為SEO學習Python 分享7個技巧幫助你做數據分析工作
作為一名SEO專業人士,我的日常任務也在不斷學習。在去年年底開始學習Python之后,我發現自己越來越多地將我所學的東西付諸實踐。
這包括相當簡單的任務,例如比較字數或狀態碼隨時間的變化,以及分析包括內部鏈接和日志文件分析在內的工作。

此外,Python還非常有用:
- 用于處理大型數據集
- 對于通常會使Excel崩潰并需要復雜分析以提取任何有意義的見解的文件。
Python如何幫助技術SEO
Python以多種方式授權SEO專業人員自動化能力通常需要大量的時間來完成重復性的任務。
這意味著我們有更多的時間(和精力)用于重要的戰略工作和無法自動化的優化工作。
它還使我們能夠更有效地處理大量數據,以便做出更多數據驅動的決策,從而為我們的工作和客戶的工作提供有價值的回報。
事實上,有數據公司研究發現,數據驅動型組織獲得客戶的可能性是其他組織的23倍,而留住這些客戶的可能性是6倍。
它對備份你的任何想法或策略也很有幫助,因為你可以用你擁有的數據來量化這些想法或策略,并在此基礎上做出決策,同時在努力實現事情時也有更大的杠桿作用。
將Python添加到SEO工作流
將Python添加到工作流中的最佳方法是:
- 想一想什么是可以自動化的,尤其是在執行乏味的任務時。
- 確定您正在執行或已完成的分析工作中的任何差距。
我發現開始學習的另一個有用的方法是使用你已經訪問過的數據,并且提取有價值的見解使用Python
這就是我如何學會了我將在本文中分享的大部分東西。
學習Python并不是成為一個好的SEO專家的必要條件,但是如果你有興趣了解更多關于Python如何幫助你做好準備的話。
開始需要什么
為了從本文中獲得最佳效果,您需要以下幾點:
- 來自網站的一些數據(例如,對網站的爬網、統計分析或搜索控制臺數據)。
- 一個運行代碼的IDE(集成開發環境),對于入門我推薦Google Colab或Jupyter Notebook .
- 開放的心態。這也許是最重要的一點,不要害怕打破某些東西或犯錯誤,找到問題的原因和解決問題的方法是我們作為SEO專業人士所做的工作的一個重要部分,因此將同樣的心態應用于學習Python有助于減輕任何壓力。
1、善用網絡現有的資源
一個很好的開始是嘗試Python中可用的許多庫中的一些。
有很多要探索的庫,但我發現對SEO相關任務最有用的三個任務是Pandas,Requests和Beautiful Soup。
Pandas
Pandas是一個用于處理表數據的Python庫,它允許在關鍵數據結構是數據幀的情況下進行高級數據操作。
數據幀本質上是Pandas的Excel電子表格但是,它不僅限于Excel的行和字節限制,而且比Excel快得多,因此效率更高。

開始使用Pandas的最佳方法是獲取一個簡單的CSV數據,例如,對您的網站進行爬網,并將其保存在Python中作為一個DataFrame。
一旦你有了這個存儲,你就可以執行許多不同的分析任務,包括聚合、透視和清理數據。
- import pandas as pd
- df = pd.read_csv("/file_name/and_path")
- df.head
requests
下一個庫名為requests,用于在Python中發出HTTP請求。
它使用不同的請求方法(如GET和POST)發出請求,結果存儲在Python中。
其中一個例子是一個簡單的URL GET請求,它將打印出一個頁面的狀態代碼,然后可以使用它來創建一個簡單的決策函數。
- import requests
- #Print HTTP response from page
- response = requests.get('https://www.xxxxxxxx.com')
- print(response)
- #Create decision making function
- if response.status_code == 200:
- print('Success!')
- elif response.status_code == 404:
- print('Not Found.')
您還可以使用不同的請求,例如headers,它顯示關于頁面的有用信息,例如內容類型和緩存響應所需時間的時間限制。
- #Print page header response
- headers = response.headers
- print(headers)
- #Extract item from header response
- response.headers['Content-Type']

此外,還可以模擬特定的用戶代理,例如Googlebot,以便提取該特定bot在抓取頁面時看到的響應。
- headers = {'User-Agent': 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)'}
- ua_response = requests.get('https://www.xxxx.com/', headers=headers)
- print(ua_response)
Beautiful Soup
最后一個庫名為Beautiful Soup,用于從HTML和XML文件 .
