Snowflake的三大性能調優策略
譯文【51CTO.com快譯】作為一款分析平臺,Snowflake數據倉庫(Data Warehouse)以其超快的查詢性能蜚聲于業界。不過,我們對Snowflake既無法建立索引,又不可捕獲統計信息,更無法管理分區。那么,您該如何優化Snowflake數據庫,以達到更好的查詢性能呢?本文將介紹有關如何將系統調整到最大吞吐量的三個主要方面,即:數據提取、數據轉換和最終用戶的查詢。
影響Snowflake查詢性能的因素
作為技術人員,我們經常需要在對問題不甚了了的情況下,提出并實施解決方案。那么總的說來,我們在分析平臺上的性能問題時,通常會從如下三個方面入手:
i. 數據的加載速度:應具有能夠快速加載大量數據的能力。
ii. 數據的轉換:應具有最大化吞吐量,并將原始數據快速地轉換為適合查詢格式的能力。
iii. 數據的查詢速度:能夠最大程度地減少每次查詢的延遲,并盡快將結果提供給商業智能用戶。
1.Snowflake的數據加載
避免掃描文件
下圖展示了將數據批量加載到Snowflake處的最常見方法。該方法主要是將數據從本地(on-premise)系統傳輸到云端存儲,然后使用COPY命令加載到Snowflake中。
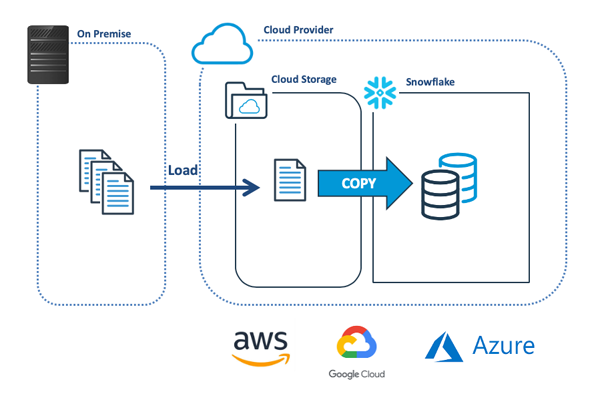
那么在復制數據之前,Snowflake會檢查文件是否已被加載。這是通過限制針對某個特定目錄的COPY,來實現最大化加載性能的第一種、也是最簡單的方法。如下代碼段展示了一系列COPY操作。
SQL
- -- Slowest method: Scan entire stage
- copy into sales_table
- from @landing_data
- pattern='.*[.]csv';
- -- Most Flexible method: Limit within directory
- copy into sales_table
- from @landing_data/sales/transactions/2020/05
- pattern='.*[.]csv';
- -- Fastest method: A named file
- copy into sales_table
- from @landing_data/sales/transactions/2020/05/sales_050.csv;
可見,最快捷的方法是:命名一個特定的文件,并用通配符來體現其靈活性。當然,我們也可以在加載完畢后立即刪除目標文件。
調整虛擬倉庫和文件的大小
下圖展示了:在將大型數據文件加載到Snowflake中時,設計人員往往趨向于擴展出更大的虛擬倉庫,以加快整個加載過程。這是一個常見的誤區。實際上,在這種情況下,給倉庫擴容并不會帶來任何性能上的優勢。
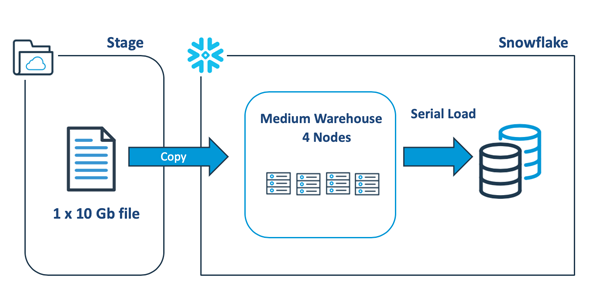
也就是說,上面的COPY語句將打開一個10 Gb的數據文件,并使用某個線程在一個節點上順次加載數據,而其余的服務器則保持為空閑的狀態。通過基準測試,我們發現:通常情況下,加載的速率約為每分鐘9 Gb。我們可以設法提高該速度。
下圖給出了一種更好的方法--將單個10Gb文件分解為100個100 Mb的文件,以充分利用Snowflake的自動化并行處理功能。
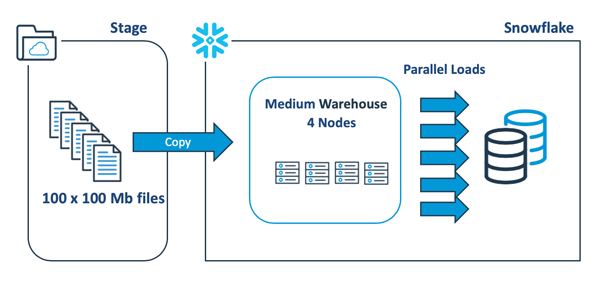
2.Snowflake的轉換性能
延遲與吞吐量
