Snowflake性能調(diào)優(yōu)的五項優(yōu)秀實踐
譯文【51CTO.com快譯】設(shè)想一下:在沒有任何索引的情況下,以及數(shù)據(jù)庫本身并無調(diào)整選項的情況下,您會如何優(yōu)化Snowflake數(shù)據(jù)倉庫呢?眾所周知,Snowflake的設(shè)計非常簡單,幾乎沒有提供有關(guān)性能調(diào)整的選項。本文為您總結(jié)了提高查詢性能的五項優(yōu)秀實踐。

單獨地查詢工作負(fù)載?
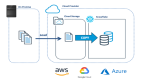
最大化吞吐量、以及最小化Snowflake延遲的首選方法莫過于:對于工作負(fù)載的查詢進(jìn)行分離。下圖說明了一種常見的Snowflake部署設(shè)計模式--分離工作負(fù)載(separation of workloads,請參見https://www.analytics.today/blog/what-is-the-ideal-cloud-datawarehouse-platform)。
與其他數(shù)據(jù)庫系統(tǒng)不同,Snowflake是針對云端構(gòu)建的。它能夠有效地支持無限量的虛擬倉庫,即一些獨立大小的計算群集。它們可以對于公共數(shù)據(jù)的存儲進(jìn)行共享式訪問。這種EPP(Elastic Parallel Processing,彈性并行處理,請參見https://www.analytics.today/blog/four-stages-that-revolutionised-database-architecture)的架構(gòu),可以運行復(fù)雜的數(shù)據(jù)科學(xué)類操作。在針對相同數(shù)據(jù)進(jìn)行ELT加載、以及商業(yè)智能查詢時,該架構(gòu)不會去爭用任何的資源。
在一般情況下,我們往往需要按照部門或團(tuán)隊,來分離不同的工作負(fù)載。例如:通過為每個團(tuán)隊提供屬于其自己的虛擬倉庫,來協(xié)助跟蹤團(tuán)隊的使用情況。而實際上,最合適的做法應(yīng)該是:按工作負(fù)載的類型,而不是用戶組來分離工作負(fù)載。這就意味著:在一個倉庫中,營銷用戶在進(jìn)行商業(yè)智能類查詢的同時,我們可以運行另一個單獨的虛擬倉庫,以支持超快的財務(wù)儀表板式查詢。
曾經(jīng)在一個案子中,我們有位客戶計劃運行十五個超小型的倉庫,以為每個團(tuán)隊提供各自專用的計算資源。然而,在分析了使用狀況之后,我們將其改成了四個更大的虛擬倉庫。此法不但可以讓運行的成本更低,而且能夠在大幅提高性能的前提下,改善用戶的體驗。
最大化Snowflake緩存的使用
下圖展示了Snowflake是如何自動地將數(shù)據(jù)緩存到虛擬倉庫(本地的磁盤緩存)和結(jié)果緩存(Result Cache)中的。
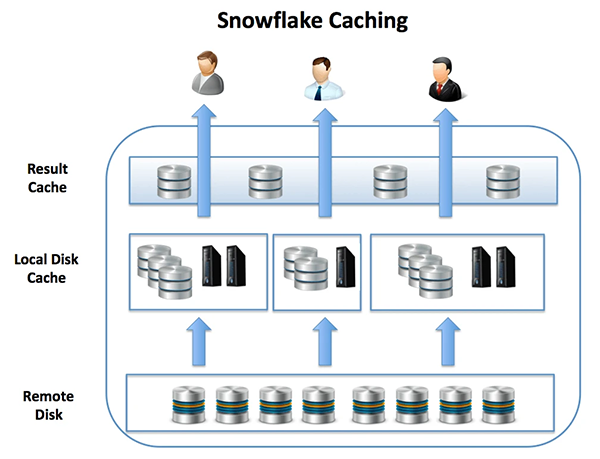
雖然上述是一種自動化行為,但您完全可以通過如下的兩種優(yōu)秀實踐,來最大限度地提高緩存的使用率,并加快查詢的性能。
首先,在分割查詢工作的負(fù)載時,您應(yīng)該能夠讓用戶在同一個虛擬倉庫中查詢到相同的數(shù)據(jù)。如此,那些由某個用戶檢索到緩存里的數(shù)據(jù),也將極有可能被其他人所使用到。
此外,您還應(yīng)該避免在不使用虛擬倉庫時,草草地暫停虛擬倉庫。默認(rèn)情況下,任何倉庫將在10分鐘后自動被掛起,并在有SQL語句需要被執(zhí)行時才自動恢復(fù)。當(dāng)然,您雖然可以將自動掛起設(shè)置為幾秒鐘,以節(jié)省資源。但是應(yīng)該注意的是:在恢復(fù)之后,虛擬倉庫的緩存可能會被清空,這就意味著您將失去原先的緩存性能優(yōu)勢。
最后,請注意:由于結(jié)果緩存是完全獨立于虛擬倉庫的,因此,任何用戶用其帳號執(zhí)行的任何查詢,都將會從結(jié)果緩存中產(chǎn)生完全相同的SQL文本。
縱向擴展(Scale Up),以適應(yīng)大型工作負(fù)載

