













分享用小型數據集處理數據的7個小技巧
我們經常聽說,大數據是那些成功的機器學習項目的關鍵。
這是一個主要問題:許多組織沒有你需要的數據。
如果沒有最基本的原材料,我們如何原型化和驗證機器學習思想?在資源稀缺的情況下,如何有效地利用數據獲取和創造價值?
在我的工作場所,我們為客戶制作了很多功能原型。正因為如此,我經常需要讓小數據走得更遠。在本文中,我將分享7個技巧來改進使用小型數據集進行原型設計時的結果。
1. 要意識到你的模型不能很好地推廣
這應該是目前最重要的。你正在建立一個模型,它的知識是浩瀚的知識海洋中的一小部分,而這種情況應該是必然的。
如果你正在構建一個基于室內照片的計算機視覺原型,不要期望它在戶外工作得很好。如果你有一個基于聊天室玩笑的語言模型,不要期望它適用于夢幻的小說。
確保你的經理或客戶能理解這一點。這樣,每個人都可以對模型應該交付的結果有一個現實的期望。它還為提出有用的新的KPI提供了機會,以便在原型范圍內外對模型性能進行量化。
2.建立良好的數據基礎設施
在許多情況下,客戶端沒有你需要的數據,公共數據也不是一個選項。如果原型的一部分需要收集和標記新數據,請確保你的基礎設施盡可能少地產生摩擦。
你需要確保數據標記非常簡單,以便非技術人員也可以使用。我們已經開始使用Prodigy,我認為這是一個很好的工具:既可訪問又可擴展。根據項目的大小,你可能還想設置一個自動數據攝取器,它可以接收新數據并自動將其提供給標記系統。
如果將新數據快速而簡單地導入系統,你將獲得更多的數據。
3.做一些數據擴充
通常可以通過增加現有的數據來擴展數據集。它是對數據進行微小的更改,而不應該顯著地更改模型輸出。例如,如果一只貓旋轉了40度,它的圖像仍然是一只貓的圖像。
在大多數情況下,增強技術允許你生成更多的"semi-unique"數據點來訓練模型。首先,可以嘗試在數據中添加少量高斯噪聲。
對于計算機視覺,有許多簡單的方法來增強圖像。我對Albumentations庫有很多的經驗,它做了許多有用的圖像轉換,同時保持你的標簽完好無損。

許多人發現另一種有用的增強技術是Mixup。這種技術實際上是獲取兩個輸入圖像,將它們混合在一起并組合它們的標簽。
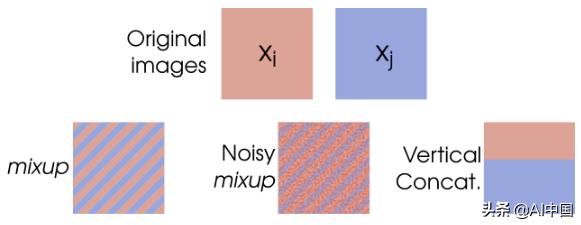
在擴展其他輸入數據類型時,需要考慮哪些轉換會更改標簽,哪些不會。
4.生成一些合成數據
如果你已經用盡了擴展真實數據的選項,你可以開始考慮創建一些假數據。生成合成數據也是覆蓋真實數據集沒有的一些邊緣情況的好方法。
例如,許多機器人強化學習系統(如OpenAI的Dactyl)在部署到真實機器人之前,都是在模擬的3D環境中進行訓練的。對于圖像識別系統,你同樣可以構建3D場景,為你提供數千個新的數據點。