它最常用于web抓取,因為它可以將HTML文檔轉換為不同的Python對象。
例如,您可以獲取一個URL,并使用beautifulsoup和Requests庫一起提取頁面的標題。
- #Beautiful Soup
- from bs4 import BeautifulSoup
- import requests
- #Request URL to extract elements from
- url= 'https://www.xxxxxxxxx.com/knowledge/technical-seo-library/'
- req = requests.get(url)
- soup = BeautifulSoup(req.text, "html.parser")
- #Print title from webpage
- title = soup.title
- print(title)
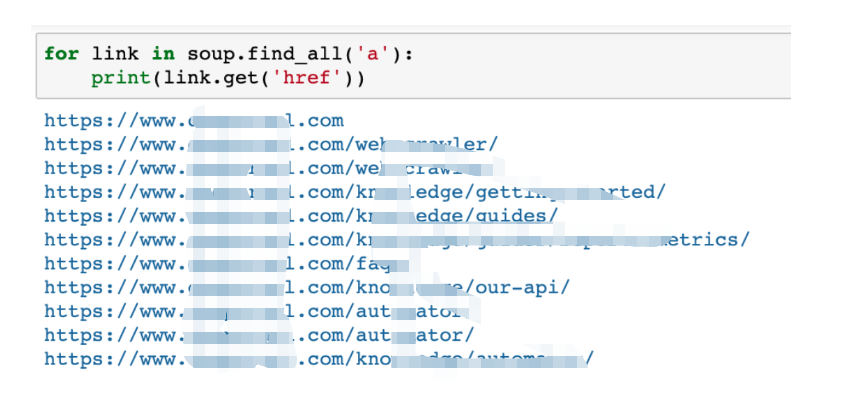
此外,Beautiful Soup允許您從頁面中提取其他元素,例如頁面上找到的所有a href鏈接。
- for link in soup.find_all('a'):
- print(link.get('href'))
2、分段分割頁面
第一個任務涉及到對網站的頁面進行細分,這實際上是根據頁面的URL結構或頁面標題將頁面按類別分組。
首先,使用簡單的正則表達式根據URL將網站分成不同的段:
- segment_definitions = [
- [(r'\/blog\/'), 'Blog'],
- [(r'\/technical-seo-library\/'), 'Technical SEO Library'],
- [(r'\/hangout-library\/'), 'Hangout Library'],
- [(r'\/guides\/'), 'Guides'],
- ]
