21個必知的機器學習開源工具,涵蓋5大領域
- 本文將介紹21個你可能沒使用過的機器學習開源工具。
- 每個開源工具都為數(shù)據(jù)科學家處理數(shù)據(jù)庫提供了不同角度。
- 本文將重點介紹五種機器學習的工具——面向非程序員的工具(Ludwig、Orange、KNIME)、模型部署(CoreML、Tensorflow.js)、大數(shù)據(jù)(Hadoop、Spark)、計算機視覺(SimpleCV)、NLP(StanfordNLP)、音頻和強化學習(OpenAI Gym)。
你肯定已經(jīng)知道一些知名的開源工具,如R、Python、Jupyter筆記本等。但除此之外,還有一個世界——一個在雷達下機器學習工具存在的世界。它們雖沒有那些知名的開源工具出色,但卻可以幫助用戶解決許多機器學習的任務。
開源機器學習工具可分為以下5類:
1. 面向非程序員的開源機器學習工具
對于沒有編程背景和技術背景的人來說,機器學習似乎很復雜。這是一個廣闊的領域,可以想象,初次接觸機器學習有多令人害怕。一個沒有編程經(jīng)驗的人能在機器學習領域獲得成功嗎?
事實證明,能獲得成功!以下三種工具可以幫助非程序員跨越技術鴻溝,進入聲名鵲起的機器學習世界:
- Uber Ludwig:Uber’s Ludwig是一個建立在TensorFlow上的工具箱。Ludwig允許用戶訓練和測試深度學習模型,而不需要編寫代碼。用戶需要提供的只是一個包含數(shù)據(jù)的CSV文件,一個用作輸入的列表,以及一個用作輸出的列表——而剩下工作將由Ludwig來完成。它對實驗非常有用,因為用戶只需耗費很少的時間和精力,就能構建復雜的模型。并且用戶可以對其進行調(diào)整和處理之后再決定是否要將其運用在代碼中。
- KNIME:KNIME可供用戶使用拖放界面創(chuàng)建整個數(shù)據(jù)科學工作流。用戶可以基本實現(xiàn)從功能工程到功能選擇的所有功能,甚至可以通過這種方式將預測機器學習模型納入工作流程中。這種可視化執(zhí)行整個模型工作流的方法非常直觀,并且在處理復雜的問題時非常有用。
- Orange:用戶不必知道如何編寫代碼以使用orange來挖掘數(shù)據(jù)、處理數(shù)字以及由此得出自己的見解。相反,用戶可執(zhí)行基本可視化、數(shù)據(jù)操作、轉換和數(shù)據(jù)挖掘等任務。由于Orange的易用性及其添加多個附加組件以補充其功能的能力,該工具最近在學生和教師中十分流行。
還有許多更有趣、免費的開源軟件可以提供很好的機器學習功能,而無需編寫(大量)代碼。
此外,一些付費服務也可以考慮,如Google AutoML、 Azure Studio、 Deep Cognition和 Data Robot.
2. 旨在部署模型的開源機器學習工具
部署機器學習模型是一個十分重要但最容易被忽視的任務,用戶應該加以注意。它肯定會出現(xiàn)在面試中,所以用戶需很好地了解這個話題。
以下四種工具可以使用戶更易將其項目運用到現(xiàn)實設備上。
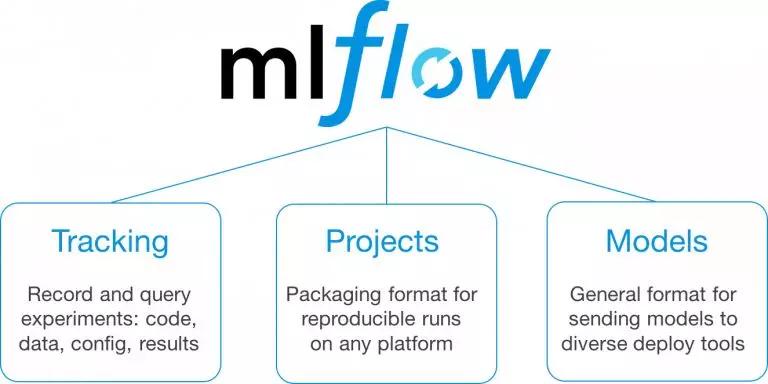
- MLFlow: MLFlow旨在與機器學習庫或算法配合使用,并管理包括實驗、再驗和機器學習模型部署在內(nèi)的整個生命周期。目前,MLFlow在Alpha中有3個部分——跟蹤、項目和模型。
- Apple’s CoreML: CoreMLl是一個十分受歡迎的工具,它可將機器學習模型內(nèi)置到用戶的iOS/Apple Watch/Apple TV/MacOS的應用程序中。CoreML的閃光點在于用戶無需對神經(jīng)網(wǎng)絡或機器學習有廣泛的了解,最終達到雙贏的結果!