雖然優化SQL是減少時間開銷的最有效方法,但是設計人員通常不太好把握時機。除了減少單個查詢的延遲,最大化吞吐量(即:在盡可能短的時間內實現數據交付的最大化)也是非常重要的。
下圖展示了典型的數據轉換模式,該模式會在虛擬倉庫中執行一系列的批處理作業。只有在前一項任務完成時,后一項任務才會開始:

我們很容易想到的解決方案是:將其擴展到更大的虛擬倉庫中,以更快地完成作業任務。不過,該方案往往會受到硬件資源的極限限制。此外,雖然此舉能夠提高查詢的性能,但是也會造成大量倉庫資源未被充分利用。
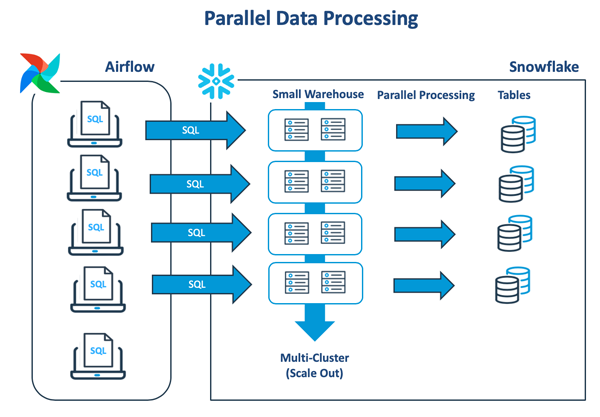
如上圖所示,Apache Airflow可被用于執行與Snowflake的多個獨立連接。其中,每個線程會針對同一虛擬倉庫去執行單個任務。隨著工作量的增加,如果可用資源出現不足的情況,作業任務就會開始排隊。為了分擔負載,我們可以將Snowflake的多集群功能,配置為能夠自動創建另一個相同大小的虛擬倉庫。
完成任務后,上述解決方案還會自動縮小為單個群集,并且能夠在完成了最長的作業后,將群集掛起。目前為止,這是獲取自動擴展與收縮能力的最有效方法。
如下SQL代碼段展示了創建多集群倉庫所需的命令,該倉庫將在60秒鐘的空閑時間后自動掛起。我們通過ECONOMYE擴展策略,來提高吞吐量,并節省單個查詢的等待時間。
SQL
- -- Create a multi-cluster warehouse for batch processing
- create or replace warehouse batch_vwh with
- warehouse_size = SMALL
- min_cluster_count = 1
- max_cluster_count = 10
- scaling_policy. = economy
- auto_suspend. = 60
- initially_suspended = true;
3.調整Snowflake的查詢性能
選擇必要列
與許多其他數據分析平臺類似,Snowflake也用到了列式數據存儲。如下圖所示,該存儲被優化為僅獲取那些特定查詢所需的屬性,而非所有列:
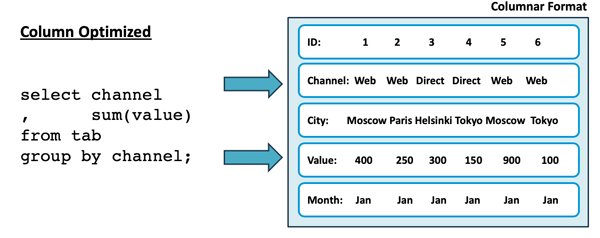
在上圖中,該查詢只是在上百個列的表中獲取了其中的兩列。而傳統的行存儲則需要從磁盤中讀取所有列的數據。顯然,前者的效率要高出許多。
最大化緩存使用率
下圖展示了Snowflake內部架構的重要組成部分,它能夠在虛擬倉庫和云端服務層之間緩存數據。
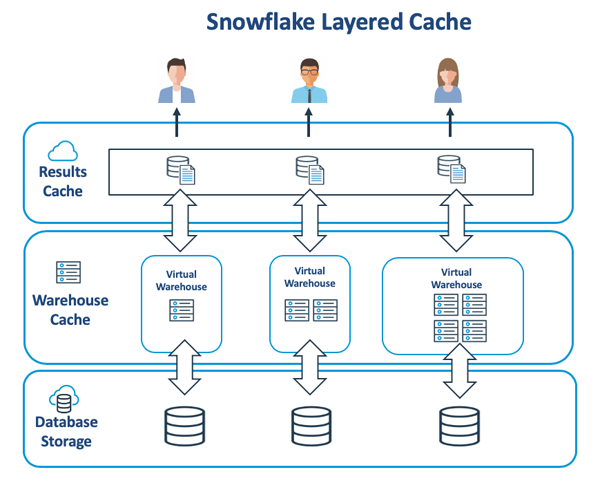
商業智能儀表盤可以通過對同一查詢的重新執行,以刷新并顯示被更改以后的數據值。Snowflake通過返回最近24小時內查詢到的結果緩存(Results Cache)中的內容,來實現對此類查詢的自動化調優。
雖然數據也會被緩存到快速SSD(固態硬盤)上的虛擬倉庫中,但是不同于上述提到的結果緩存,虛擬倉庫是基于最近、最少使用原則,來保存原始數據,因此此類數據很可能已經過期了。不過,我們雖然無法直接調整虛擬倉庫中的緩存內容,但是可以通過如下步驟進行優化:
- 獲取所需的屬性:避免在查詢中使用SELECT *,畢竟這會將所有數據的屬性,從數據庫存儲(Database Storage)中全量獲取到倉庫緩存(Warehouse Cache)中。此舉不僅速度緩慢,而且還可能導致那些不需要的數據也被填充到了倉庫緩存中。