接下來,我們添加一個小函數,它將遍歷URL列表并為每個URL分配一個類別,然后將這些段添加到包含原始URL列表的DataFrame中的新列中。
- use_segment_definitions = True
- def segment(url):
- if use_segment_definitions == True:
- for segment_definition in segment_definitions:
- if re.findall(segment_definition[0], url):
- return segment_definition[1]
- return 'Other'
- df['segment'] = df['url'].apply(lambda x: get_segment(x))
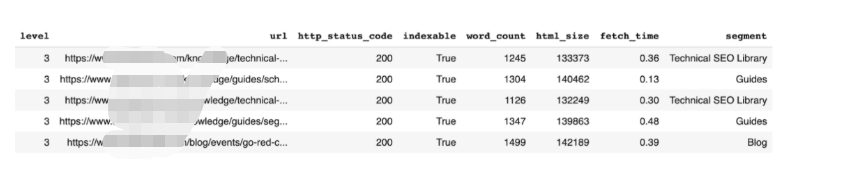
還有一種方法可以使用URL結構在不必手動創建片段的情況下對頁面進行分段。這將獲取包含在主域后面的文件夾,以便對每個URL進行分類。
同樣,這將向我們的DataFrame添加一個新列,其中包含生成的段。
- def get_segment(url):
- slug = re.search(r'https?:\/\/.*?\//?([^\/]*)\/', url)
- if slug:
- return slug.group(1)
- else:
- return 'None'
- # Add a segment column, and make into a category
- df['segment'] = df['url'].apply(lambda x: get_segment(x))
三、重定向相關性
如果我不了解使用Python可能實現的任務,那么我將從未考慮過要完成此任務。
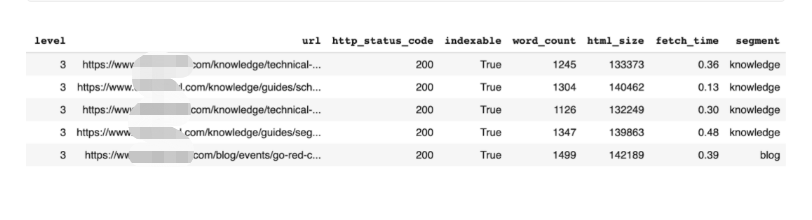
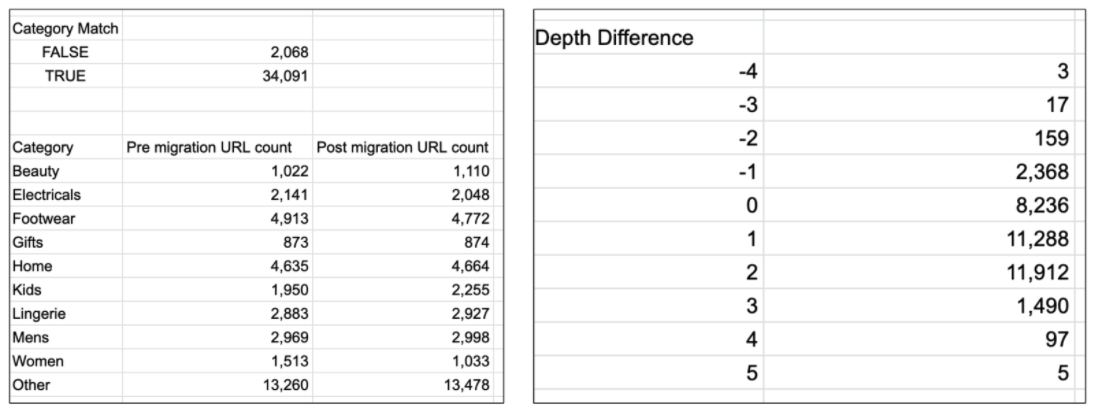