- TensorFlow Lite: TensorFlow Lite是一套幫助開發(fā)人員在移動設備(Android和iOS)和物聯(lián)網(wǎng)設備上運行TensorFlow模型的工具,旨在方便開發(fā)人員在網(wǎng)絡“邊緣”的設備上進行機器學習,而不是從服務器來回發(fā)送數(shù)據(jù)。
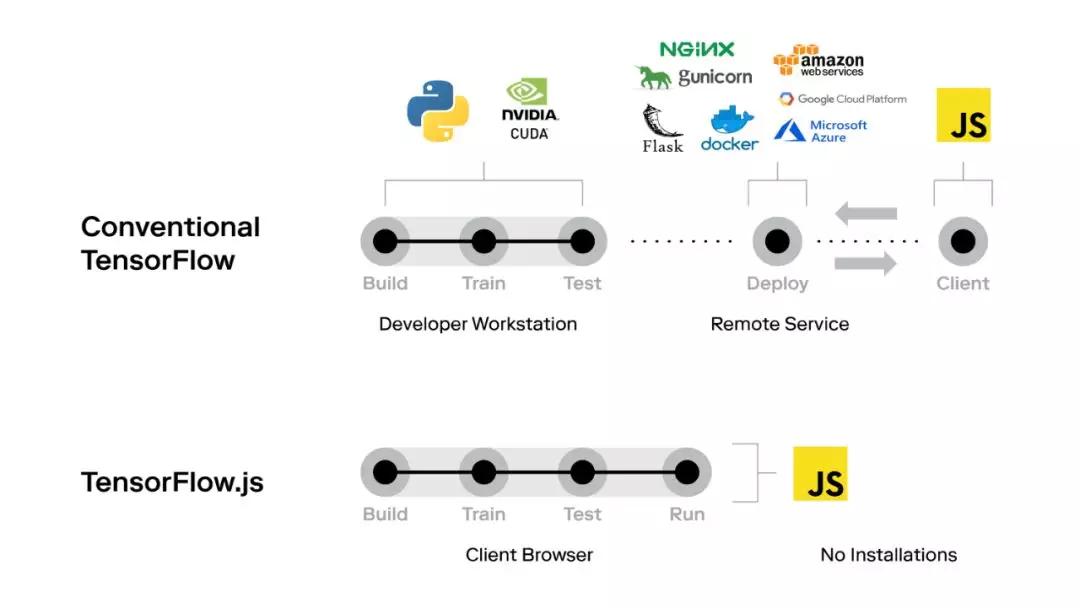
- TensorFlow.js :TensorFlow.js是用戶在網(wǎng)上部署機器學習模型的首選。這是一個開放源碼庫,供用戶在瀏覽器中構建和處理機器學習模型。它可為GPU加速,還自動支持WebGL。用戶可以導入現(xiàn)有的預培訓模型,也可以在瀏覽器上重新處理整個現(xiàn)有機器學習模型!