雖然這并非嚴(yán)格意義上的數(shù)據(jù)庫調(diào)優(yōu),但是利用Snowflake的虛擬倉庫功能,來擴展大型工作負(fù)載是非常重要的。

上述的SQL代碼片段說明了如何調(diào)整倉庫的大小。本例是一個能夠處理巨大工作負(fù)載的32個節(jié)點集群。在測試中,由于Snowflake維護(hù)著一個可用的資源池,因此,它需要花費幾毫秒的時間來實現(xiàn)部署,而在特別繁忙的時段,則可能需要幾分鐘的時間。
在處理完成之后,我們可以簡單地讓群集在300秒(即,五分鐘)之后自動掛起,或者直接在完成任務(wù)后立即暫停群集。如果需要,它可以在另一個查詢需要被執(zhí)行時,自動恢復(fù)。可見,整個過程對于最終用戶的應(yīng)用程序來說都是透明的。
下面的截圖顯示的是倉庫容量不佳時的指標(biāo),它包括了溢出到本地存儲(虛擬倉庫SSD)和遠(yuǎn)程存儲的數(shù)據(jù)量。

在虛擬倉庫中,由于本地存儲始終采用的是快速SSD,因此任何無法在內(nèi)存中完成的大型排序操作,都將不可避免地溢出到本地存儲之中。那么,如果您看到有大量的數(shù)據(jù)溢出到了外部存儲之中,則表明SSD存儲已經(jīng)被用完,而且那些數(shù)據(jù)正在被寫入慢得多的S3或Blob存儲之中。可見,根據(jù)這兩個指標(biāo),我們應(yīng)該考慮調(diào)整到一個更大的、擁有更多內(nèi)存和本地SSD存儲的虛擬倉庫之中。
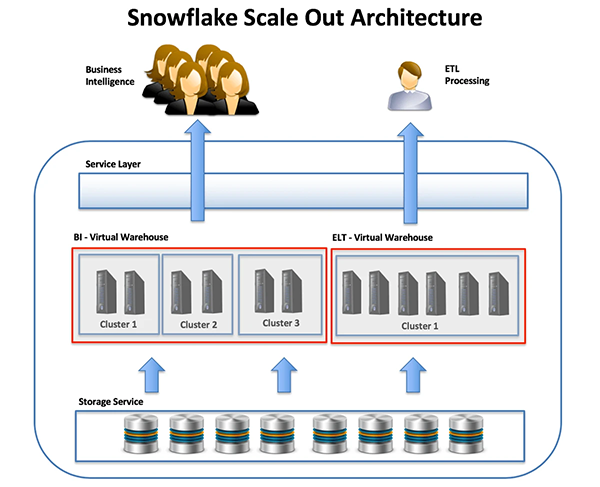
橫向擴展(Scale Out)并發(fā)
與上述縱向擴展不同,橫向擴展技術(shù)被用于部署一些相同大小節(jié)點的集群,以達(dá)到目標(biāo)并發(fā)量,即:增加用戶的數(shù)量,而不是任務(wù)的大小或復(fù)雜性。