在遷移之后,當重定向到位時,我們希望通過查看每個頁面的類別和深度是否已更改或保持不變來確定重定向映射是否準確。
這涉及到在遷移前和遷移后對站點進行爬網,并根據其URL結構對每個頁面進行分段,如上所述。
在這之后,我使用了一些簡單的比較運算符(它們內置于Python中)來確定每個URL的類別和深度是否發生了更改。
- df['category_match'] = df['old_category'] == (df['redirected_category'])
- df['segment_match'] = df['old_segment'] == (df['redirected_segment'])
- df['depth_match'] = df['old_count'] == (df['redirected_count'])
- df['depth_difference'] = df['old_count'] - (df['redirected_count'])
由于這本質上是一個自動化的腳本,它將在每個URL中運行以確定類別或深度是否已更改,并將結果作為新的數據幀輸出。
新的DataFrame將包含額外的列,如果它們匹配,則顯示True;如果不匹配,則顯示False。
就像在Excel中一樣,Pandas庫使您能夠基于原始數據幀的索引來透視數據。
例如,獲取遷移后有多少URL具有匹配的類別。
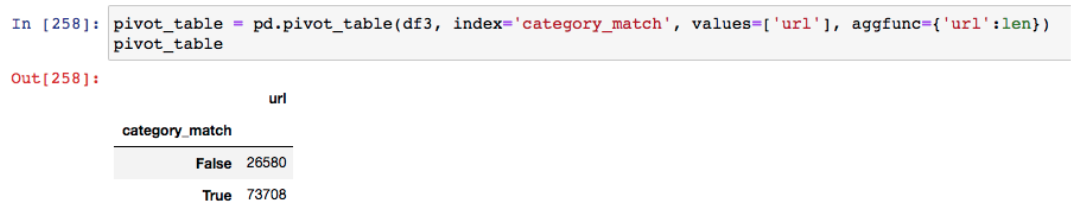
此分析將使您能夠查看已設置的重定向規則,并確定是否存在遷移前后差異較大的類別,這些類別可能需要進一步調查。
4、內部鏈接分析
分析內部鏈接對于確定站點的哪些部分鏈接最多,以及發現改進站點內部鏈接的機會非常重要。
為了執行此分析,我們只需要從web爬網中獲取一些數據列,例如,顯示頁面之間鏈接的任何度量。
再次,我們想分割這些數據,以便確定網站的不同類別并分析它們之間的鏈接。
