐步完善,實現不同業務分時共享復用來有效提升資源利用率,可能會越來越普遍。已經有公司通過應用混合部署來提升資源效率,比如說白天處理交易業務為主,晚上處理批量計算為主,使業務忙時和閑時的資源都能充分利用。這對于容器物理節點來說可能會更合適些。