3. 大數(shù)據(jù)開源機器學習工具
大數(shù)據(jù)是一個研究如何進行分析、如何系統(tǒng)地從數(shù)據(jù)集中提取信息或以其他方式處理傳統(tǒng)數(shù)據(jù)處理軟件無法處理的太大或太復雜的數(shù)據(jù)集的領域。想象一下,每天處理數(shù)百萬條推特進行情緒分析。這感覺像是一項艱巨的任務,不是嗎?
放寬心!以下三種工具可以幫助用戶處理大數(shù)據(jù)。
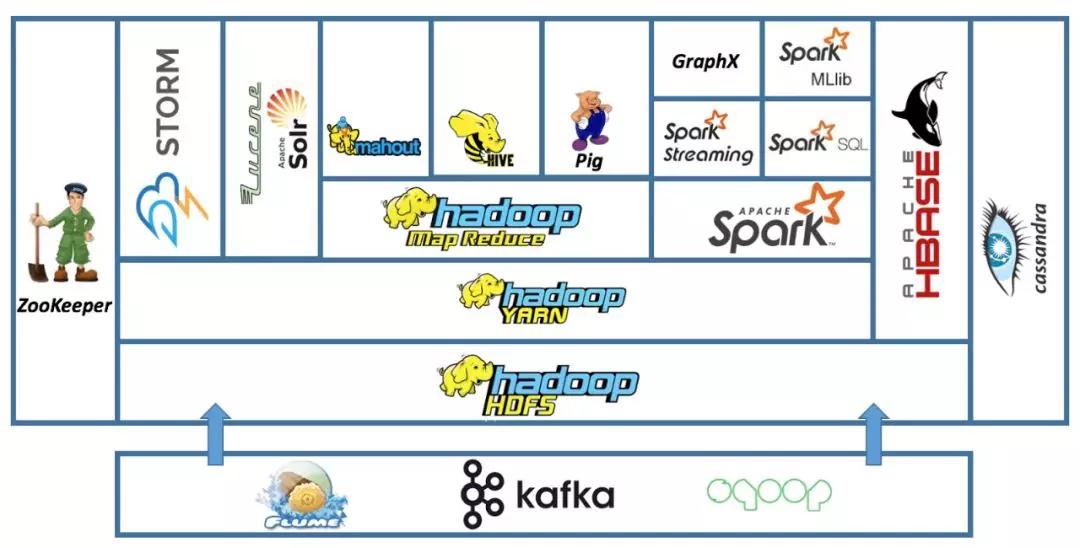
- Hadoop: Hadoop是處理大數(shù)據(jù)最杰出也是最相關的工具之一。Hadoop允許用戶使用簡單的編程模型在計算機集群之間對大型數(shù)據(jù)集進行分布式處理。它旨在對單個服務器到數(shù)千臺機器,每臺機器都提供本地計算和存儲。
- Spark: Apache spark被認為在大數(shù)據(jù)應用程序方面是Hadoop的進階版。Apache spark的關鍵在于填補了Apache Hadoop在數(shù)據(jù)處理方面的空白。有趣的是,Spark可以同時處理批量數(shù)據(jù)和實時數(shù)據(jù)。
- Neo4j: 在處理大數(shù)據(jù)相關問題方面,Hadoop可能不是絕佳的選擇。例如,用戶需要處理大量的網(wǎng)絡數(shù)據(jù)或圖形相關問題(如社交網(wǎng)絡或人口統(tǒng)計模式等)時。而圖形數(shù)據(jù)庫(Neo4j)則是最佳選擇。
4. 用于計算機視覺、自然語言處理和音頻的開源機器學習工具
- SimpleCV: 參與任何計算機視覺項目都必須使用OpenCV。但你有沒有考慮過SimpleCV?SimpleCV可供用戶訪問幾個高性能的計算機視覺庫,如OpenCV——而不必首先了解位深度、文件格式、顏色空間、緩沖區(qū)管理、特征值以及矩陣與位圖存儲。計算機視覺讓項目變得更容易上手。

- Tesseract OCR: 你是否曾使用過一些有創(chuàng)意的應用程序,可以使用智能手機的攝像頭掃描文件或購物賬單,或者只需拍張支票就可以將錢存入銀行賬戶?所有這些應用程序使用的都是OCR,即光學字符識別軟件。Tesseract就是這樣的OCR引擎,可以識別100多種語言,也可以加以訓練識別其他語言。
- Detectron: Detectron是Facebook旗下人工智能研究公司的軟件系統(tǒng),它采用了包括Mask R-CNN在內(nèi)最先進的目標檢測算法。Detectron由Python語言編寫完成,由Caffe2深度學習框架提供支持。

- StanfordNLP: StanfordNLP是Python的自然語言分析包。它的閃光點在于其支持70多種人類語言!StanfordNLP還包含可以在以下程序步驟中使用的工具:
—將包含人類語言文本的字符串轉換為句子和單詞列表
—生成單詞的基本形式、詞類和形態(tài)特征
—邏輯句法結構依賴分析