- internal_linking_pivot['followed_links_in_count'] = (internal_linking_pivot['followed_links_in_count']).apply('{:.1f}'.format)
- internal_linking_pivot['links_in_count'] = (internal_linking_pivot2['links_in_count']).apply('{:.1f}'.format)
- internal_linking_pivot['links_out_count'] = (internal_linking_pivot['links_out_count']).apply('{:.1f}'.format)
- internal_linking_pivot
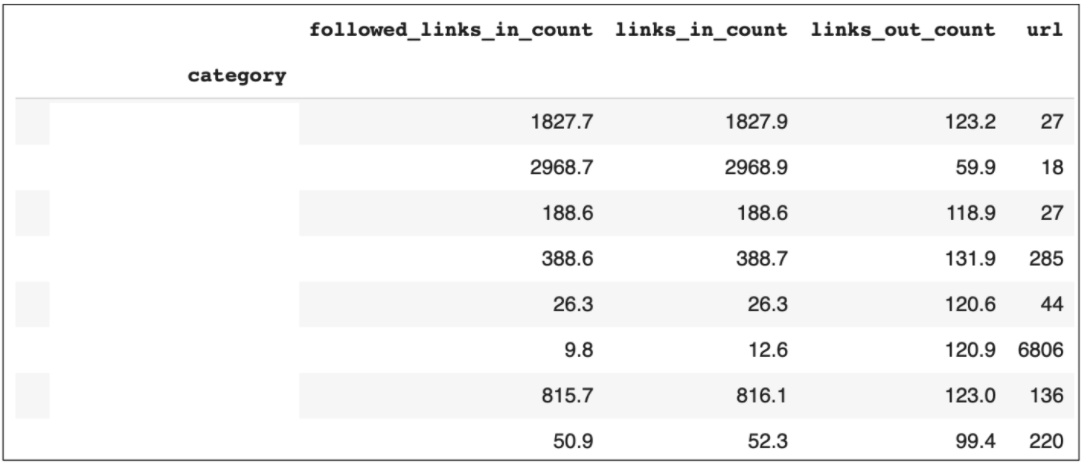
透視表對于這種分析非常有用,因為我們可以透視類別,以便計算每個類別的內部鏈接總數。
Python還允許我們執行數學函數,以便獲得我們所擁有的任何數字數據的計數、求和或平均值。
5、日志文件分析
另一個重要的分析與日志文件,以及我們可以在許多不同工具中收集到的這些數據。
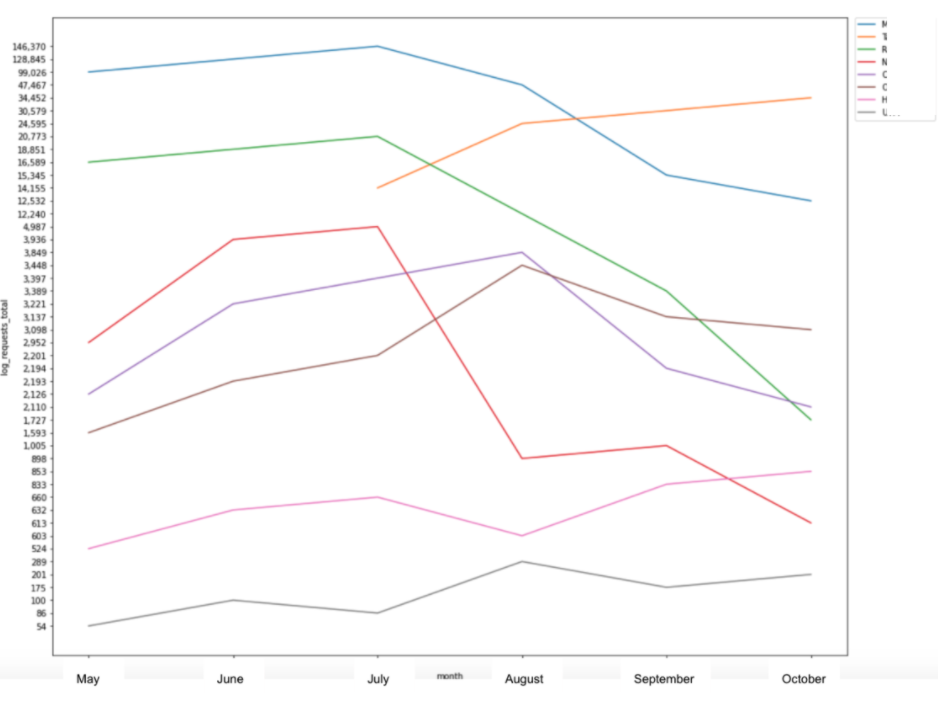
您可以提取一些有用的見解,包括確定Googlebot對站點的哪些區域進行爬網最多,以及監視請求數隨時間的變化。
此外,它們還可以用來查看有多少不可索引或損壞的頁面仍在接收bot點擊,以解決爬網預算的任何潛在問題。
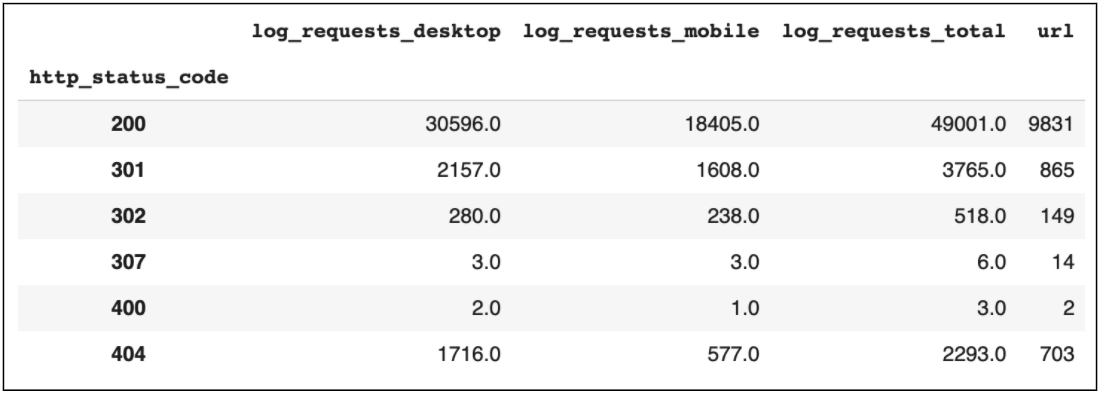
對于每一個類別,最容易使用的就是根據數據段對URL進行統計,或者對每個數據段進行統計。
如果你能夠訪問歷史日志文件數據,也有可能監測谷歌訪問你的網站的變化。
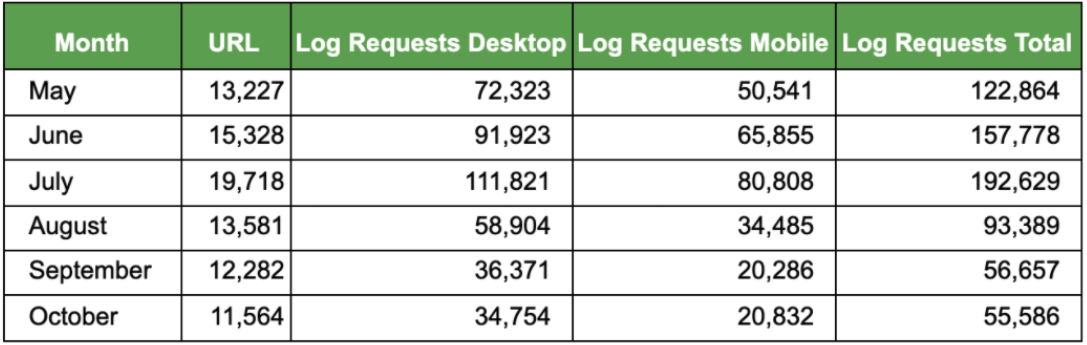