- 擴容:我們雖然應該避免通過擴容的方式,來應對特定的查詢,但是我們需要通過調整倉庫本身的大小,以提高整體的查詢性能。那些新增的服務器既可以分散突發任務的負擔,又能夠有效地增加倉庫緩存的大小。
- 考慮數據集群:對于大小超過TB的數據表而言,請考慮通過創建集群鍵(cluster key,請參見--https://www.analytics.today/blog/tuning-snowflake-performance-with-clustering)的方式,最大程度地消除分區(partition)。此舉既可以提高單個查詢的性能,又可以返回較少的微分區(micro-partitions),從而充分地使用到倉庫緩存。
SQL
- -- Identify potential performance issues
- select query_id as query_id
- , round(bytes_scanned/1024/1024) as mb_scanned
- , total_elapsed_time / 1000 as elapsed_seconds
- , (partitions_scanned /
- nullif(partitions_total,0)) * 100 as pct_table_scan
- , percent_scanned_from_cache * 100 as pct_from cache
- , bytes_spilled_to_local_storage as spill_to_local
- , bytes_spilled_to_remote_storage as spill_to_remote
- from snowflake.account_usage.query_history
- where (bytes_spilled_to_local_storage > 1024 * 1024 or
- bytes_spilled_to_remote_storage > 1024 * 1024 or
- percentage_scanned_from_cache < 0.1)
- and elapsed_seconds > 120
- and bytes_scanned > 1024 * 1024
- order by elapsed_seconds desc;
上面的SQL代碼段可以幫助我們識別出,那些運行超過了2分鐘,并已經掃描了1兆數據量的查詢性能問題。如下兩個方面特別值得我們的關注:
- 表掃描:在大型數據表中,如果PCT_TABLE_SCAN的值比較高,或MB_SCANNED的量比較大,則都表明查詢的選擇性比較差。因此,我們需要檢查查詢中的WHERE子句,并適當地考慮使用集群鍵。
- 溢出:SPILL_TO_LOCAL或SPILL_TO_REMOTE中的任何值,都表明系統在小型虛擬倉庫上進行了大型的操作。因此,我們需要考慮將查詢移至更大的倉庫中,或適當地對現有的倉庫進行擴容。
總結
業界關于Snowflake的一個常見誤解是:直接擴容出更大的倉庫,是提高查詢性能的唯一方案。但這實際上并不一定是絕好的策略。我們需要厘清問題到底是發生在獲取數據環節、還是數據轉換部分、亦或最終用戶的查詢中。畢竟設計出可擴容的大型倉庫,要比單純的查詢調整,更適合提高數據庫的查詢性能。
原標題:Top 3 Snowflake Performance Tuning Tactics ,作者: John Ryan
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】