有許多方法可以創建合成數據。在Kanda,我們正在開發一個基于 turntable-based 的解決方案,來創建用于對象檢測的數據。如果你有很高的數據需求,你可以考慮使用Generative Adverserial Networks 來創建合成數據。要知道GAN是出了名的難訓練,所以首先要確保它是可以創建的。
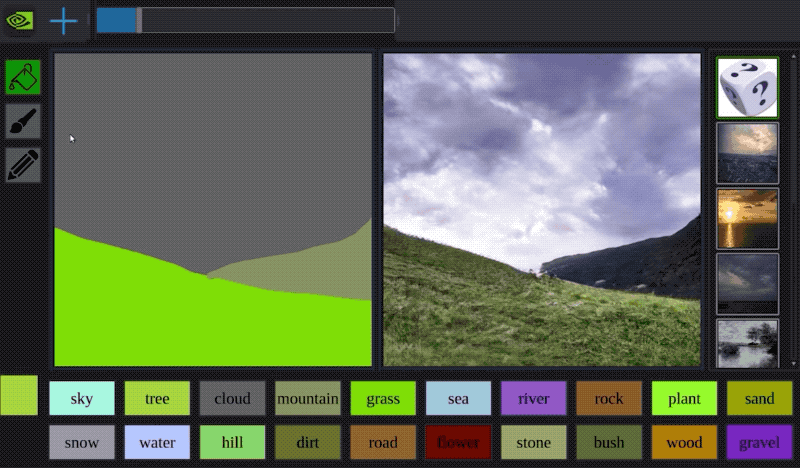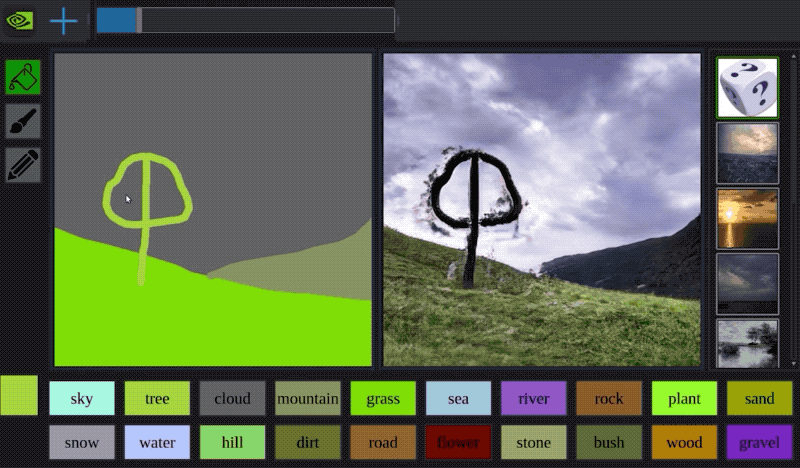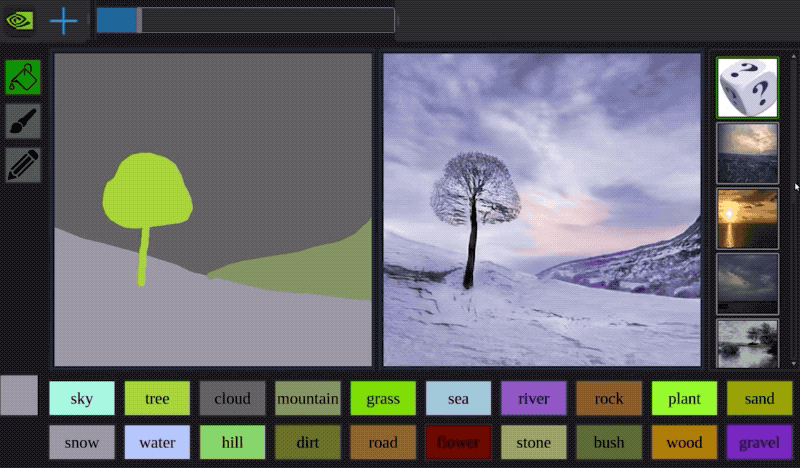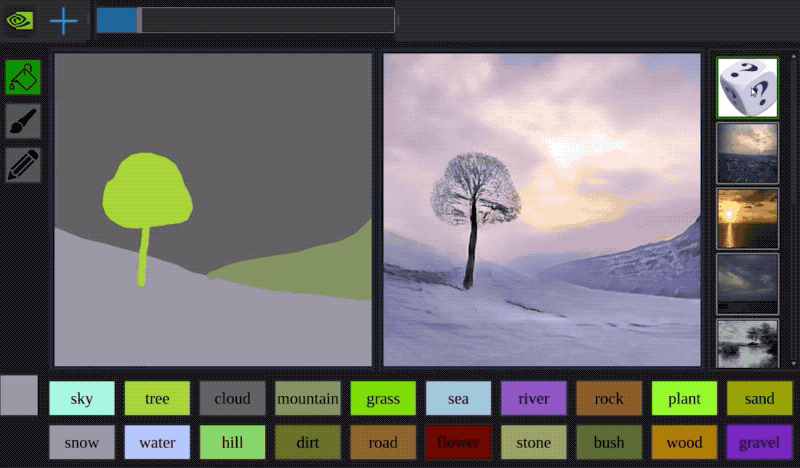
有時你可以將這些方法結合起來:蘋果有一個非常聰明的方法,使用GAN來處理3D建模人臉的圖像,使其看起來更像照片。
5. 小心幸運的分割
在訓練機器學習模型時,通常會將數據集按照一定的比例隨機分割成訓練集和測試集。通常情況下這很好。但是,在處理小數據集時,由于訓練示例的數量較少,存在很高的噪聲風險。
在這種情況下,你可能會意外地得到一個幸運的分割:一個特定的數據集分割,你的模型將在其中執行并很好地推廣到測試集。
而在這種情況下,k-fold交叉驗證是更好的選擇。本質上,你將數據集分割為k個"folds",并為每個k訓練一個新的模型,其中一個folds用于測試集,其余的用于訓練。這控制了你所看到的測試性能不僅僅是由于幸運(或不幸)的分割。
6. 使用遷移學習
如果你使用的是某種標準化的數據格式,比如文本、圖像、視頻或聲音,那么你可以利用其他人之前在這些領域所做的所有工作來進行遷移學習。這就像站在巨人的肩膀上。
當你進行遷移學習時,你采用別人建立的模型(通常,"其他人"是谷歌、Facebook或一所主要大學),并根據你的特殊需要對它們進行微調。
遷移學習之所以有效,是因為大多數與語言、圖像或聲音有關的任務都具有許多共同的特征。對于計算機視覺,它可以檢測特定類型的形狀、顏色或圖案。
最近,研究出來一個高精度的目標檢測原型。通過微調一個MobileNet單鏡頭檢測器,我可以極大地加快開發速度,該檢測器是在谷歌的Open Images v4數據集(約900萬標記圖像!)上訓練的。經過一天的訓練,我能夠使用~1500張帶標簽的圖像生成一個相當健壯的對象檢測模型,測試圖為0.85。
遷移學習是有效的,因為與語言、圖像或聲音有關的大多數任務都有許多共同特征。 對于計算機視覺,它可以是檢測某些類型的形狀、顏色或圖案。
7. 嘗試一組"weak learners"
有時候,你不得不面對這樣一個事實:你沒有足夠的數據來做任何花哨的事情。幸運的是,有許多傳統的機器學習算法可以使用,它們對數據集的大小不那么敏感。
當數據集較小且數據點維度較高時,支持向量機等算法是一個很好的選擇。
不幸的是,這些算法并不總是像***進的方法那樣精確。這就是為什么他們可以被稱為"weak learners",至少與高度參數化的神經網絡相比。
提高性能的一種方法是將這些"weak learners"(這可以是一組支持向量機或決策樹組合起來,以便他們"一起工作"來生成預測。這就是集成學習的全部內容


















