













阿里大牛詳解分布式系統,大型網站分布式系統實戰解析
分布式系統
分布式系統從當初的CORBA 到EJB,Web和SOA,從集群到現在的NoSQL 云計算和大數據Hadoop等分布式系統,橫向水平擴展Scala out/in是分布式系統設計的一個特點,可靠性、容錯性是兩個質量指標。
什么是分布式系統?
- 一大批服務器組成一個集合,對于用戶來說仍然是一個整體連貫系統。
- A. Tanenbaum定義:分布式網絡的計算機中的組件之間協調動作是通過消息進行通訊。
- G. Coulouris定義:當你知道有一臺電腦崩潰,但是你的軟件運行從來不會停止。
- Leslie Lamport定義:分布式系統是這樣系統:旨在支持應用程序和服務的開發,可以利用物理架構 由多個自治的處理元素,不共享主內存,但通過網絡發送異步消息合作。
- 與分層應用區別:分層的應用程序(例如,3層)是 劃分應用程序邏輯,是一種邏輯分層,而不是物理,而分布式系統DS是物理分層,和實際部署有關。
與傳統集中式系統相比:
集中式系統是一種Scale out/in,縱向擴展,要么向上升級服務器到中大型機,要么升級多核,增加CPU核數,集中式縱向擴展適合計算聚合度比較高的數據,而分布式適合計算松散數據,非結構化或半結構化數據。無論采取哪種擴展伸縮方案,需要根據業務數據特點而定。
任何分布式系統總是需要完成兩個任務:計算和存儲。計算和存儲分離是分布式系統的重要特征。而通常在集中式或單機系統中,這兩者是可能結合在一起,比如通過一個SQL語句實現查詢后排序,查詢是從存儲中獲得數據,排序是屬于計算,因此這個SQL語句實際是將計算和存儲耦合在一起。在應對大數據或大并發的情況下,這種方便的捆綁帶來性能問題,而分布式計算和分布式存儲雖然帶來復雜性,但是也為系統的處理能力打開了上升拓展的空間。
分布式系統特點:
- 并發性:共享資源,采取ACID或Base原則,見:CAP定理。
- 分布式系統設計遵循CAP定理, CAP是:Consistency(一致性),Availability(可用性), 和 Partition tolerance(分區容錯性) 可靠性 簡稱,CAP定理認為,CAP三種之中,只能同時滿足其中兩種。
- 可擴展性Scalable是重要特點,通過擴展能夠獲得高性能 高吞吐量 低延遲Latency。
- 可靠性/可用性:故障發現和處理以及恢復 容錯處理。在一個正常運作系統中存在一個時間比例的條件。 如果一個用戶不能訪問系統比例增大,它被認為是不可用。可用性公式:
- Availability = uptime / (uptime + downtime)
- 容錯failover是指一個系統在錯誤發生的情況下,仍然一切運行正常。表示這個系統是寬容錯誤的。
- 消息處理: 具體產品有:RabbitMQ ZeroMQ Netty等等。
- 異構性: 不同操作系統 硬件 程序語言 開發者,中間件是一種解決方案。
- 安全性:授權認證 SSO單點登錄 Oauth等等。
定位命令:
- 標識資源 URLs
- 命名服務Naming services
- 定位尋找Lookup
- 主要見SOA中的服務查找。如Zookeeper實現服務查找。
透明性:
- 訪問透明度: 使用相同的操作本地和遠程資源
- 位置透明:訪問資源無需知道其物理或網絡位置
- 并發透明度:多個流程可以同時運行訪問使用共享資源,當不能干擾堵塞 它們的處理流程
- 復制透明性: 資源的多個實例可以被用來復制以提高可靠性和性能,但無需由用戶編制專門的應用程序來實現。
- 故障透明度:出現軟件硬件故障時,使用戶和應用方案能繼續完成他們的任務不受影響。
- 移動透明度:允許在 系統存在移動的資源和客戶。
- 性能透明度:允許系統重新配置以 提高性能負荷變化
- 縮放透明度:在應用程序結構沒有變化的情況下能夠在規模上擴展或伸縮系統,以提高吞吐量處理能力。
分布式系統的挑戰
分布式系統是難于理解、設計、構建 和管理的,他們將比單個機器成倍還要多的變量引入到設計中,使應用程序的根源問題更難發現。SLA(服務水平協議)是衡量停機和/或性能下降的標準,大多數現代應用程序有一個期望的彈性SLA水平,通常按"9"的數量增加(如,每月99.9或99.99%可用性)。每個額外的9變得越來越難實現。