Python中也有很好的可視化庫,如Matplotlib和Seaborn,它們允許您創建條形圖或折線圖,將原始數據繪制成易于跟蹤的圖表,顯示隨時間變化的比較或趨勢。
6、數據合并
使用Pandas庫,還可以基于共享列(例如URL)組合數據幀。
一些有用的SEO合并示例包括將來自web爬網的數據與googleanalytics中收集的轉換數據相結合。
這將使用每個URL進行匹配,并在一個表中顯示來自兩個源的數據。
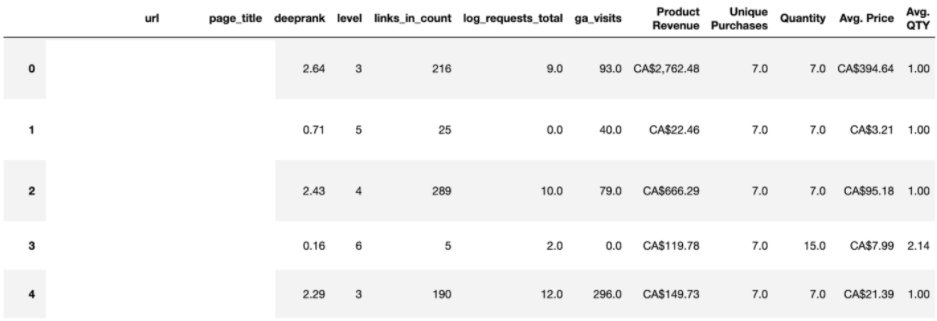
以這種方式合并數據有助于為性能最好的頁面提供更多的見解,同時還可以識別性能不如預期的頁面。
合并類型
在Python中有兩種不同的合并數據的方法,默認的方法是內部合并,合并將發生在左數據幀和右數據幀中的值上。
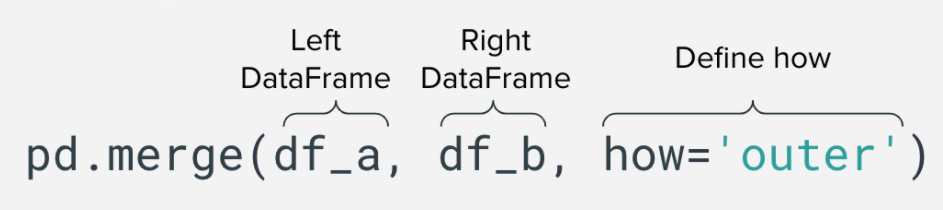
但是,您也可以執行外部合并,它將返回左側數據幀中的所有行,以及右側數據幀中的所有行,并盡可能匹配它們。
以及右合并或左合并將合并所有匹配的行,并保留不匹配的行(如果分別存在于右合并或左合并中)。
7、谷歌趨勢
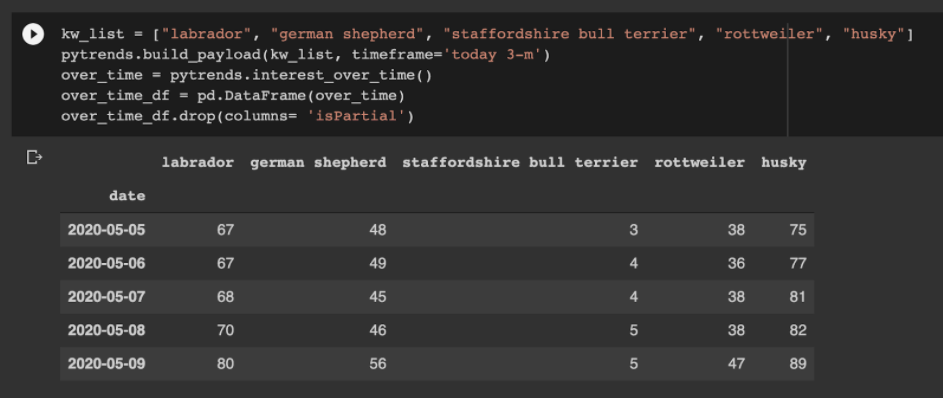
還有一個很棒的圖書館,叫做PyTrends公司,這實際上允許您使用Python按比例收集Google趨勢數據。
有幾種API方法可用于提取不同類型的數據。
一個例子是一次跟蹤最多5個關鍵字的搜索興趣。
另一個有用的方法是返回某個主題的相關查詢,這將顯示一個介于0-100之間的Google Trends分數,以及一個百分比,顯示隨著時間的推移,關鍵字的興趣增加了多少。
這些數據可以很容易地添加到googlesheet文檔中,以便在googledatastudio儀表板中顯示。
總之
這些項目幫助我節省了大量手動分析工作的時間,同時也讓我能夠從我所接觸到的所有數據中發現更多的見解。
我希望這能給你一些SEO項目的靈感,你可以開始學習Python。