上面的SQL片段顯示了在部署針對多個集群的橫向擴展體系結(jié)構(gòu)時,所需要的語句。此法并非部署某個大型的主機群集,而是讓Snowflake按需添加其他相同大小的群集,直至達(dá)到既定的上限。
我們在下圖中所展示的是:將商業(yè)智能虛擬倉庫配置成在其他用戶執(zhí)行查詢的時候,能夠自動將群集添加到現(xiàn)有的配置環(huán)境之中。
顯然,這與ELT的倉庫有著明顯的差異,后者被定義為一個更大的單一化集群,用來處理復(fù)雜任務(wù)中的各種海量數(shù)據(jù)。
這種調(diào)整方法在英國食品配送服務(wù)商Deliveroo那里得到成功應(yīng)用。2017年,根據(jù)最終用戶需要在近20TB的數(shù)據(jù)中,每小時開展7,000多次查詢的需求,他們使用到了Snowflake的自動化橫向擴展資源的方式。
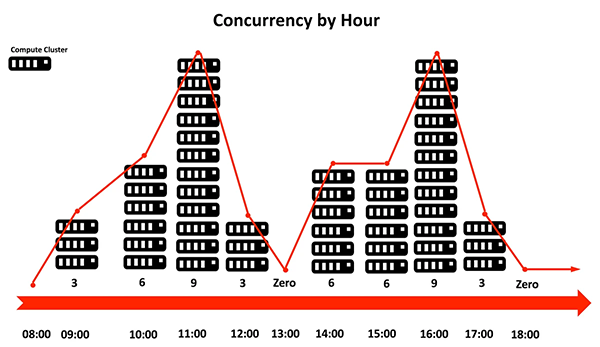
由于并發(fā)用戶的數(shù)量在一天中的不同時段持續(xù)發(fā)生變化,因此該群集會自動暫停,以實現(xiàn)Deliveroo只為實際使用到的計算資源付費。下圖展示了其他群集會根據(jù)用戶的使用量,被自動添加進(jìn)來,以及在不需要的時侯,自動暫停的情況。
使用數(shù)據(jù)聚合來調(diào)整Snowflake
由于使用聚合密鑰(cluster key)可以最大限度地消除分區(qū),進(jìn)而提高查詢的性能,因此對于某些大型數(shù)據(jù)表(通常超過1 TB)而言,設(shè)計人員應(yīng)考慮通過定義聚合密鑰,來最大化查詢的性能。
為了說明使用聚合調(diào)整給Snowflake帶來的性能優(yōu)勢,我們針對TPC(Transaction Processing Council)表的STORE_SALES設(shè)置了一項基準(zhǔn)測試,該表容量有1.3Tb,其中保存了近300億行銷售數(shù)據(jù)。接著,我們針對該表的聚合版本和非聚合版本,運行了相同的查詢,下圖是兩項結(jié)果的對比。

通過在SS_SOLD_DATE_SK列上放置聚合密鑰,并按日期進(jìn)行過濾,整體查詢的運行速度提高了14倍,并且只掃描了近1/30的數(shù)據(jù)。
下面的圖表進(jìn)一步說明了Snowflake聚合的效果,其中涉及到的數(shù)據(jù)是在語句中對WHERE by DATE進(jìn)行過濾后產(chǎn)生的。
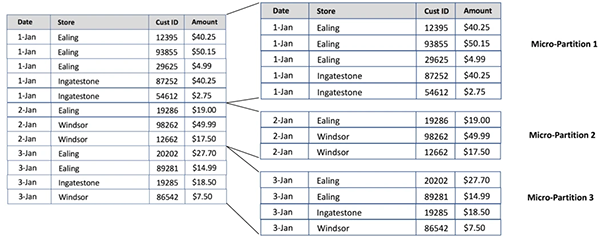
由于數(shù)據(jù)是按照日期進(jìn)行加載的,因此它們往往能夠自然聚集,即同一天的所有數(shù)據(jù)都屬于同一個微分區(qū)。但是,如果執(zhí)行以下SQL語句,Snowflake將會把所有銷售日期都保留在同一個微分區(qū)中。而在需要時,后臺任務(wù)將自動重新聚類數(shù)據(jù),并將用到的計算處理資源按照單獨的項目進(jìn)行計費。

由于Snowflake掌握了每個微分區(qū)中、每列的最小和最大值,因此它可以直接跳過那些與查詢條件完全不匹配的微分區(qū)。為了演示該聚合的性能效果,我們創(chuàng)建了一個包含有6億行和16Gb壓縮數(shù)據(jù)的表。該表由一個唯一性的密鑰(ORDER_KEY)所標(biāo)識,因此我們將其表示為聚類密鑰。

通過執(zhí)行上述查詢,我們在6億行的正好中間找到了目標(biāo)記錄,其返回的時間為88毫秒。如下面的Snowflake Query Profiler截圖所示,速度快的主要原因在于:該查詢只掃描了整個16Gb壓縮數(shù)據(jù)中的1.5Mb,而且除了一個微分區(qū)之外,它幾乎跳過了所有不相關(guān)的內(nèi)容。
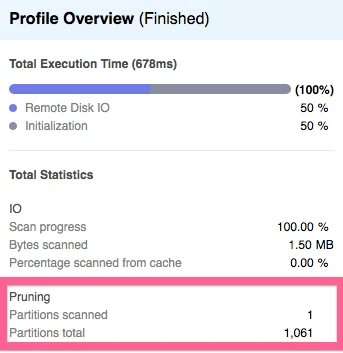
可見,只要使用到了聚類密鑰,Snowflake就能夠跳過多達(dá)99.91%的數(shù)據(jù),進(jìn)而避免了任何與需要維護(hù)傳統(tǒng)索引相關(guān)的性能、以及數(shù)據(jù)管理的開銷。
結(jié)論
綜上所述,雖然可供調(diào)整Snowflake性能的選項寥寥無幾,但是我們可以通過上述優(yōu)秀實踐來最大化查詢的性能、以及吞吐量。
原文標(biāo)題:Snowflake Performance Tuning: Top 5 Best Practices,作者:John Ryan
【51CTO譯稿,合作站點轉(zhuǎn)載請注明原文譯者和出處為51CTO.com】