讓事情更加復雜的是,我們越來越常見地看到:分布式系統的故障表現為間歇性錯誤或性能下降(俗稱的限電)。這些失敗模式耗費更多時間來診斷。例如,Joyent經營一些分布式系統作為其云計算基礎設施的一部分。在這樣一個系統中,包括高可用性、分布式的鍵/值存儲,Joyent最近經歷了瞬態應用程序超時。對于大多數用戶系統運行正常,其反應延遲也是在SLA范圍內。然而,有百分之5 - 10的請求超出了一個預定義的程序超時。這樣的失敗問題并沒有重現在開發或測試環境中,他們經常會"消失"幾分鐘到幾小時。排除這個故障的根本是需要大量數據存儲的系統分析。
這些系統包括:數據存儲API(node . js),RDBMS(關系數據庫管理系統)和由系統內部使用(PostgreSQL)以及操作系統和終端用戶應用程序依賴于的鍵/值系統。最終,導致過度的根本問題是在應用程序語義鎖定,但確定之前需要相當大的數據收集和相關性工作,包括工程師耗費大量工作時間以及學習不同領域的專業知識。
分布式系統由兩個物理因素的限制:
- 節點的數量(能夠增加所需的存儲和計算能力)
- 節點之間的距離(信息的傳送距離,最好以光速)
這兩個約束導致下面值得挑戰的情況發生:
- 獨立節點隨著數目的增加發生故障的概率增加(減少可用的和管理成本增加)
- 獨立節點隨著數目增加可能會增加節點之間的通信的消耗(隨著規模的增大性能降低)
- 地理距離的增加提高遙遠的節點之間的通信延遲(減少某些操作的性能)
如何架構分布式系統
適用于分布式系統架構的最常見的一個術語是SOA(面向服務架構)。SOA可以避免不愉快的CORBA(公共對象請求代理體系結構),通過WS - *標準,一套松散耦合的Web服務完成獨立的小功能,并且彼此獨立,他們是一個有彈性的分布式系統的基礎。對比上一代,服務是新流程,他們是正確的抽象層次系統中的離散功能。
構建面向服務架構的第一步是確定每個函數功能如何構成整體業務目標,將這些業務映射到離散的服務,且具有獨立的斷層邊界、擴展性和數據負載量。確定為每個服務時,您必須考慮下列事項:
- 地理。系統是全球還是地區單獨運行?
- 數據隔離。這個系統提供一個單個或多租戶模型?
- SLAs。可用性 延遲 吞吐量 一致性和冗余性都必須定義。
- 安全。IAAA (身份identity, 驗證authentication, 授權authorization, 和 審核audit), 數據的保密性和隱私性都必須考慮
- 可用性跟蹤。了解系統的使用是每天系統的日常運作,如容量規劃。也可能用于執行計費系統的使用和/或治理(配額/速度限制)。
- 部署和配置管理。系統是如何部署更新?
分布式系統的模型抽象
- 系統模型(異步/同步)
- 失效模型(崩潰故障,分區)
- 一致性模型(強,最終)
通常,我們最熟悉的模式(例如,一個分布式系統上實現共享內存抽象)是太昂貴了。一個分布式系統越弱勢越能保證其中元素有更大的行動自由,從而煥發潛在的更大的性能- 但它也可能導致很難管理。這就需要我們有極大智慧,不能以犧牲性能換來管理的方便性。因此,試圖將分布式系統看成一個統一的單一系統的思維會阻礙分布式系統的擴展。
分布式系統遵循CAP定律,在高一致性 高可用性和分區容錯性之間三選二:
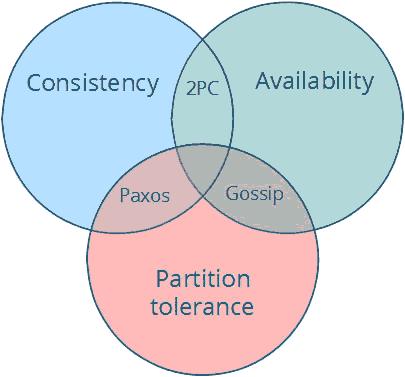
- CA (consistency高一致性 + availability高可用性). 使用2pc 兩階段事務提交來保證。其缺點無法實現分區容錯性,一旦某個操作失敗,整個系統就出錯,無法容忍(水至清則無魚)。
- CP (consistency高一致性 + partition tolerance分區容錯性). 使用Paxos來保證,可用性降低。
- AP (availability高可用性 + partition tolerance分區容錯性). 使用Gossip等實現最終一致性,如Dynamo.
- 如何正確理解CAP理論?
分布式系統的設計技巧:分區和復制
對于一個數據集有兩種設計方式:
- 分區:它可以被分割在多個節點,以允許更多的并行處理。有更好的性能,但是容錯能力低。
- 復制:它也可以被復制或緩存在不同的節點上,以減少在客戶端和服務器之間的距離,更強的容錯能力,但是復制消耗性能。關鍵是復制數據之間的一致性。弱一致性提供更低的延遲和更高的可用性。
分布式系統的設計技巧:時鐘和順序
分布式系統針對計算和存儲的策略是不同的,對于數據的存儲主要是分區和復制,而對于計算主要是保證事件的順序,因為分布式計算任務是由事件驅動的,比如Storm等等。那么事件的順序代表了業務邏輯的順序,事件有時是樹形嵌套事件,可靠性就是必須保證一個樹形集合所有事件都得到網站執行是一個事務原子的。



