- BERT as a Service: 所有的自然語言處理愛好者都應該聽說過谷歌的開創(chuàng)性自然語言處理架構——BERT,但可能還沒有用過。Bert-as-a-service將BERT作為句子編碼器,并通過ZeroMQ將其作為服務器,從而使用戶能夠僅用兩行代碼將句子映射為固定長度的表示形式。
- Google Magenta: Google Magenta提供了處理源數(shù)據(jù)(主要是音樂和圖像)的實用程序,該數(shù)據(jù)庫使用這些源數(shù)據(jù)處理機器學習模型,并最終從這些模型中生成新內(nèi)容。
- LibROSA: LibROSA是用于音樂和音頻分析的Python語言包。它提供了構建音樂信息檢索系統(tǒng)所必需的構建塊。當用戶在處理諸如語音到文本深度學習等的應用時, LibROSA廣泛應用于在音頻信號預處理程序環(huán)節(jié)。
5. 旨在進行強化學習的開源工具
強化學習(RL) 是機器學習的新話題,其目標是培養(yǎng)能夠與環(huán)境互動并解決復雜任務的智能經(jīng)紀人,實現(xiàn)機器人、自動駕駛汽車等的實際應用。
強化學習領域的快速發(fā)展得益于讓智能經(jīng)紀人玩一些游戲,如經(jīng)典的Atari console games、傳統(tǒng)的圍棋游戲,或者讓智能經(jīng)紀人玩電子游戲,如Dota 2 或 Starcraft 2,所有這些游戲都為智能經(jīng)紀人提供了具有挑戰(zhàn)性的環(huán)境。在這個環(huán)境中,新的算法可以安全、可重復的方式測試想法。以下列舉了4個最有利于強化學習的培養(yǎng)環(huán)境:
- Google Research Football: Google Research Football Environment是一個全新的強化學習環(huán)境,其中,智能經(jīng)紀人旨在掌握世界上最流行的足球運動。這種環(huán)境能讓用戶更好地訓練強化學習智能經(jīng)紀人。
- OpenAI Gym: Gym是開發(fā)和比較強化學習算法的工具包,可支持教學經(jīng)紀人從走路到玩乒乓球或彈球之類的游戲。從以下動圖中可以看到一個正在學習走路的教學經(jīng)紀人。

- Unity ML Agents: The Unity Machine Learning Agents Toolkit(ML-Agents)是開源設備的插件,使游戲和模擬游戲能為智能經(jīng)紀人訓練提供有效環(huán)境。通過簡單易用的Python API,用戶可以使用強化學習、模仿學習、神經(jīng)進化或其他機器學習方法來訓練智能經(jīng)紀人。

- Project Malmo: Malmo平臺是一個建立在Minecraft之上的復雜人工智能實驗平臺,旨在支持人工智能領域的基礎研究,由微軟開發(fā)。
當用戶進行數(shù)據(jù)科學和人工智能相關項目時,開放源碼是一種可行的方法。本文只是介紹了冰山一角,仍有許多工具可用于處理各種各樣的任務,使數(shù)據(jù)科學家的項目生活更為簡便。數(shù)據(jù)科學家只需知道何處尋找開放源碼即可。